How to accelerate your ETL pipelines from 18 hours to as fast as 5 minutes with Azure Databricks
by Adam Wasserman and Clinton Ford
Azure Databricks enables organizations to migrate on-premises ETL pipelines to the cloud to dramatically accelerate performance and increase reliability. If you are using SQL Server Integration Services (SSIS) today, there are a number of ways to migrate and run your existing pipelines on Microsoft Azure.
Explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
The challenges with on-premises ETL pipelines
In speaking with customers, some of the most common challenges we hear about with regard to on-premises ETL pipelines are reliability, performance and flexibility. ETL pipelines can be slow due to a number of factors, such as CPU, network, and disk performance as well as the available on-premises compute cluster capacity. In addition, data formats change and new business requirements come up that break existing ETL pipelines, underscoring lack of flexibility. On-premises ETL pipelines can slow growth and efficiency for the following reasons:
- Cost - On-premises infrastructure is riddled with tangible and intangible costs related to hardware, maintenance, and human capital.
- Scalability - Data volume and velocity are rapidly growing and ETL pipelines need to scale upward and outward to meet the computing, processing and storage requirements.
- Data Integrations - Data must be combined from various financial, marketing, and operational sources to help direct your business investments and activities.
- Reliability - On-premises big data ETL pipelines can fail for many reasons. The most common issues are changes to data source connections, failure of a cluster node, loss of a disk in a storage array, power interruption, increased network latency, temporary loss of connectivity, authentication issues and changes to ETL code or logic.
How Azure Databricks helps
Migrating ETL pipelines to the cloud provides significant benefits in each of these areas. Let's look at how Azure Databricks specifically addresses each of these issues.
- Lower Cost - Only pay for the resources you use. No need to purchase physical hardware far in advance or pay for specialized hardware that you only rarely use.
- Optimized Autoscaling - Cloud-based ETL pipelines that use Azure Databricks can scale automatically as data volume and velocity increase.
- Native Integrations - Ingest all of your data into a reliable data lake using 90+ native connectors.
- Reliability - Leverage Azure compute, storage, networking, security, authentication and logging services to minimize downtime and avoid interruptions.
How Bond Brand Loyalty accelerated time to value with Azure Databricks
Bond Brand Loyalty provides customer experience and loyalty solutions for some of the world's most influential and valuable brands across a wide variety of industry verticals, from banking and auto manufacturing, to entertainment and retail. For Bond, protecting customer data is a top priority, so security and encryption are always top of mind. Bond is constantly innovating to accelerate and optimize their solutions and the client experience. Bond provides customers with regular reporting to help them see their brand performance. They needed to improve reporting speed from weeks to hours.
Bond wanted to augment its reporting with data from third-party sources. Due to the size of the data, it did not make sense to store the information in a transactional database. The Bond team investigated the concept of moving to a data lake architecture with Delta Lake to support advanced analytics. The team began to gather data from different sources, landing it in the data lake and staging it through each phase of data processing. Using Azure Databricks, Bond was able to leverage that rich data, serving up more powerful, near real-time reports to customers. Instead of the typical pre-canned reports that took a month to produce, Bond is now able to provide more flexible reporting every 4 hours.
