In previous blogs Diving Into Delta Lake: Unpacking The Transaction Log and Diving Into Delta Lake: Schema Enforcement & Evolution, we described how the Delta Lake transaction log works and the internals of schema enforcement and evolution. Delta Lake supports DML (data manipulation language) commands including DELETE, UPDATE, and MERGE. These commands simplify change data capture (CDC), audit and governance, and GDPR/CCPA workflows, among others. In this post, we will demonstrate how to use each of these DML commands, describe what Delta Lake is doing behind the scenes when you run one, and offer some performance tuning tips for each one. More specifically:
A quick primer on the Delta Lake ACID Transaction Log
Understand the fundamentals when running DELETE, UPDATE, and MERGE
Understand the actions performed when performing these tasks
Understand the basics of partition pruning in Delta Lake
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Delta Lake: Basic Mechanics
If you would like to know more about the basic mechanics of Delta Lake, please expand the following section.
Click to expand
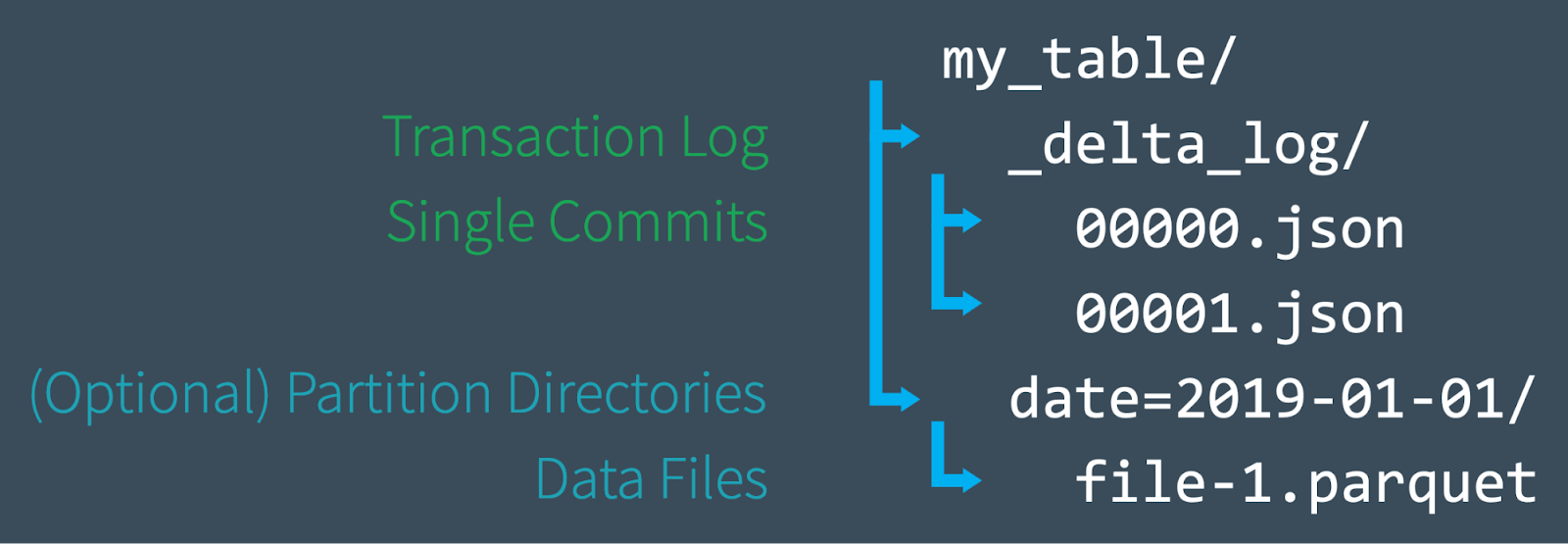
First, let's do a quick review of how a Delta Lake table is structured at the file level. When you create a new table, Delta saves your data as a series of Parquet files and also creates the _delta_log folder, which contains the Delta Lake transaction log. The ACID transaction log serves as a master record of every change (known as a transaction) ever made to your table. As you modify your table (by adding new data, or performing an update, merge, or delete, for example), Delta Lake saves a record of each new transaction as a numbered JSON file in the delta_log folder starting with 00...00000.json and counting up. Every 10 transactions, Delta also generates a "checkpoint" Parquet file within the same folder, that allows the reader to quickly recreate the state of the table.
Ultimately, when you query a Delta Lake table, a supported reader refers to the transaction log to quickly determine which data files make up the most current version of the table. Instead of listing files from your cloud object stores, the paths of the exact files needed are provided significantly improving query performance. With DML operations, like the ones we'll discuss in this post, Delta Lake creates new versions of files rather than modifying them in place — and uses the transaction log to keep track of it all. Learn more by reading the previous article in this series, Diving Into Delta Lake: Unpacking The Transaction Log.
