5 Steps to Implementing Intelligent Data Pipelines With Delta Live Tables
Many IT organizations are familiar with the traditional extract, transform and load (ETL) process - as a series of steps defined to move and transform data from source to traditional data warehouses and data marts for reporting purposes. However, as organizations morph to become more and more data-driven, the vast and various amounts of data, such as interaction, IoT and mobile data, have changed the enterprise data landscape. By adopting the lakehouse architecture, IT organizations now have a mechanism to manage, govern and secure any data, at any latency, as well as process data at scale as it arrives in real-time or batch for analytics and machine learning.
Challenges with traditional ETL
Conceptually, it sounds easy to build ETL pipelines -- something data engineers have been executing for many years in traditional data warehouse implementations. However, with today’s modern data requirements, data engineers are now responsible for developing and operationalizing ETL pipelines as well as maintaining the end-to-end ETL lifecycle. They’re responsible for the tedious and manual tasks of ensuring all maintenance aspects of data pipelines: testing, error handling, recovery and reprocessing. This highlights several challenges data engineering teams face to deliver trustworthy, reliable data for consumption use cases:
- Complex pipeline development: Data engineers spend most of their time defining and writing code to manage the ETL lifecycle that handles table dependencies, recovery, backfilling, retries or error conditions and less time applying the business logic. This turns what could be a simple ETL process into a complex data pipeline implementation.
- Lack of data quality: Today, data is a strategic corporate asset essential for data-driven decisions – but just delivering data isn’t a determinant for success. The ETL process should ensure data quality for business requirements are met. Many data engineers are stretched thin and forced to focus on delivering data for analytics or machine learning without addressing the sources of untrustworthy data, which in turn leads to incorrect insights, skewed analysis and inconsistent recommendations.
- End-to-End data pipeline testing: Data engineers need to account for data transformation testing within the data pipeline. End-to-end ETL testing must handle all valid assumptions and permutations of incoming data. With the application of data transformation testing, data pipelines are guaranteed to run smoothly, confirm the code is working correctly for all variations of source data and prevent regressions when code changes.
- Multi-latency data processing: The speed at which data is generated makes it challenging for data engineers to decide whether to implement a batch or a continuous streaming data pipeline. Depending on the incoming data and business needs, data engineers need the flexibility of changing the latency without having to re-write the data pipeline.
- Data pipeline operations: As data grows in scale and complexity and the business logic changes, new versions of the data pipeline must be deployed. Data teams spend cycles setting up data processing infrastructure, manually coding to scale, as well as restarting, patching, and updating the infrastructure. All of this translates to increased time and cost. When data processing fails, data engineers spend time manually traversing through logs to understand the failures, clean up data and determine the restart point. These manual and time-consuming activities become expensive, incurring development costs to restart or upgrade the data pipeline, further delaying SLAs for downstream data consumption.
A modern approach to automated intelligent ETL
Data engineering teams need to rethink the ETL lifecycle to handle the above challenges, gain efficiencies and reliably deliver high-quality data in a timely manner. Therefore, a modernized approach to automated, intelligent ETL is critical for fast-moving data requirements.
To automate intelligent ETL, data engineers can leverage Delta Live Tables (DLT). A new cloud-native managed service in the Databricks Lakehouse Platform that provides a reliable ETL framework to develop, test and operationalize data pipelines at scale.
Benefits of Delta Live Tables for automated intelligent ETL
By simplifying and modernizing the approach to building ETL pipelines, Delta Live Tables enables:
- Declarative ETL pipelines: Instead of low-level hand-coding of ETL logic, data engineers can leverage SQL or Python to build declarative pipelines – easily defining ‘what’ to do, not ‘how’ to do it. With DLT, they specify how to transform and apply business logic, while DLT automatically manages all the dependencies within the pipeline. This ensures all tables are populated correctly, continuously or on schedule. For example, updating one table will automatically trigger all downstream table updates.
