Introducing Koalas 1.0
by Hyukjin Kwon, Takuya Ueshin and Xiao Li
Koalas was first introduced last year to provide data scientists using pandas with a way to scale their existing big data workloads by running them on Apache SparkTM without significantly modifying their code. Today at Spark + AI Summit 2020, we announced the release of Koalas 1.0. It now implements the most commonly used pandas APIs, with 80% coverage of all the pandas APIs. In addition, Koalas supports Apache Spark 3.0, Python 3.8, Spark accessor, new type hints, and better in-place operations. This blog post covers the notable new features of this 1.0 release, ongoing development, and current status.
If you are new to Koalas and would like to learn more about how to use it, please read the launch blog post, Koalas: Easy Transition from pandas to Apache Spark.
Rapid growth and development
The open-source Koalas project has evolved considerably. At launch, the pandas API coverage in Koalas was around 10%–20%. With heavy development from the community over many, frequent releases, the pandas API coverage ramped up very quickly and is now close to 80% in Koalas 1.0.
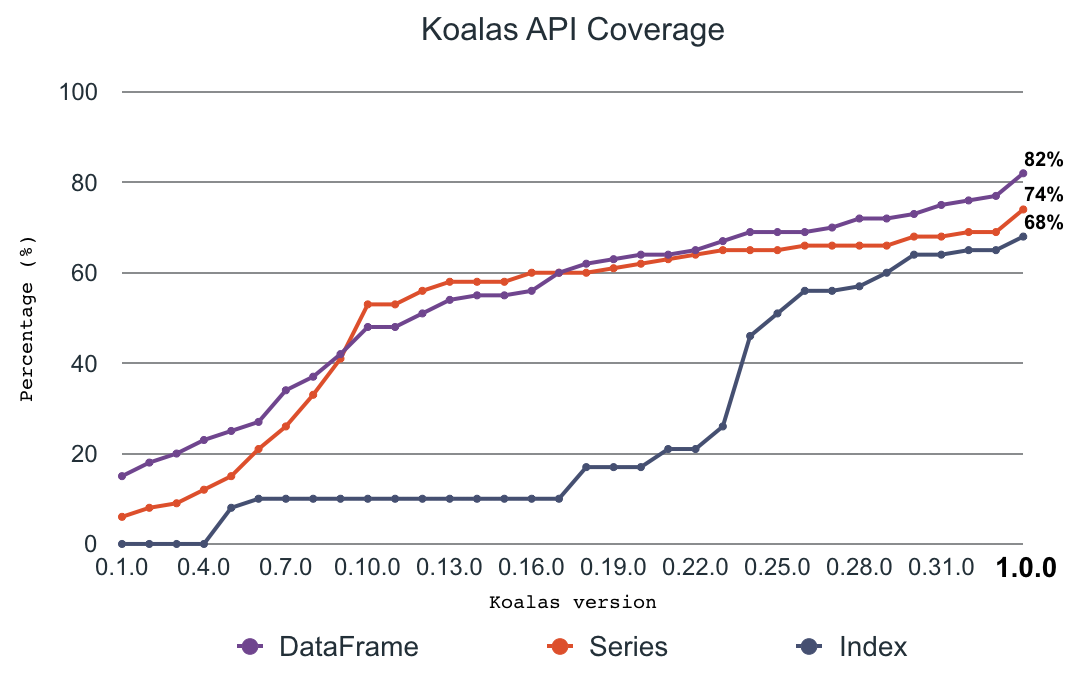
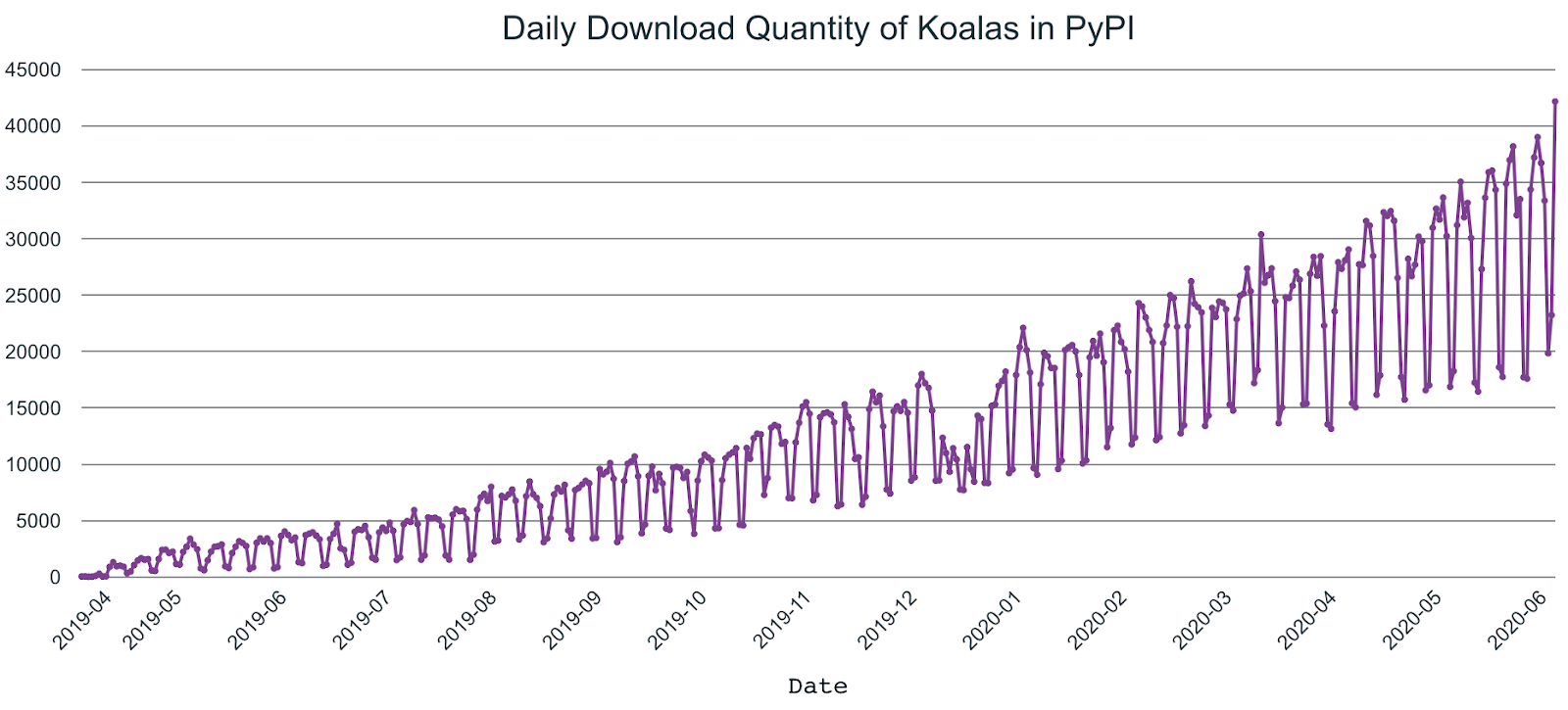
In addition, the number of Koalas users has increased rapidly since the initial announcement, comprising one-fifth of PySpark downloads, roughly suggesting that 20% of PySpark users use Koalas.
Better pandas API coverage
Koalas implements almost all widely used APIs and features in pandas, such as plotting, grouping, windowing, I/O, and transformation.
In addition, Koalas APIs such as transform_batch and apply_batch can directly leverage pandas APIs, enabling almost all pandas workloads to be converted into Koalas workloads with minimal changes in Koalas 1.0.0.