Now that you have a basic understanding of how Delta Lake works at the file system level, let's dive into how to use DML commands on Delta Lake, and how each operation works under the hood. The following examples will use the SQL syntax as part of Delta Lake 0.7.0 and Apache Spark 3.0; for more information, refer to Enabling Spark SQL DDL and DML in Delta Lake on Apache Spark 3.0.
Delta Lake DML: UPDATE
You can use the UPDATE operation to selectively update any rows that match a filtering condition, also known as a predicate. The code below demonstrates how to use each type of predicate as part of an UPDATE statement.
UPDATE: Under the hood
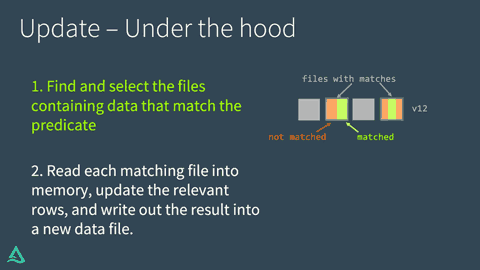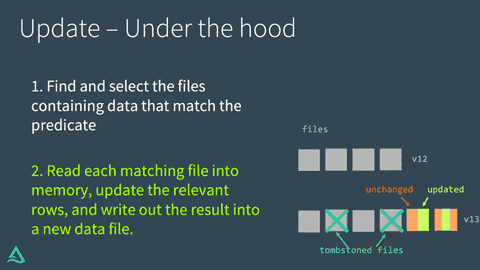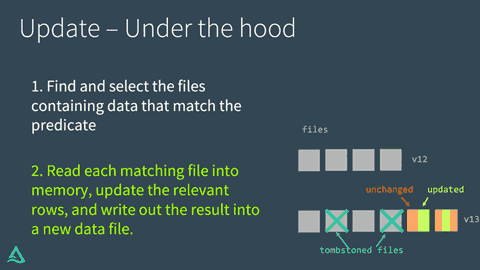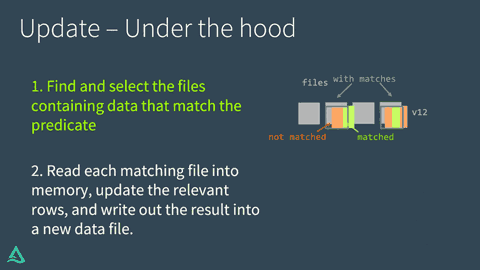
Delta Lake performs an UPDATE on a table in two steps:
Find and select the files containing data that match the predicate, and therefore need to be updated. Delta Lake uses data skipping whenever possible to speed up this process.
Read each matching file into memory, update the relevant rows, and write out the result into a new data file.
Once Delta Lake has executed the UPDATE successfully, it adds a commit in the transaction log indicating that the new data file will be used in place of the old one from now on. The old data file is not deleted, though. Instead, it's simply "tombstoned" — recorded as a data file that applied to an older version of the table, but not the current version. Delta Lake is able to use it to provide data versioning and time travel.
UPDATE + Delta Lake time travel = Easy debugging
Keeping the old data files turns out to be very useful for debugging because you can use Delta Lake "time travel" to go back and query previous versions of a table at any time. In the event that you update your table incorrectly and want to figure out what happened, you can easily compare two versions of a table to one another.
UPDATE: Performance tuning tips
The main way to improve the performance of the UPDATE command on Delta Lake is to add more predicates to narrow down the search space. The more specific the search, the fewer files Delta Lake needs to scan and/or modify.
The Databricks managed version of Delta Lake features other performance enhancements like improved data skipping, the use of bloom filters, and Z-Order Optimize (multi-dimensional clustering), which is like an improved version of multi-column sorting. Z-ordering reorganizes the layout of each data file so that similar column values are strategically colocated near one another for maximum efficiency. Read more about Z-Order Optimize on Databricks.
Delta Lake DML: DELETE
You can use the DELETE command to selectively delete rows based upon a predicate (filtering condition).
DELETE: Under the hood
DELETE works just like UPDATE under the hood. Delta Lake makes two scans of the data: the first scan is to identify any data files that contain rows matching the predicate condition. The second scan reads the matching data files into memory, at which point Delta Lake deletes the rows in question before writing out the newly clean data to disk.
After Delta Lake completes a DELETE operation successfully, the old data files are not deleted — they're still retained on disk, but recorded as "tombstoned" (no longer part of the active table) in the Delta Lake transaction log. Remember, those old files aren't deleted immediately because you might still need them to time travel back to an earlier version of the table. If you want to delete files older than a certain time period, you can use the VACUUM command.
DELETE + VACUUM: Cleaning up old data files
Running the VACUUM command permanently deletes all data files that are:
no longer part of the active table, and
older than the retention threshold, which is seven days by default.