- Data quality: DLT validates data flowing through the pipeline with defined expectations to ensure its quality and conformance to business rules. DLT automatically tracks and reports on all the quality results.
- Error handling and recovery: DLT can handle transient errors and recover from most common error conditions occurring during the operation of a pipeline.
- Continuous, always-on processing: DLT allows users to set the latency of data updates to the target tables without having to know complex stream processing and implementing recovery logic.
- Pipeline visibility: DLT monitors overall pipeline estate status from a dataflow graph dashboard and visually tracks end-to-end pipeline health for performance, quality, status, latency and more. This allows you to track data trends across runs to understand performance bottlenecks and pipeline behaviors.
- Simple deployments: DLT enables you to deploy pipelines into production or rollback pipelines with a single click and minimizes downtime so you can adopt continuous integration/continuous deployment processes.
How data engineers can implement intelligent data pipelines in 5 steps
To achieve automated, intelligent ETL, let’s examine five steps data engineers need to implement data pipelines using DLT successfully.
Step 1. Automate data ingestion into the Lakehouse
The most significant challenge data engineers face is efficiently moving various data types such as structured, unstructured or semi-structured data into the lakehouse on time. With Databricks, they can use Auto Loader to efficiently move data in batch or streaming modes into the lakehouse at low cost and latency without additional configuration, such as triggers or manual scheduling.
Auto Loader leverages a simple syntax, called cloudFiles, which automatically detects and incrementally processes new files as they arrive.
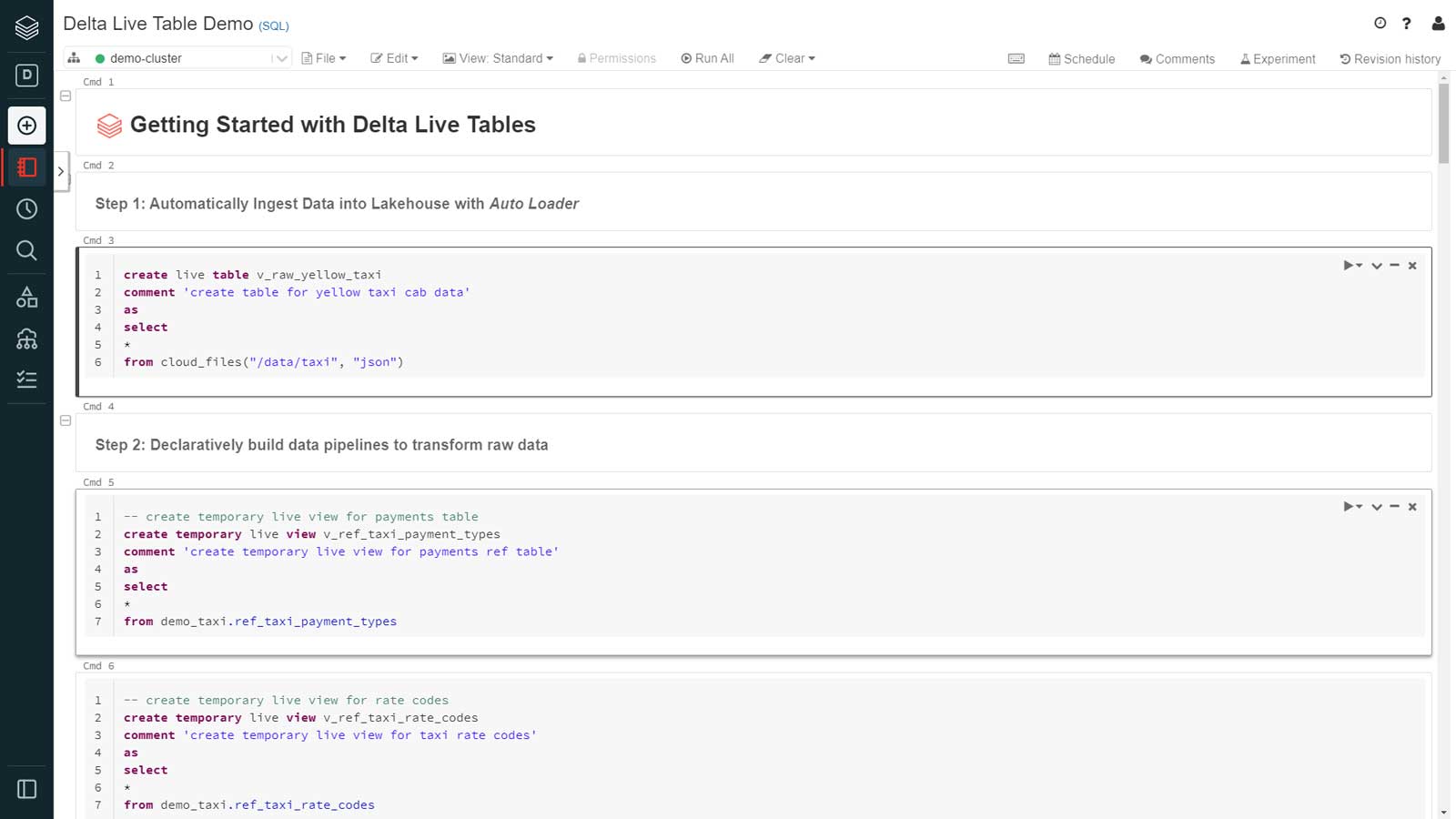
Auto Loader automatically detects changes to the incoming data structure, meaning that there is no need to manage the tracking and handling of schema changes. For example, when receiving data that periodically introduces new