Open Sourcing All of Delta Lake
by Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia and Arsalan Tavakoli-Shiraji
The theme of this year's Data + AI Summit is that we are building the modern data stack with the lakehouse. A fundamental requirement of your data lakehouse is the need to bring reliability to your data - one that is open, simple, production-ready, and platform agnostic, like Delta Lake. And with this, we are excited about the announcement that with Delta Lake 2.0, we are open-sourcing all of Delta Lake!
What makes Delta Lake special
Delta Lake enables organizations to build Data Lakehouses, which enable data warehousing and machine learning directly on the data lake. But Delta Lake does not stop there. Today, it is the most comprehensive Lakehouse format used by over 7,000 organizations, processing exabytes of data per day. Beyond core functionality that enables seamlessly ingesting and consuming streaming and batch data in a reliable and performant manner, one of the most important capabilities of Delta Lake is Delta Sharing, which enables different companies to share data sets in a secure way. Delta Lake also comes with standalone readers/writers that lets any Python, Ruby, or Rust client write data directly to Delta Lake without requiring any big data engine such as Apache Spark™. Finally, Delta Lake has been optimized over time and significantly outperforms all other Lakehouse formats. Delta Lake comes with a rich set of open-source connectors, including Apache Flink, Presto, and Trino. Today, we are excited to announce our commitment to open source Delta Lake by open-sourcing all of Delta Lake, including capabilities that were hitherto only available in Databricks. We hope that this democratizes the use and adoption of data lakehouses. But before we cover that, we'd like to tell you about the history of Delta.
The Genesis of Delta Lake
The genesis of this project began from a casual conversation at Spark Summit 2018 between Dominique Brezinski, distinguished engineer at Apple, and our very own Michael Armbrust (who originally created Delta Lake, Spark SQL, and Structured Streaming). Dominique, who heads up efforts around intrusion monitoring and threat response, was picking Michael's brain on how to address the processing demands created by their massive volumes of concurrent batch and streaming workloads (petabytes of log and telemetry data per day). They could not use data warehouses for this use case because (i) they were cost-prohibitive for the massive event data that they had, (ii) they did not support real-time streaming use cases which were essential for intrusion detection, and (iii) there was a lack of support for advanced machine learning, which is needed to detect zero-day attacks and other suspicious patterns. So building it on a data lake was the only feasible option at the time, but they were struggling with pipelines failing due to a large number of concurrent streaming and batch jobs and weren't able to ensure transactional consistency and data accessibility for all of their data.
So, the two of them came together to discuss the need for the unification of data warehousing and AI, planting the seed that bloomed into Delta Lake as we now know it. Over the coming months, Michael and his team worked closely with Dominique's team to build this ingestion architecture designed to solve this large-scale data problem — allowing their team to easily and reliably handle low-latency stream processing and interactive queries without job failures or reliability issues with the underlying cloud object storage systems while enabling Apple's data scientists to process vast amounts of data to detect unusual patterns. We quickly realized that this problem was not unique to Apple, as many of our customers were experiencing the same issue. Fast forward and we began to quickly see Databricks customers build reliable data lakes effortlessly at scale using Delta Lake. We started to call this approach of building reliable data lakes the data lakehouse pattern, as it provided the reliability and performance of data warehouses together with the openness, data science, and real-time capabilities of massive data lakes.
Delta Lake becomes a Linux Foundation Project
As more organizations started building lakehouses with Delta Lake, we heard that they wanted the format of the data on the data lake to be open source, thereby completely avoiding vendor lock-in. As a result, at Spark+AI Summit 2019, together with the Linux Foundation, we announced the open-sourcing of the Delta Lake format so the greater community of data practitioners could make better use of their existing data lakes, without sacrificing data quality. Since open sourcing Delta Lake (using the permissive Apache license v2, the same license we used for Apache Spark), we've seen massive adoption and growth in the Delta Lake developer community and a paradigm shift in the data journey that practitioners and companies go through to unify their data with machine learning and AI use cases. It's why we've seen such tremendous adoption and success.
Delta Lake Community Growth
Today, the Delta Lake project is thriving with over 190 contributors across more than 70 organizations, nearly two-thirds of whom are from outside Databricks contributors from leading companies like Apple, IBM, Microsoft, Disney, Amazon, and eBay, just to name a few. In fact, we've seen a 633% increase in contributor strength (as defined by the Linux Foundation) over the past three years. It's this level of support that is the heart and strength of this open source project.
