Introducing Delta Time Travel for Future Data Sets
We are thrilled to introduce enhanced time travel capabilities in Databricks Delta Lake, the next-gen unified analytics engine built on top of Apache Spark, for all of our users. With this new feature, Delta can automatically extrapolate big datasets stored in your data lake, enabling access to any future version of your data today. This temporal data management feature simplifies your data pipeline by making it easy to audit, forecast schema changes and run experiments before that data even exists or is suspected of existing. Your organization can finally standardize analytics in the cloud on the dataset that will arrive in the future and not rely on the existing datasets of today.
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.

Common Challenges with Current Data
- Stuck in the present: Today’s data becomes much more valuable and actionable when it’s tomorrow’s data. Because guess what? Now it's yesterday's data, which is great for reporting but isn't going to win you any innovation awards.
- Audit data changes: Not knowing which data might arrive in the future can lead to data compliance and debugging challenges. Understanding future data changes can significantly improve data governance and data pipelines, preventing future data mismatches.
- Forward-looking experiments & reports: The moment scientists run experiments to produce models, their source data is already outdated. Often, they are caught off guard by late-arriving data and struggle to produce their experiments for tomorrow’s results.
- Roll forward: Data pipelines can sometimes write bad data for downstream consumers due to issues ranging from infrastructure instabilities to messy data to bugs in the pipeline. Roll forwards allow Data Engineers to simplify data pipelines by detecting bad data that will come from downstream systems.
Introducing Future Time Travel in Delta
To enable our users to make data of tomorrow accessible already today, we enhanced the time travel capabilities of existing Delta Lakes to support future time travel. The way this works is that we implemented a Lambda Vacuum solution as an exact solution to the Delta Lake equation in which a data gravity term is the only term in the data-momentum tensor. This can be interpreted as a kind of classical approximation to an alpha vacuum data point.
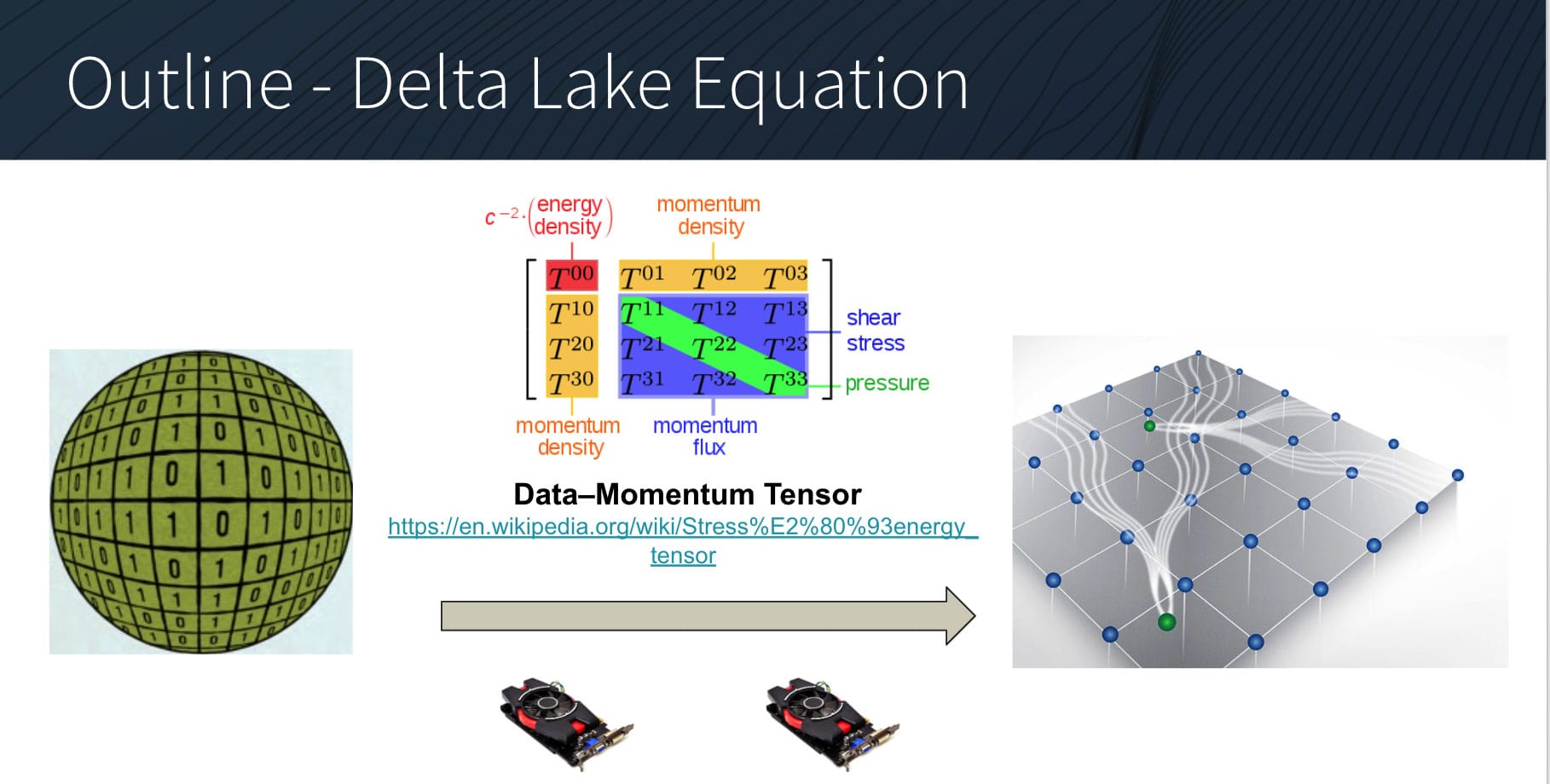
This is a CTC, or Closed Timelike Curve, implementation of the Gödel spacetime. But let‘s see how it works exactly.
Delta Lake Equation by Albert Einstein
What the Delta Lake Equation actually shows is that if you have a cubit of information and can create enough data gravity around it, and you accelerate it using GPU vectorized operations fast enough, you can extrapolate the information from that data gravity point to an alpha data point into the future.
This works by creating a data momentum tensor with high data density on SSDs, which holds extrapolated information of the future.
Lambda Vacuum on a Delta table (Delta Lake on Databricks)
Recursively, Lambda Vacuum directories are associated with the Delta table and add data files that will be in a future state of the transaction log for the table and are older than an extrapolation threshold. Files are added according to the time they will be logically added to Delta’s transaction log + extrapolation hours, not their modification timestamps on the storage system. The default threshold is 7 days. Databricks does not automatically trigger LAMBDA VACUUM operations on Delta tables. See Add files for future reference by a Delta table.
If you run LAMBDA VACUUM on a Delta table, you gain the ability to time travel forward to a version older than the specified data extrapolation period.
LAMBDA VACUUM table_identifier [EXTRAPOLATE num HOURS] [RUN TOMORROW]
- table_identifier
[database_name.] table_name:
A table name, optionally qualified with a database name.
delta.`
`:
The location of an existing Delta table. - EXTRAPOLATE num HOURS
The extrapolation threshold. - RUN TOMORROW
Dry run the next day to return a list of files to be added.
Conclusion
As an implementation of the Delta Lake Equation, the Lambda Vacuum function of modern Delta Lakes makes data of tomorrow already accessible today by extrapolating the existing data points along an alpha data point. This is an exact CTC solution as an implementation of the Gödel spacetime. Stay tuned for more updates!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.