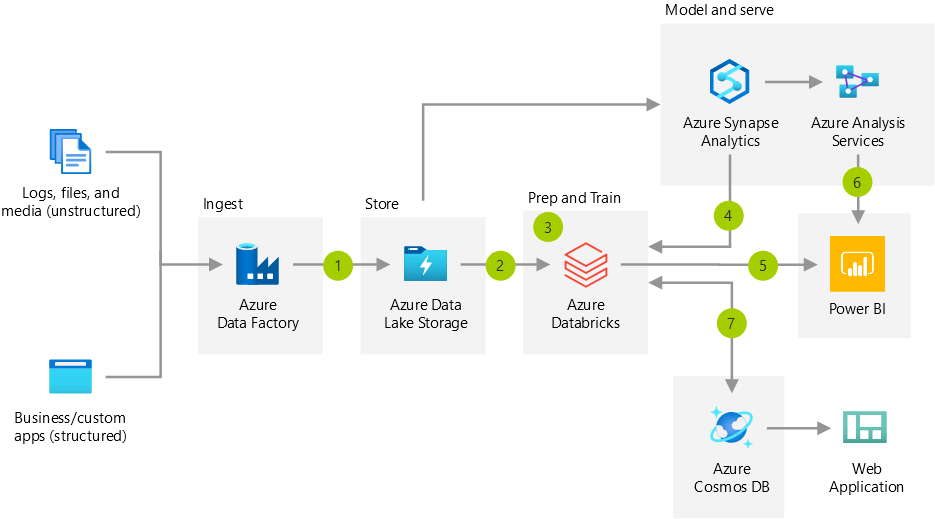
Going from monthly reports to fresh reports every 4 hours has enabled efficiencies. Bond used to have warehouses, reporting cubes, and disaster recovery to support the old world. Now, with Azure Databricks, Bond has observed that its data pipelines and reporting are easier to maintain. ETL pipelines that previously took 18 hours to run on-premises with SSIS can now be run in as little as 5 minutes. As a byproduct of the transition to a modern, simplified architecture, Bond was able to reduce pipeline creation activities from two weeks down to about two days.
With Azure Databricks and Delta Lake, Bond now has the ability to innovate faster. The company is augmenting its data with Machine Learning (ML) predictions, to orchestrate campaigns, and enable deeper campaign personalization so clients can provide more relevant offers to their customers. Thanks to Azure Databricks, Bond can easily scale its data processing and analytics to support rapid business growth.
Get Started by migrating SSIS pipelines to the cloud