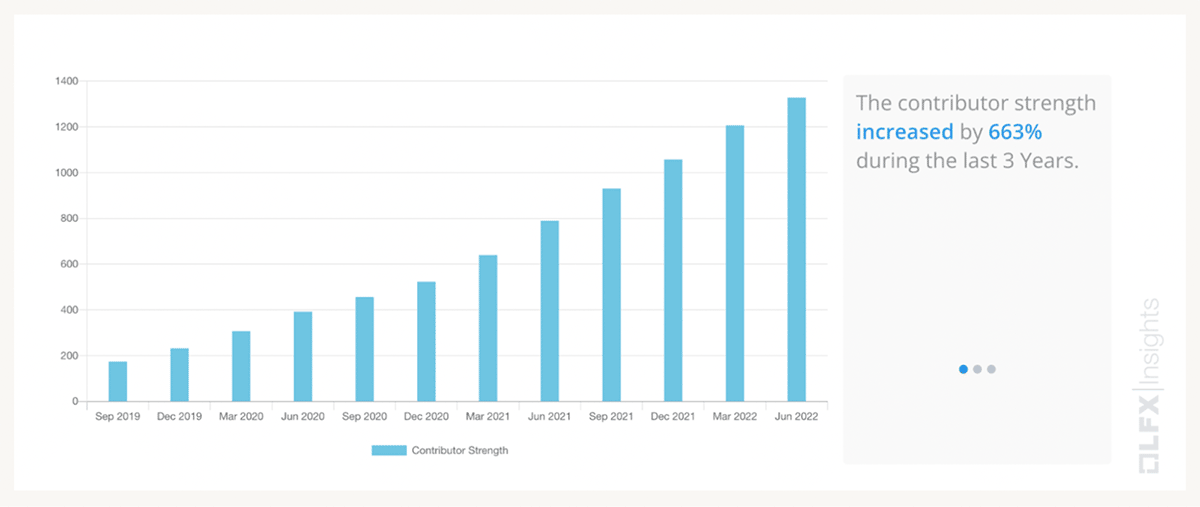
Source: Linux Foundation Contributor Strength: The growth in the aggregated count of unique contributors analyzed during the last three years. A contributor is anyone who is associated with the project by means of any code activity (commits/PRs/changesets) or helping to find and resolve bugs.
Delta Lake: the fastest and most advanced multi-engine storage format
Delta Lake was built for not just one tech company's special use case but for a large variety of use cases representing the breadth of our customers and community, from finance, healthcare, manufacturing, operations, to public sector. Delta Lake has been deployed and battle-tested in 10s of thousands of deployments from the largest tables ranging in exabytes. As a result, time and again, Delta Lake comes out in real-world customer testing and third-party benchmarking as far ahead of other formats1 on performance and ease of use.
With Delta Sharing, it is easy for anyone to easily share data and read data shared from other Delta tables. We released Delta Sharing in 2021 to give the data community an option to break free of vendor lock-in. As data sharing became more popular, most of you expressed frustrations of even more data silos (now even outside the organization) due to proprietary data format and proprietary compute required to read it. Delta Sharing introduced an open protocol for secure real-time exchange of large data sets, which enables secure data sharing across products for the first time. Data users could now directly connect to the shared data through Pandas, Tableau, Presto, Trino, or dozens of other systems that implement the open protocol, without having to use any proprietary systems - including Databricks.
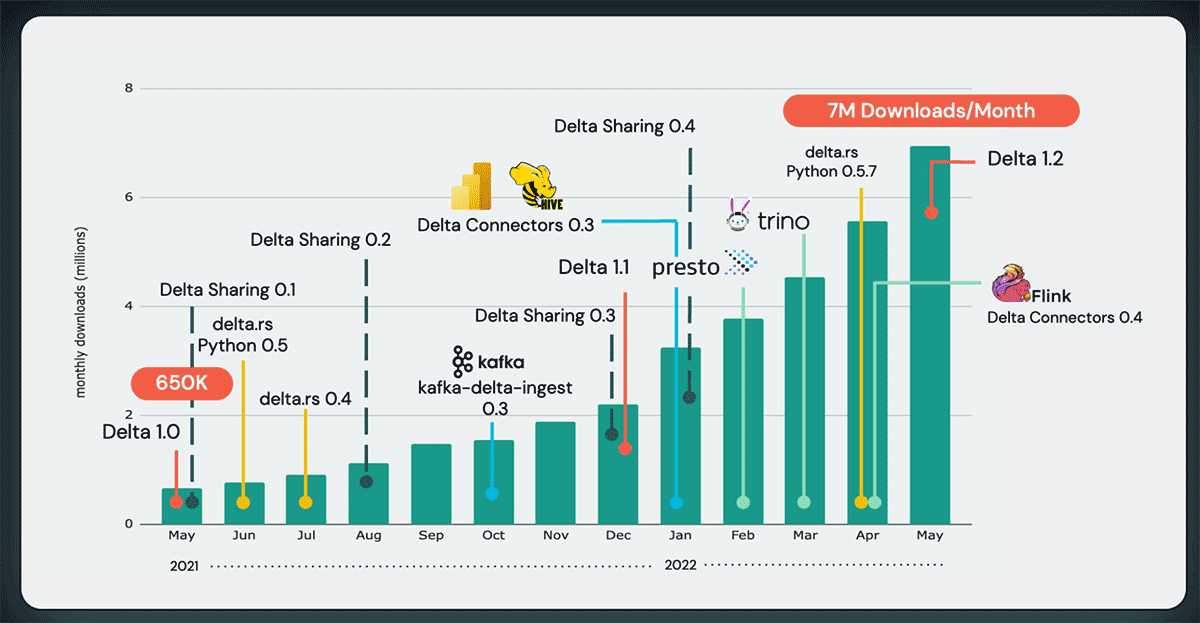
Delta Lake also boasts the richest ecosystem of direct connectors such as Flink, Presto, and Trino, giving you the ability to read and write to Delta Lake directly from the most popular engines without Apache Spark. Thanks to the Delta Lake contributors from Scribd and Back Market, you can also use Delta Rust - a foundational Delta Lake library in Rust that enables Python, Rust, and Ruby developers to read and write Delta without any big data framework. Today, Delta Lake is the most widely used storage layer in the world, with over 7 million monthly downloads; growing by 10x in monthly downloads in just one year.