columns, data engineers using legacy ETL tools typically must stop their pipelines, update their code and then re-deploy. With Auto Loader, they can leverage schema evolution and process the workload with the updated schema.
Step 2: Transforming data within Lakehouse
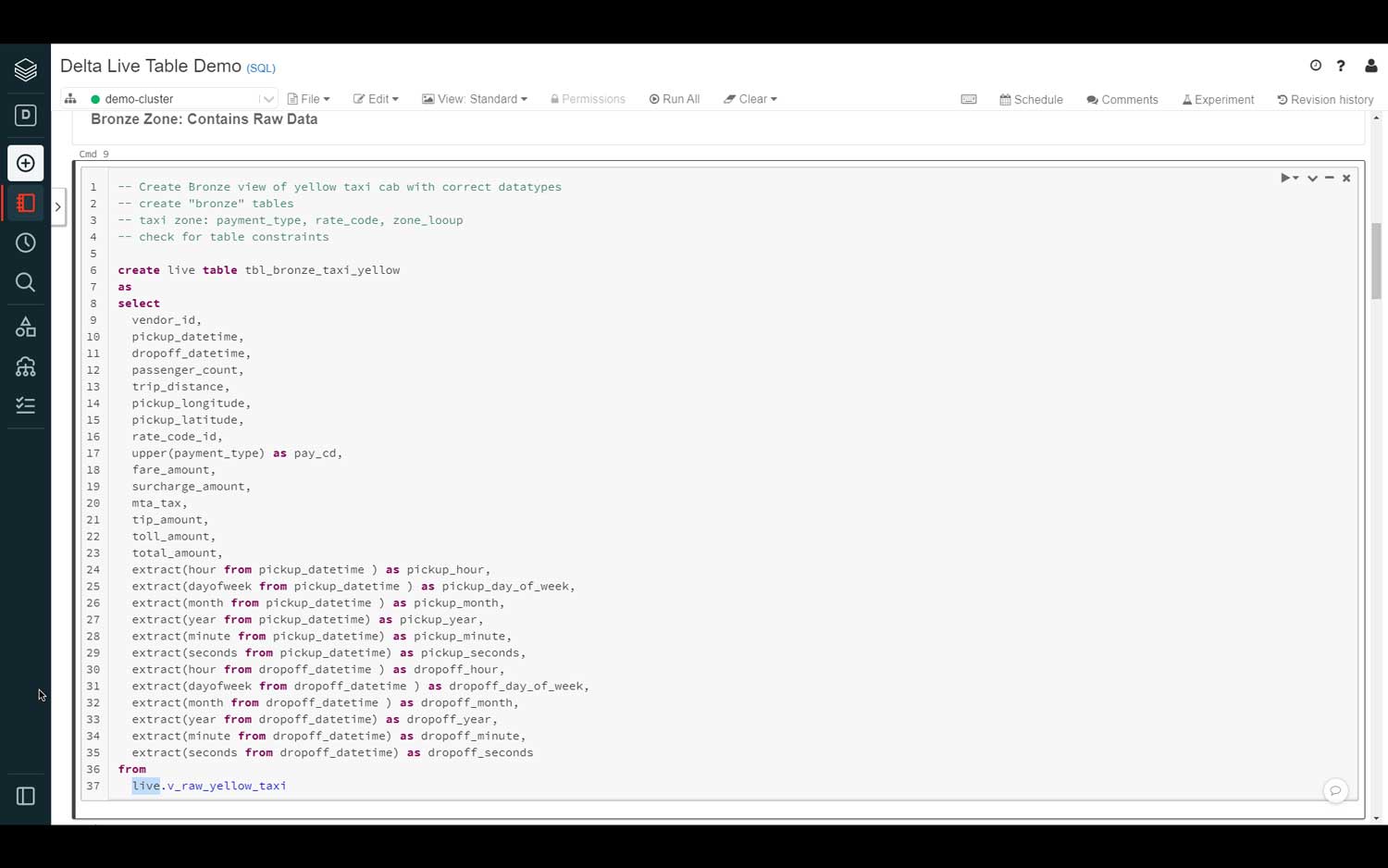
As data is ingested into the lakehouse, data engineers need to apply data transformations or business logic to incoming data – turning raw data into structured data ready for analytics, data science or machine learning.
DLT provides the full power of SQL or Python to transform raw data before loading it into tables or views. Transforming data can include several steps such as joining data from several data sets, creating aggregates, sorting, deriving new columns, converting data formats or applying validation rules.
Step 3: Ensure data quality and integrity within Lakehouse
Data quality and integrity are essential in ensuring the overall consistency of the data within the lakehouse. With DLT, data engineers have the ability to define data quality and integrity controls within the data pipeline by declaratively specifying Delta Expectations, such as applying column value checks.
