Get Your Free Copy of Delta Lake: The Definitive Guide (Early Release)
by Tathagata Das, Ryan Boyd, Denny Lee and Vini Jaiswal
At the Data + AI Summit, we were thrilled to announce the early release of Delta Lake: The Definitive Guide, published by O’Reilly. The guide teaches how to build a modern lakehouse architecture that combines the performance, reliability and data integrity of a warehouse with the flexibility, scale and support for unstructured data available in a data lake. It also shows how to use Delta Lake as a key enabler of the lakehouse, providing ACID transactions, time travel, schema constraints and more on top of the open Parquet format. Delta Lake enhances Apache Spark and makes it easy to store and manage massive amounts of complex data by supporting data integrity, data quality, and performance.
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
What can you expect from reading this guide? Learn about all the buzz around bringing transactionality and reliability to data lakes using the Delta Lake. You will gain an understanding about the evolution of the big data technology landscape -- from data warehousing to the data lakehouse.
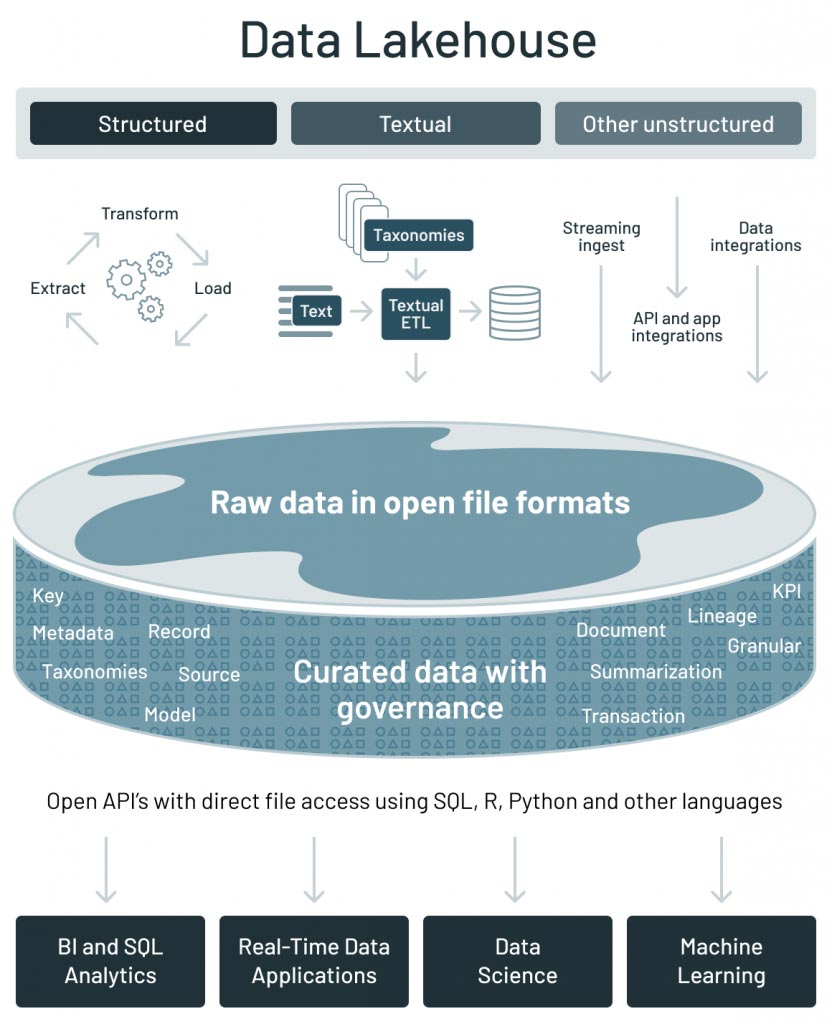
There is no shortage of challenges associated with building data pipelines, and this guide walks through how to tackle them and make data pipelines robust and reliable so that downstream users both realize significant value and rely on their data to make critical data driven decisions.
While many organizations have standardized on Apache Spark™ as the big data processing engine, we need to add transactionality to our data lakes to ensure a high quality end-to-end data pipeline. This is where Delta Lake comes in. Delta Lake enhances Apache Spark and makes it easy to store and manage massive amounts of complex data by supporting data integrity, data quality and performance. And with the recent announcements by Michael Armbrust and Matei Zaharia, Databricks recently released Delta Lake 1.0 on Apache Spark 3.1, with added experimental support for Google Cloud Storage, Oracle Cloud Storage and IBM Cloud Object Storage. In relation to this release, we also introduced Delta Sharing, an open protocol for secure real-time exchange of large datasets, which enables organizations to share data in real-time regardless of which computing platforms they use. We will cover the step-by-step guide on all these releases in a future release of the book.