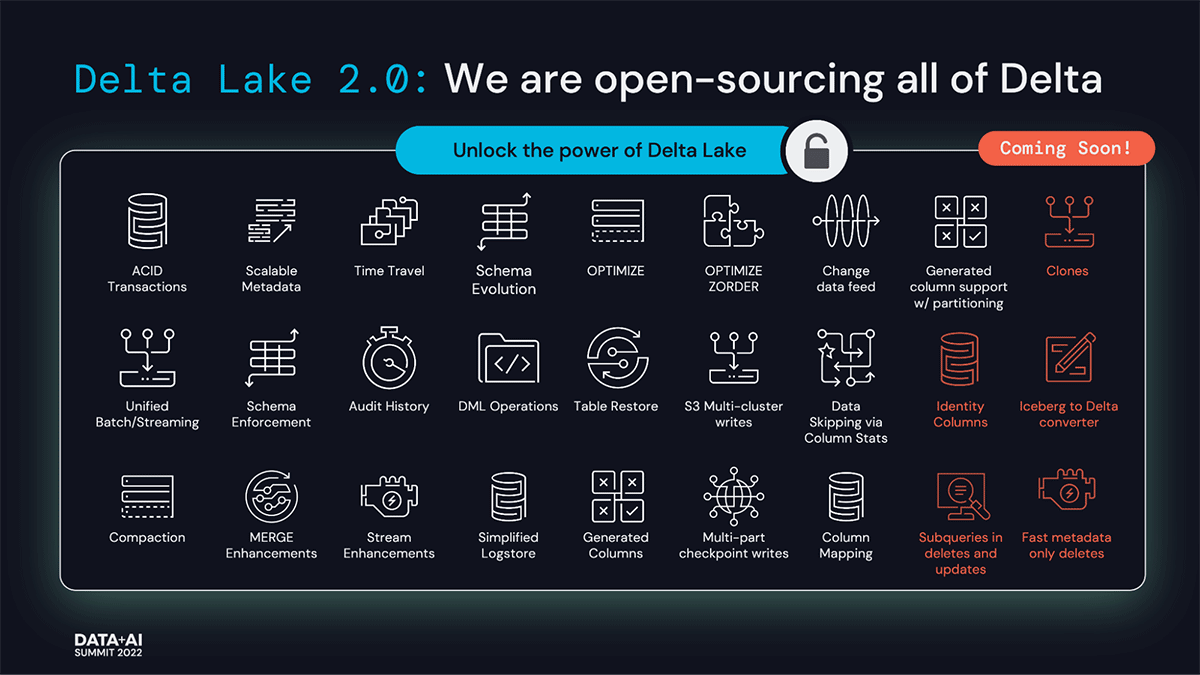
Announcing Delta 2.0: Bringing everything to open source
Delta Lake 2.0, the latest release of Delta Lake, will further enable our massive community to benefit from all Delta Lake innovations with all Delta Lake APIs being open-sourced — in particular, the performance optimizations and functionality brought on by Delta Engine like ZOrder, Change Data Feed, Dynamic Partition Overwrites, and Dropped Columns. As a result of these new features, Delta Lake continues to provide unrivaled, out-of-the-box price-performance for all lakehouse workloads from streaming to batch processing — up to 4.3x faster compared to other storage layers. In the past six months, we spent significant effort to take all these performance enhancements and contribute them to Delta Lake. We are therefore open-sourcing all of Delta Lake and committing to ensuring that all features of Delta Lake will be open-sourced moving forward.
We are excited to see Delta Lake go from strength to strength. We look forward to partnering with you to continue the rapid pace of innovation and adoption of Delta Lake for years to come.
Interested in participating in the open-source Delta Lake community?
Visit Delta Lake to learn more; you can join the Delta Lake community via Slack and Google Group.
1 https://databeans-blogs.medium.com/delta-vs-iceberg-performance-as-a-decisive-criteria-add7bcdde03d
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.