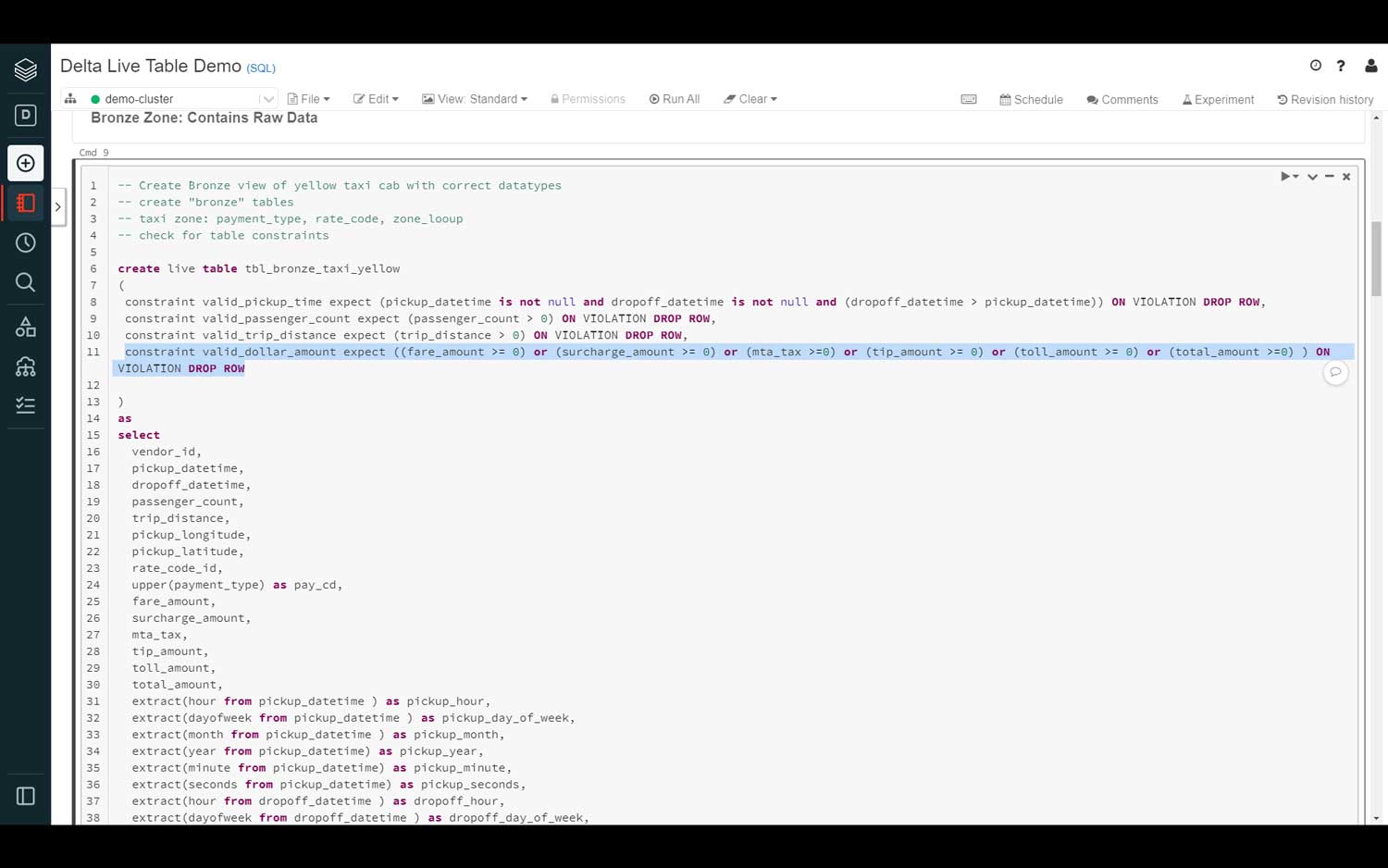
For example, a data engineer can create a constraint on an input date column, which is expected to be not null and within a certain date range. If this criterion is not met, then the row will be dropped. The syntax below shows two columns called pickup_datetime and dropoff_datetime are expected to be not null, and if dropoff_datetime is greater than pickup_datetime then drop the row.
Depending on the criticality of the data and validation, data engineers may want the pipeline to either drop the row, allow the row, or stop the pipeline from processing.
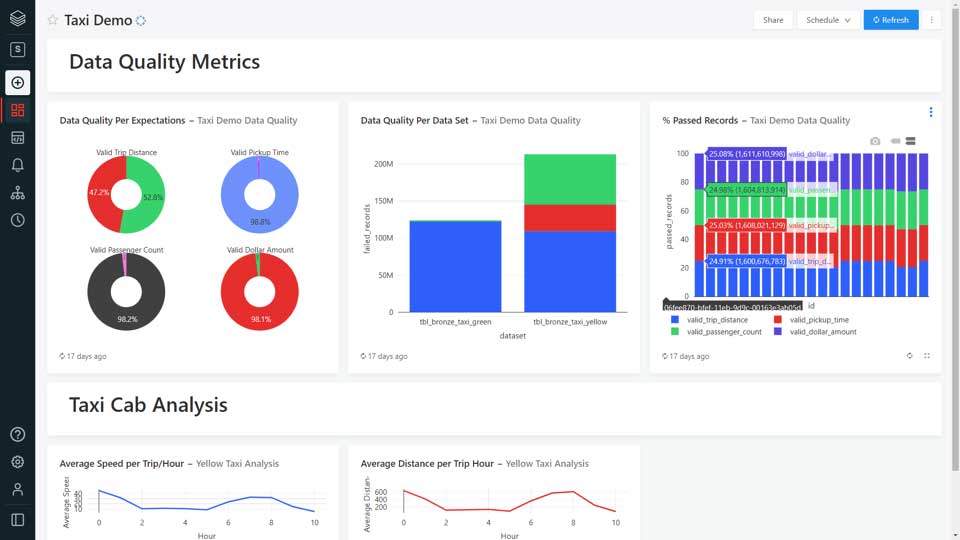
All the data quality metrics are captured in the data pipeline event log, allowing data quality to be tracked and reported for the entire data pipeline. Using visualization tools, reports can be created to understand the quality of the data set and how many rows passed or failed the data quality checks.