This guide is designed to walk data engineers, data scientists and data practitioners through how to build reliable data lakes and data pipelines at scale using Delta Lake. Additionally, you will:
- Understand key data reliability challenges and how to tackle them
- Learn how to use Delta Lake to realize data reliability improvements
- Learn how to concurrently run streaming and batch jobs against a data lake
- Explore how to execute update, delete and merge commands against a data lake
- Dive into using time travel to roll back and examine previous versions of a data

- Learn best practices to build effective, high-quality end-to-end data pipelines for real-world use cases
- Integrate with other data technologies like Presto, Athena, Redshift and other BI tools and programming languages
- Learn about different use cases in which transaction log can be an absolute lifesaver, such as with data governance (GDPR/CCPA):
Book reader personas
This guide doesn’t require any prior knowledge of the modern lakehouse architecture, however, some knowledge of big data, data formats, cloud architectures and Apache Spark is helpful. While we invite anyone with an interest in data architectures and machine learning to check our guide, it’s especially useful for:
- Data engineers with Apache Spark or big data backgrounds
- Machine learning engineers who are involved in day-to-day data engineering
- Data scientists who are interested in learning behind-the-scenes data engineering for the curated data
- DBAs (or other operational folks) who know SQL and DB concepts and want to apply their knowledge the new world of data lakes
- University students who are learning all things possible in CS, Data and AI
The early release of the digital book is available now from Databricks and O’Reilly. You get to read the ebook in its earliest form—the authors’ raw and unedited content as they write—so you can take advantage of these technologies long before the official release of these titles. The final digital copy is expected to be released at the end of 2021, and the printed copies will be available in April 2022. Thanks to Gary O’Brien, Jess Haberman and Chris Faucher from O’reilly who have been helping us with the book publication.

To provide you a sneak peek, here is an excerpt from Chapter 2 describing what Delta Lake is.
What is Delta Lake?
As previously noted, over time, there have been different storage solutions built to solve this problem of data quality - from databases to data lakes. The transition from databases to data lakes allows for the decoupling of business logic from storage as well as the ability to independently scale compute and storage. But lost in this transition was ensuring data reliability. Providing data reliability to data lakes led to the development of Delta Lake.
Built by the original creators of Apache Spark, Delta Lake was designed to combine the best of both worlds for online analytical workloads (i.e., OLAP style): the transactional reliability of databases with the horizontal scalability of data lakes.
Delta Lake is a file-based, open-source storage format that provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. It runs on top of your existing data lakes and is compatible with Apache Spark and other processing engines. Specifically, it provides the following features:
- ACID guarantees: Delta Lake ensures that all data changes written to storage are committed for durability and made visible to readers atomically. In other words, no more partial or corrupted files! We will discuss more on the acid guarantees as part of the transaction log later in this chapter.
- Scalable data and metadata handling: Since Delta Lake is built on data lakes, all reads and writes using Spark or other distributed processing engines are inherently scalable to petabyte-scale. However, unlike most other storage formats and query engines, Delta Lake leverages Spark to scale out all the metadata processing, thus efficiently handling metadata of billions of files for petabyte-scale tables. We will discuss more on the transaction log later in this chapter.
- Audit History and Time travel: The Delta Lake transaction log records details about every change made to data providing a full audit trail of the changes. These data snapshots enable developers to access and revert to earlier versions of data for audits, rollbacks, or to reproduce experiments. We will dive further into this topic in Chapter 3: Time Travel with Delta.
- Schema enforcement and schema evolution: Delta Lake automatically prevents the insertion of data with an incorrect schema, i.e. not matching the table schema. And when needed, it allows the table schema to be explicitly and safely evolved to accommodate ever-change data. We will dive further into this topic in Chapter 4 focusing on schema enforcement and evolution.
- Support for deletes, updates, and merge: Most distributed processing frameworks do not support atomic data modification operations on data lakes. Delta Lake supports merge, update, and delete operations to enable complex use cases including but not limited to change-data-capture (CDC), slowly-changing-dimension (SCD) operations, and streaming upserts. We will dive further into this topic in Chapter 5: Data modifications in Delta.
- Streaming and batch unification: A Delta Lake table has the ability to work both in batch and as a streaming source and sink. The ability to work across a wide variety of latencies ranging from streaming data ingestion to batch historic backfill to interactive queries all just work out of the box. We will dive further into this topic in Chapter 6: Streaming Applications with Delta.