Apache Spark 3.0, Python 3.8 and pandas 1.0
Koalas 1.0.0 supports Apache Spark 3.0. Koalas users will be able to switch their Spark version with near-zero changes. Apache Spark has more than 3,400 fixes in Spark 3.0, and Koalas shares the fixes in many components. Please see the blog, Introducing Apache Spark 3.0.
With Apache Spark 3.0, Koalas supports the latest Python 3.8 version that has many significant improvements, which you can see in the Python 3.8.0 release notes. Koalas exposes many APIs similar to pandas in order to execute native Python code against a DataFrame, which would benefit from the Python 3.8 support. In addition, Koalas aggressively leverages the Python type hints that are under heavy development in Python. Some type hinting features in Koalas will likely only be allowed with newer Python versions.
One of the goals in Koalas 1.0.0 is to track the latest pandas releases and cover most of the APIs in pandas 1.0. API coverage has been measured and improved in addition to keeping up to date with API changes and deprecation. Koalas also supports the latest pandas version as a Koalas dependency, so users of the latest pandas version can easily jump into Koalas.
Spark accessor
Spark accessor was introduced from Koalas 1.0.0 in order for Koalas users to leverage existing PySpark APIs more easily. For example, you can apply the PySpark functions as below:
You can even convert a Koalas series to a PySpark column and use it with Series.spark.transform.
PySpark features such as caching the DataFrame are also available under Spark accessor:
Faster performance
Many Koalas APIs depend on pandas UDFs under the hood. New pandas UDFs are introduced in Apache Spark 3.0 that Koalas internally uses to speed up performance, such as in DataFrame.apply(func) and DataFrame.apply_batch(func).