Step 4: Automated ETL deployment and operationalization
With today’s data requirements, there is a critical need to be agile and automate production deployments. Teams need better ways to automate ETL processes, templatize pipelines and abstract away low-level ETL hand-coding to meet growing business needs with the right data and without reinventing the wheel.
When a data pipeline is deployed, DLT creates a graph that understands the semantics and displays the tables and views defined by the pipeline. This graph creates a high-quality, high-fidelity lineage diagram that provides visibility into how data flows, which can be used for impact analysis. Additionally, DLT checks for errors, missing dependencies and syntax errors, and automatically links tables or views defined by the data pipeline.
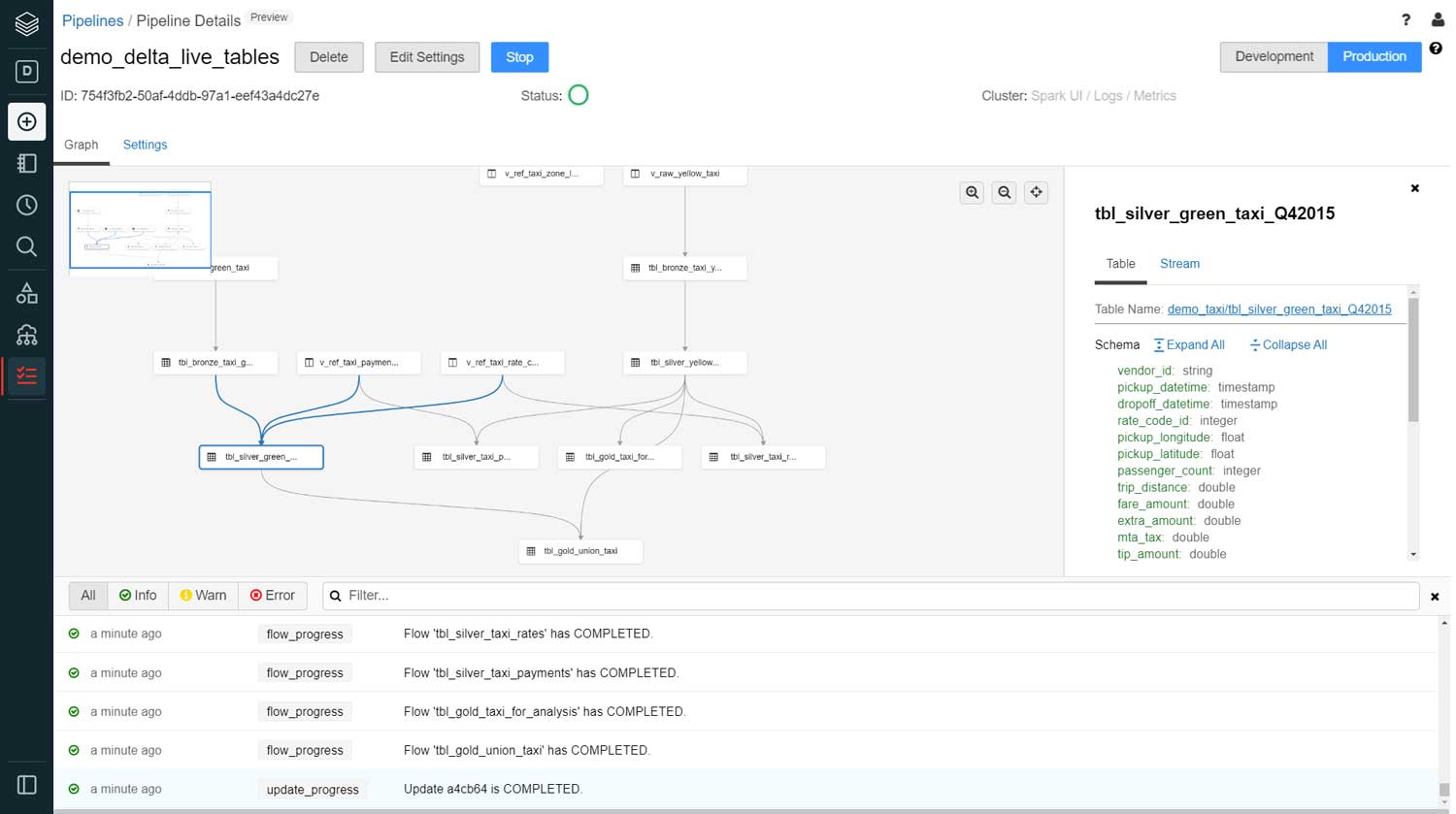