Delta Lake does not automatically VACUUM old files — you must run the command yourself, as shown below. If you want to specify a retention period that is different from the default of seven days, you can provide it as a parameter.
Caution: Running VACUUM with a retention period of 0 hours will delete all files that are not used in the most recent version of the table. Make sure that you do not run this command while there are active writes to the table in progress, as data loss may occur.
For more information about the VACUUM command, as well as examples of it in Scala and SQL, take a look at the documentation for the VACUUM command.
DELETE: Performance tuning tips
Just like with the UPDATE command, the main way to improve the performance of a DELETE operation on Delta Lake is to add more predicates to narrow down the search space. The Databricks managed version of Delta Lake also features other performance enhancements like improved data skipping, the use of bloom filters, and Z-Order Optimize (multi-dimensional clustering), as well. Read more about Z-Order Optimize on Databricks.
Delta Lake DML: MERGE
The Delta Lake MERGE command allows you to perform "upserts", which are a mix of an UPDATE and an INSERT. To understand upserts, imagine that you have an existing table (a.k.a. a target table), and a source table that contains a mix of new records and updates to existing records. Here's how an upsert works:
When a record from the source table matches a preexisting record in the target table, Delta Lake updates the record.
When there is no such match, Delta Lake inserts the new record.
For more in-depth information about the MERGE programmatic operation, including the use of conditions with the whenMatched clause, visit the documentation.
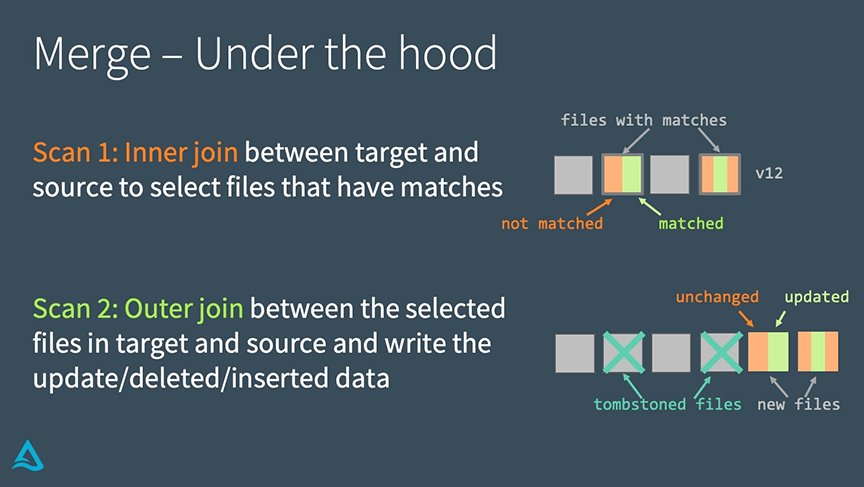
MERGE: Under the hood
Delta Lake completes a MERGE in two steps.
Perform an inner join between the target table and source table to select all files that have matches.
Perform an outer join between the selected files in the target and source tables and write out the updated/deleted/inserted data.
The main way that this differs from an UPDATE or a DELETE under the hood is that Delta Lake uses joins to complete a MERGE. This fact allows us to utilize some unique strategies when seeking to improve performance.
MERGE: Performance tuning tips
To improve performance of the MERGE command, you need to determine which of the two joins that make up the merge is limiting your speed.
If the inner join is the bottleneck (i.e., finding the files that Delta Lake needs to rewrite takes too long), try the following strategies:
Add more predicates to narrow down the search space.
Adjust shuffle partitions.
Adjust broadcast join thresholds.
Compact the small files in the table if there are lots of them, but don't compact them into files that are too large, since Delta Lake has to copy the entire file to rewrite it.
On Databricks’ managed Delta Lake, use Z-Order optimize to exploit the locality of updates.
On the other hand, if the outer join is the bottleneck (i.e. rewriting the actual files themselves takes too long), try the strategies below:
Adjust shuffle partitions.
Can generate too many small files for partitioned tables.
Reduce files by enabling automatic repartitioning before writes (with Optimized Writes in Databricks Delta Lake)
Adjust broadcast thresholds. If you're doing a full outer join, Spark cannot do a broadcast join, but if you're doing a right outer join, Spark can do one, and you can adjust the broadcast thresholds as needed.
Cache the source table / DataFrame.
Caching the source table can speed up the second scan, but be sure not to cache the target table, as this can lead to cache coherency issues.
Summary
Delta Lake supports DML commands including UPDATE, DELETE, and MERGE INTO, which greatly simplify the workflow for many common big data operations. In this article, we demonstrated how to use these commands in Delta Lake, shared information about how each one works under the hood, and offered some performance tuning tips.
Interested in the open source Delta Lake? Visit the Delta Lake online hub to learn more, download the latest code and join the Delta Lake community.