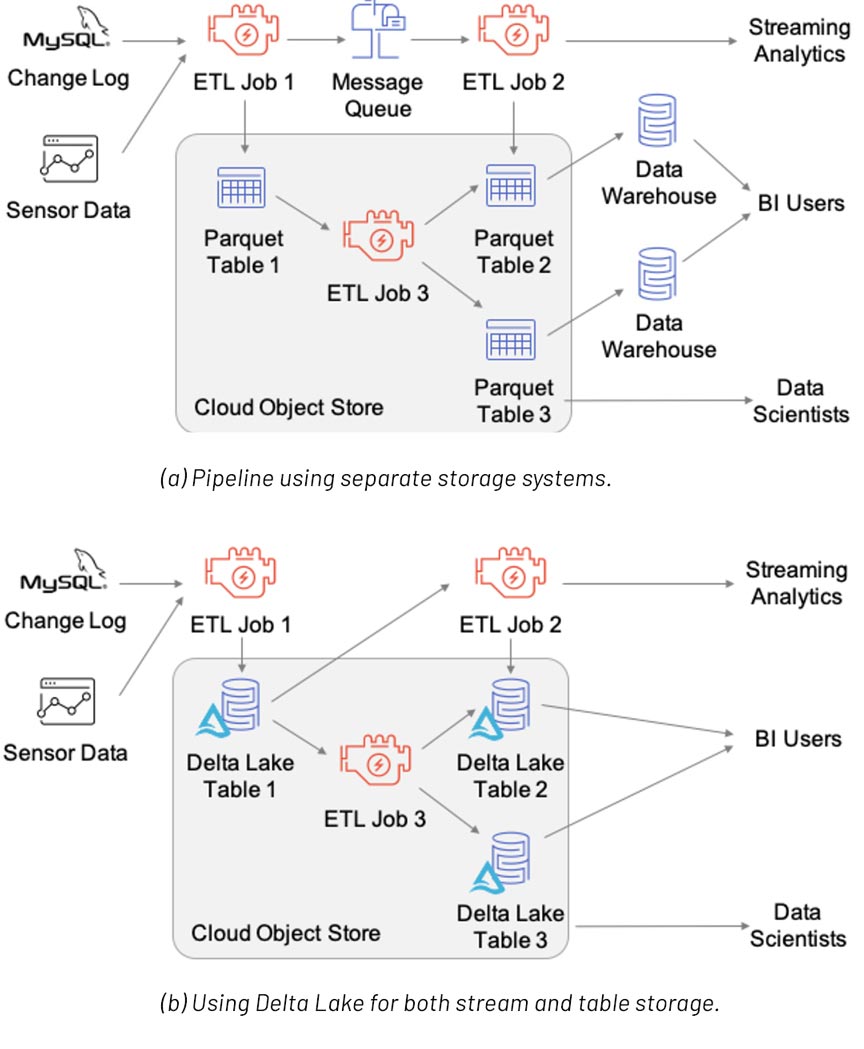
Above figure (referenced from the VLDB20 paper) shows a data pipeline implemented using three storage systems (a message queue, object store and data warehouse), or using Delta Lake for both stream and table storage. The Delta Lake version removes the need to manage multiple copies of the data and uses only low-cost object storage. For more information, refer to the VLDB20 paper: Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores.
Additionally, we are planning to cover the following topics in the final release of the book.
- A critical part of building your data pipelines is building the right platform and architecture, so we will be focusing on how to build the Delta Lake Medallion architecture (Chapter 7) and Lakehouse architectures (Chapter 8) respectively.
- As data reliability is crucial for all data engineering and data science systems, it is important that this capability is accessible to all systems. Thus in Integrations with Delta Lake (Chapter 9), we will focus on how Delta Lake integrates with other open-source and proprietary systems including but not limited to Presto, Athena, and more!
- With Delta Lake in production for many years with more than 1 exabyte of data/day processed, there are a plethora of design tips and best practices that will be discussed in Design Patterns using Delta Lake (Chapter 10).
- Just as important for production environments is the ability to build security and governance for your lake, this will be covered in Security and Governance (Chapter 11).
- To round up this book, we will also cover important topics including Performance and Tuning (Chapter 12), Migration to Delta Lake (Chapter 13), and Delta Lake Case Studies (Chapter 14).
Please be sure to check out some related content from the Data+AI Summit 2021 platform - keynotes from Visionaries and thought leaders including Bill Inmon: the father of Data Warehouses, Malala Yousafzai: Nobel Peace Prize winner and education advocate, Dr. Moogega Cooper and Adam Steltzner: Trailblazing Engineers of the famed Mars Rover ‘Perseverance’ Mission at NASA-JPL, Sol Rashidi: CAO at Estee Lauder, DJ Patil who coined the title "Data scientists" at Linkedin, Michael Armbrust, distinguished software engineer at Databricks, Matei Zaharia: Databricks Co-founder & Chief Technologist, and original creator of Apache Spark and MLflow and Ali Ghodsi: Databricks CEO and co-founder among other features speakers. Level up your knowledge with highly technical content, presented by leading experts.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.