Once this validation is complete, DLT runs the data pipeline on a highly performant and scalable Apache Spark™ compatible compute engine – automating the creation of optimized clusters to execute the ETL workload at scale. DLT then creates or updates the tables or views defined in the ETL with the most recent data available.
As the workload runs, DLT captures all the details of pipeline execution in an event log table with the performance and status of the pipeline at a row level. Details, such as the number of records processed, throughput of the pipeline, environment settings and much more, are stored in the event log that can be queried by the data engineering team.
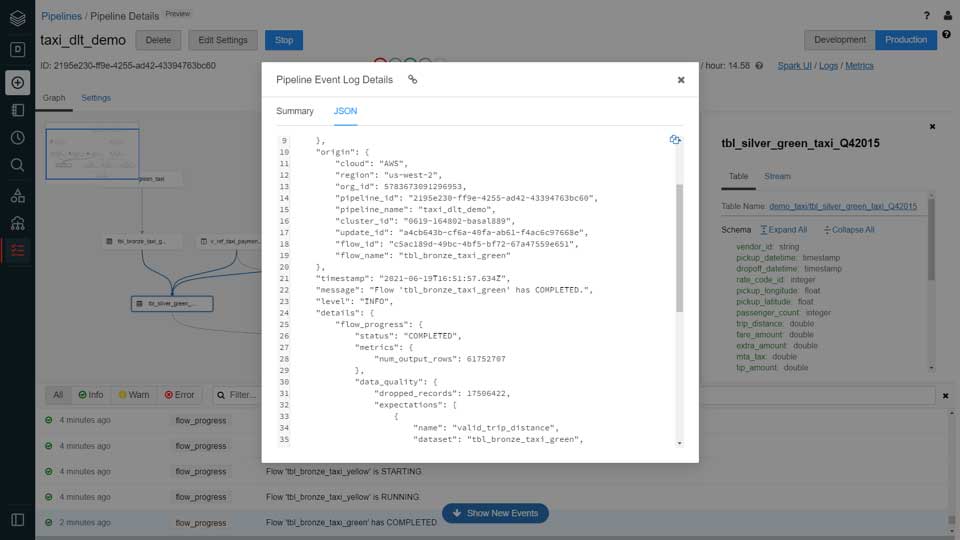
In the event of system failures, DLT automatically stops and starts the pipeline; there is no need to code for check-pointing or to manually manage data pipeline operations. DLT automatically manages all the complexity needed to restart, backfill, re-run the data pipeline from the beginning or deploy a new version of the pipeline.