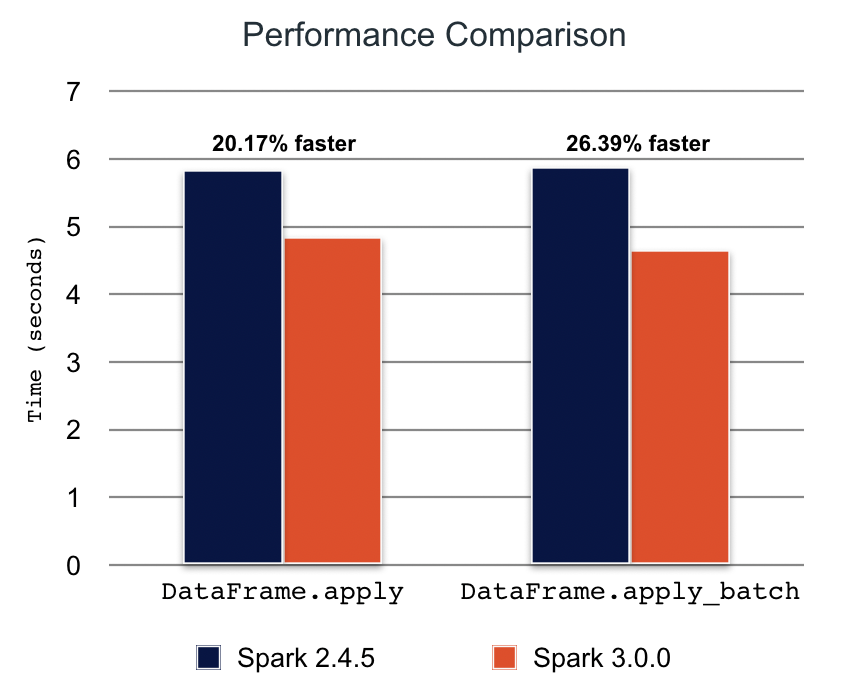
In Koalas 1.0.0 with Spark 3.0.0, we’ve seen 20%–25% faster performance in benchmarks.
Better type hint support
Most of Koalas APIs that execute Python native functions actually take and output pandas instances. Previously, it was necessary to use Koalas instances for the return type hints, which look slightly awkward.
In Koalas 1.0.0 with Python 3.7 and later, you can also use pandas instances in the return type:
In addition, a new type hinting has been experimentally introduced in order to allow users to specify column names in the type hints:
Users can also experimentally use pandas dtype instances and column indexes for the return type hint:
Broader plotting support
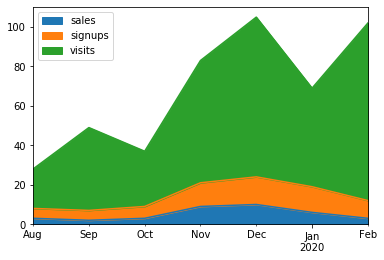
The API coverage in Koalas’ plotting capabilities has reached 90% in Koalas 1.0.0. Visualization can now easily be done in Koalas, the same way it is done in pandas. For example, the same API call used in pandas to draw area charts can also be used against a Koalas DataFrame.
The example draws an area chart and shows the trend in the number of sales, sign-ups, and visits over time.
Wider support of in-place update
In Koalas 1.0.0, in-place updates in Series are applied into the DataFrame naturally as if the DataFrame is fully mutable. Previously, several cases of the in-place updates in Series were not reflected in the DataFrame.
For example, the in-place updates in Series.fillna updates its DataFrame as well.
In addition, now it is possible to use the accessors to update the Series and reflect the changes into the DataFrame as below.
Better support of missing values, NaN and NA
There are several subtle differences in handling missing data between PySpark and pandas. For example, missing data is often represented as None in PySpark but NaN in Pandas. In addition, pandas has introduced new experimental NAvalues, which are currently not supported very well in Koalas.
Most other cases are now fixed, and Koalas is under heavy development to incrementally address this issue. For example, Series.fillna now handles NaN properly in Koalas 1.0.0.
Get started with Koalas 1.0
There are many ways to install Koalas, such as with package managers like pip or conda. The instructions are available in the Koalas installation guide. For Databricks Runtime users, you can follow these steps to install a library on Databricks.
Please also refer to the Getting Started section in the Koalas documentation, which contains many useful resources.
If you have been holding off on trying Koalas, now is the time. Koalas brings a more mature implementation of pandas that’s designed to help you scale your work on Spark. Large data sets should never be a blocker to data science projects, and Koalas helps make it easy to get started.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.