Customers have successfully migrated a wide variety of on-premises ETL software tools to Azure. Since many Azure customers use SQL Server Integration Services (SSIS) for their on-premises ETL pipelines, let's take a deeper look at how to migrate an SSIS pipeline to Azure.
There are several options and the one you choose will depend on a few factors:
- Complexity of the pipeline (number and types of input and destination data sources)
- Connectivity to the source and destination data stores
- Number and type of applications dependent on the source data store
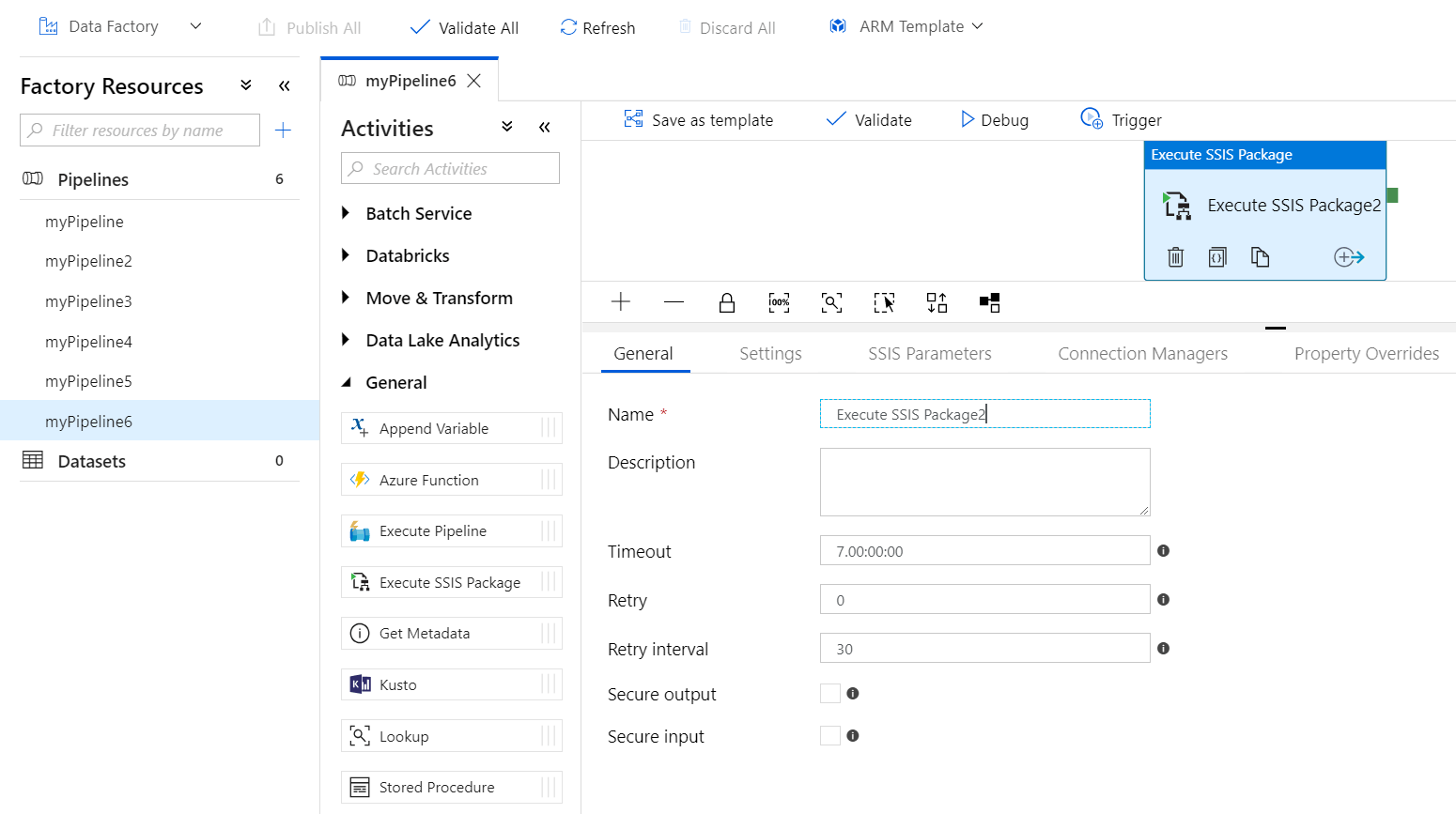
Execute SSIS Packages on Azure Data Factory
This is a great transitionary option for data teams that prefer a phased approach to migrating data pipelines to Azure Databricks. Leveraging Azure Data Factory, you can run your SSIS packages in Azure.
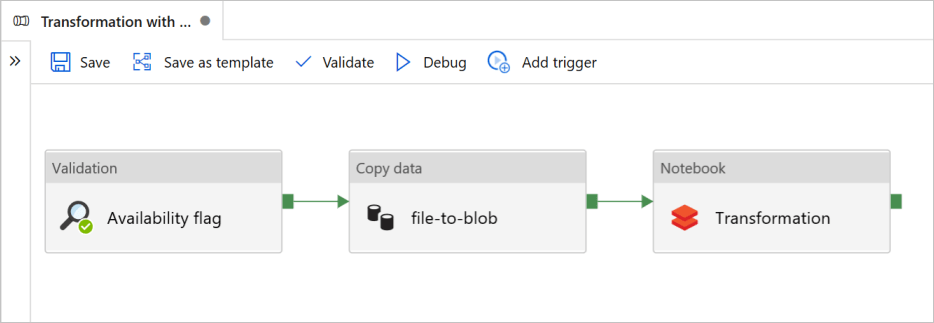
Modernize ETL Pipelines with Azure Databricks Notebooks
Azure Databricks enables you to accelerate your ETL pipelines by parallelizing operations over scalable compute clusters. This option is best if the volume, velocity, and variety of data you expect to process with your ETL pipeline is expected to rapidly grow over time. You can leverage your skills with SQL with Databricks notebooks to query your data lake with Delta Lake.