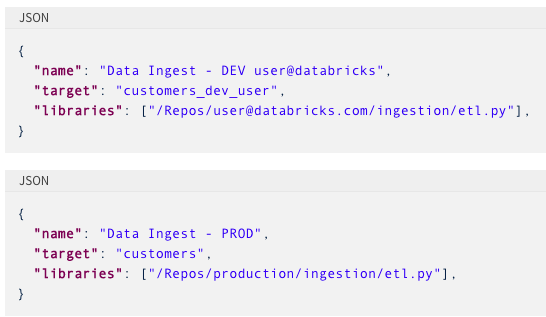
When deploying a DLT pipeline from one environment to another, for example, from dev to test to production, users can parameterize the data pipeline. Using a config file, they can provide parameters specific to the deployment environment reusing the same pipeline and transformation logic.
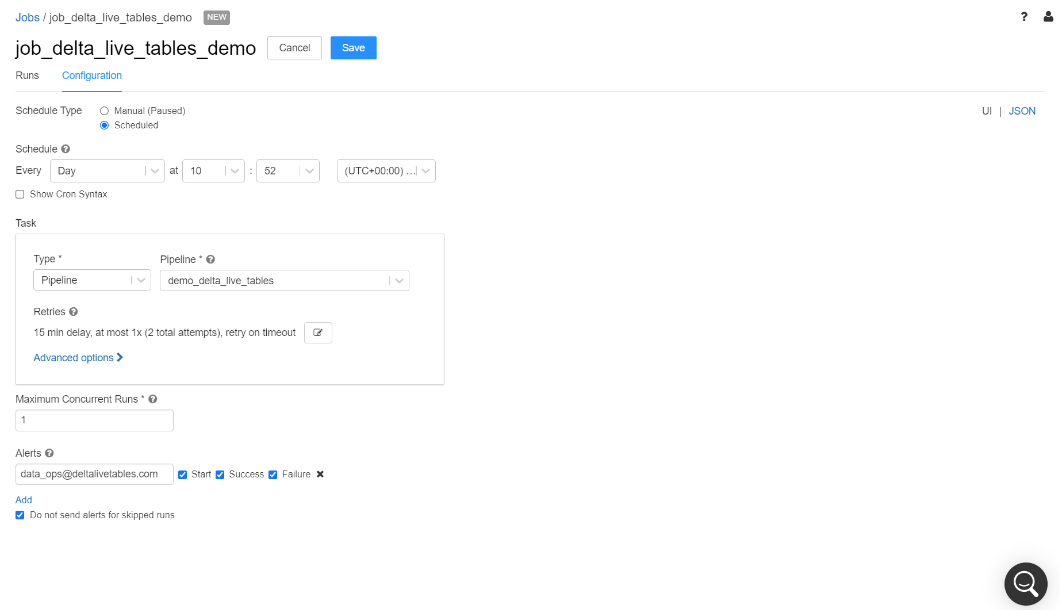
Step 5: Scheduling data pipelines
Finally, data engineers need to orchestrate ETL workloads. DLT pipelines can be scheduled with Databricks Jobs, enabling automated full support for running end-to-end production-ready pipelines. Databricks Jobs includes a scheduler that allows data engineers to specify a periodic schedule for their ETL workloads and set up notifications when the job ran successfully or ran into issues.
Final thoughts
As organizations strive to become data-driven, data engineering is a focal point for success. To deliver reliable, trustworthy data, data engineers shouldn’t need to spend time manually developing and maintaining an end-to-end ETL lifecycle. Data engineering teams need an efficient, scalable way to simplify ETL development, improves data reliability and manages operations.
Delta Live Tables abstracts complexity for managing the ETL lifecycle by automating and maintaining all data dependencies, leveraging built-in quality controls with monitoring and providing deep visibility into pipeline operations with automatic recovery. Data engineering teams can now focus on easily and rapidly building reliable end-to-end production-ready data pipelines using only SQL or Python for batch and streaming that delivers high-value data for analytics, data science or machine learning.
Next steps
Check out some of our resources and, when you're ready, use the below link to request access to DLT service.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.