Schema Evolution in Merge Operations and Operational Metrics in Delta Lake
Delta Lake 0.6.0 introduces schema evolution and performance improvements in merge and operational metrics in table history
by Tathagata Das and Denny Lee
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Try this notebook to reproduce the steps outlined below
We recently announced the release of Delta Lake 0.6.0, which introduces schema evolution and performance improvements in merge and operational metrics in table history. The key features in this release are:
- Support for schema evolution in merge operations (#170) - You can now automatically evolve the schema of the table with the merge operation. This is useful in scenarios where you want to upsert change data into a table and the schema of the data changes over time. Instead of detecting and applying schema changes before upserting, merge can simultaneously evolve the schema and upsert the changes.
- Improved merge performance with automatic repartitioning (#349) - When merging into partitioned tables, you can choose to automatically repartition the data by the partition columns before writing to the table. In cases where the merge operation on a partitioned table is slow because it generates too many small files (#345), enabling automatic repartition (spark.delta.merge.repartitionBeforeWrite) can improve performance.
- Improved performance when there is no insert clause (#342) - You can now get better performance in a merge operation if it does not have any insert clause.
- Operation metrics in DESCRIBE HISTORY (#312) - You can now see operation metrics (for example, number of files and rows changed) for all writes, updates, and deletes on a Delta table in the table history.
- Support for reading Delta tables from any file system (#347) - You can now read Delta tables on any storage system with a Hadoop FileSystem implementation. However, writing to Delta tables still requires configuring a LogStore implementation that gives the necessary guarantees on the storage system.
Schema Evolution in Merge Operations
As noted in earlier releases of Delta Lake, Delta Lake includes the ability to execute merge operations to simplify your insert/update/delete operations in a single atomic operation as well as include the ability to enforce and evolve your schema (more details can also be found in this tech talk). With the release of Delta Lake 0.6.0, you can now evolve your schema within a merge operation.
Let’s showcase this by using a timely example; you can find the original code sample in this notebook. We’ll start with a small subset of the 2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE dataset which we have made available in /databricks-datasets. This is a dataset commonly used by researchers and analysts to gain some insight of the number of cases of COVID-19 throughout the world. One of the issues with the data is that the schema changes over time.
For example, the files representing COVID-19 cases from March 1st - March 21st (as of April 30th, 2020) have following schema:
But the files from March 22nd onwards (as of April 30th) had additional columns including FIPS, Admin2, Active, and Combined_Key.
In our sample code, we renamed some of the columns (e.g. Long_ -> Longitude, Province/State -> Province_State, etc.) as they are semantically the same. Instead of evolving the table schema, we simply renamed the columns.
If the key concern was just merging the schemas together, we could use Delta Lake’s schema evolution feature using the “mergeSchema” option in DataFrame.write(), as shown in the following statement.
But what happens if you need to update an existing value and merge the schema at the same time? With Delta Lake 0.6.0, this can be achieved with schema evolution for merge operations. To visualize this, let’s start by reviewing the old_data which is one row.
Next let’s simulate an update entry that follows the schema of new_data
and union simulated_update and new_data with a total of 40 rows.
We set the following parameter to configure your environment for automatic schema evolution:
Now we can run a single atomic operation to update the values (from 3/21/2020) as well as merge together the new schema with the following statement.
Let’s review the Delta Lake table with the following statement:
Operational Metrics
You can further dive into the operational metrics by looking at the Delta Lake Table History (operationMetrics column) in the Spark UI by running the following statement:
Below is an abbreviated output from the preceding command.
You will notice two versions of the table, one for the old schema and another version for the new schema. When reviewing the operational metrics below, it notes that there were 39 rows inserted and 1 row updated.
You can understand more about the details behind these operational metrics by going to the SQL tab within the Spark UI.
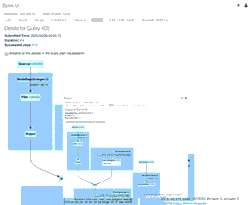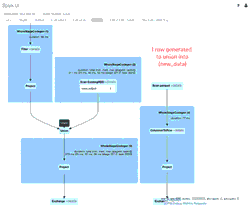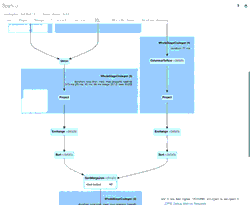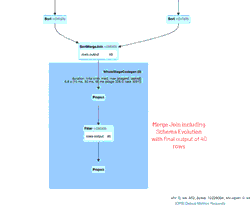
The animated GIF calls out the main components of the Spark UI for your review.
- 39 initial rows from one file (for 4/11/2020 with the new schema) that created the initial new_data DataFrame
- 1 simulated update row generated that would union with the new_data DataFrame
- 1 row from the one file (for 3/21/2020 with the old schema) that created the old_data DataFrame.
- A SortMergeJoin used to join the two DataFrames together to be persisted in our Delta Lake table.
To dive further into how to interpret these operational metrics, check out the Diving into Delta Lake Part 3: How do DELETE, UPDATE, and MERGE work tech talk.

Get Started with Delta Lake 0.6.0
Try out Delta Lake with the preceding code snippets on your Apache Spark 2.4.5 (or greater) instance (on Databricks, try this with DBR 6.6+). Delta Lake makes your data lakes more reliable (whether you create a new one or migrate an existing data lake). To learn more, refer to https://delta.io/, and join the Delta Lake community via Slack and Google Group. You can track all the upcoming releases and planned features in GitHub milestones. You can also try out Managed Delta Lake on Databricks with a free account.
Credits
We want to thank the following contributors for updates, doc changes, and contributions in Delta Lake 0.6.0: Ali Afroozeh, Andrew Fogarty, Anurag870, Burak Yavuz, Erik LaBianca, Gengliang Wang, IonutBoicuAms, Jakub Orłowski, Jose Torres, KevinKarlBob, Michael Armbrust, Pranav Anand, Rahul Govind, Rahul Mahadev, Shixiong Zhu, Steve Suh, Tathagata Das, Timothy Zhang, Tom van Bussel, Wesley Hoffman, Xiao Li, chet, Eugene Koifman, Herman van Hovell, hongdd, lswyyy, lys0716, Mahmoud Mahdi, Maryann Xue
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.