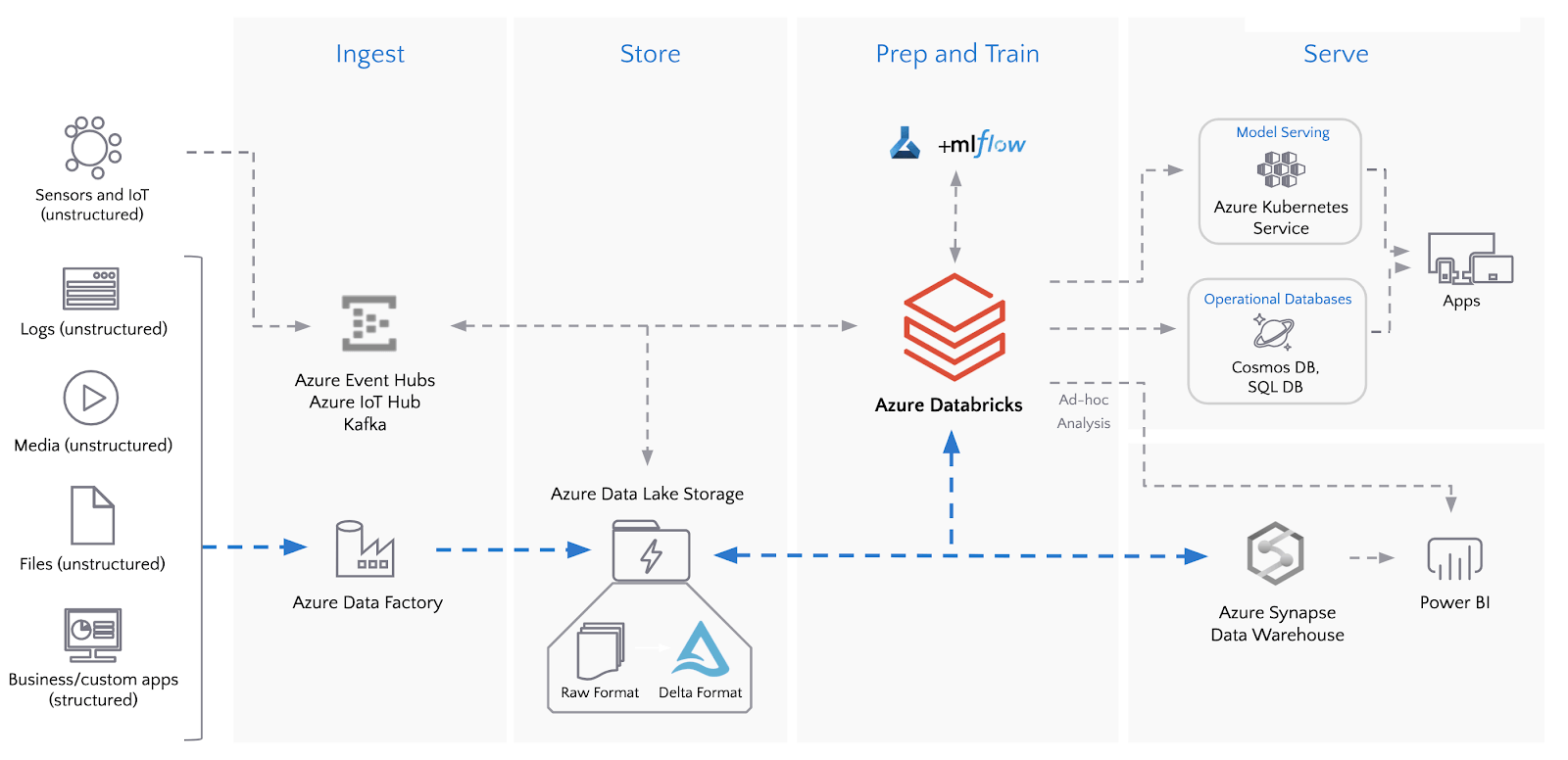
Making the Switch from SSIS to Azure Databricks
When considering a migration of your ETL pipeline to Azure Databricks and Azure Data Factory, start your discovery, planning and road map by considering the following:
- Data Volume - how much data to process in each batch?
- Data Velocity - how often should you run your jobs?
- Data Variety - structured vs. unstructured data?

Next, ensure that your target data architecture leverages Delta Lake for scalability and flexibility supporting varying ETL workloads.
Migrate and validate your ETL pipelines
When you are ready to begin your ETL migration, start by migrating your SSIS logic to Databricks notebooks where you can interactively run and test data transformations and movement. Once the notebooks are executing properly, create data pipelines in Azure Data Factory to automate your ETL jobs. Finally, validate the outcome of the migration from SSIS to Databricks by reviewing the data in your destination data lake, check logs for errors, then schedule ETL jobs and setup notifications.
Migrating your ETL processes and workloads to the cloud helps you accelerate results, lower expenses and increase reliability. Learn more about Modern Data Engineering with Azure Databricks and Using SQL to Query Your Data Lake with Delta Lake, see this ADF blog post and this ADF tutorial. If you are ready to experience acceleration of your ETL pipelines, schedule a demo.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.