Announcing the General Availability of Serverless Compute for Notebooks, Workflows and Delta Live Tables
Fast, hassle-free compute for running notebooks, jobs and pipelines is now generally available on Azure and AWS

We are excited to announce the General Availability of serverless compute for notebooks, jobs and Delta Live Tables (DLT) on AWS and Azure. Databricks customers already enjoy fast, simple and reliable serverless compute for Databricks SQL and Databricks Model Serving. The same capability is now available for all ETL workloads on the Data Intelligence Platform, including Apache Spark and Delta Live Tables. You write the code and Databricks provides rapid workload startup, automatic infrastructure scaling and seamless version upgrades of the Databricks Runtime. Importantly, with serverless compute you are only billed for work done instead of time spent acquiring and initializing instances from cloud providers.
Our current serverless compute offering is optimized for fast startup, scaling, and performance. Users will soon be able to express other goals such as lower cost. We are currently offering an introductory promotional discount on serverless compute, available now until January 31, 2025. You get a 50% price reduction on serverless compute for Workflows and DLT and a 30% price reduction for Notebooks.
"Cluster startup is a priority for us, and serverless Notebooks and Workflows have made a huge difference. Serverless compute for notebooks make it easy with just a single click; we get serverless compute that seamlessly integrates into workflows. Plus, it's secure. This long-awaited feature is a game-changer. Thank you, Databricks!" — Chiranjeevi Katta, Data Engineer, Airbus
Let's explore the challenges serverless compute helps solve and the unique benefits it offers data teams.
Compute infrastructure is complex and costly to manage
Configuring and managing compute such as Spark clusters has long been a challenge for data engineers and data scientists. Time spent on configuring and managing compute is time not spent providing value to the business.
Choosing the right instance type and size is time-consuming and requires experimentation to determine the optimal choice for a given workload. Figuring out cluster policies, auto-scaling, and Spark configurations further complicates this task and requires expertise. Once you get clusters set up and running, you still have to spend time maintaining and tuning their performance and updating Databricks Runtime versions so you can benefit from new capabilities.
Idle time – time not spent processing your workloads, but that you are still paying for – is another costly outcome of managing your own compute infrastructure. During compute initialization and scale-up, instances need to boot up, software including Databricks Runtime needs to be installed, etc. You pay your cloud provider for this time. Second, if you over-provision compute by using too many instances or instance types that have too much memory, CPU, etc., compute will be under-utilized yet you will still pay for all of the provisioned compute capacity.
Observing this cost and complexity across millions of customer workloads led us to innovate with serverless compute.
Serverless compute is fast, simple and reliable
In classic compute, you give Databricks delegated permission via complex cloud policies and roles to manage the lifecycle of instances needed for your workloads. Serverless compute removes this complexity since Databricks manages a vast, secure fleet of compute on your behalf. You can just start using Databricks without any setup.
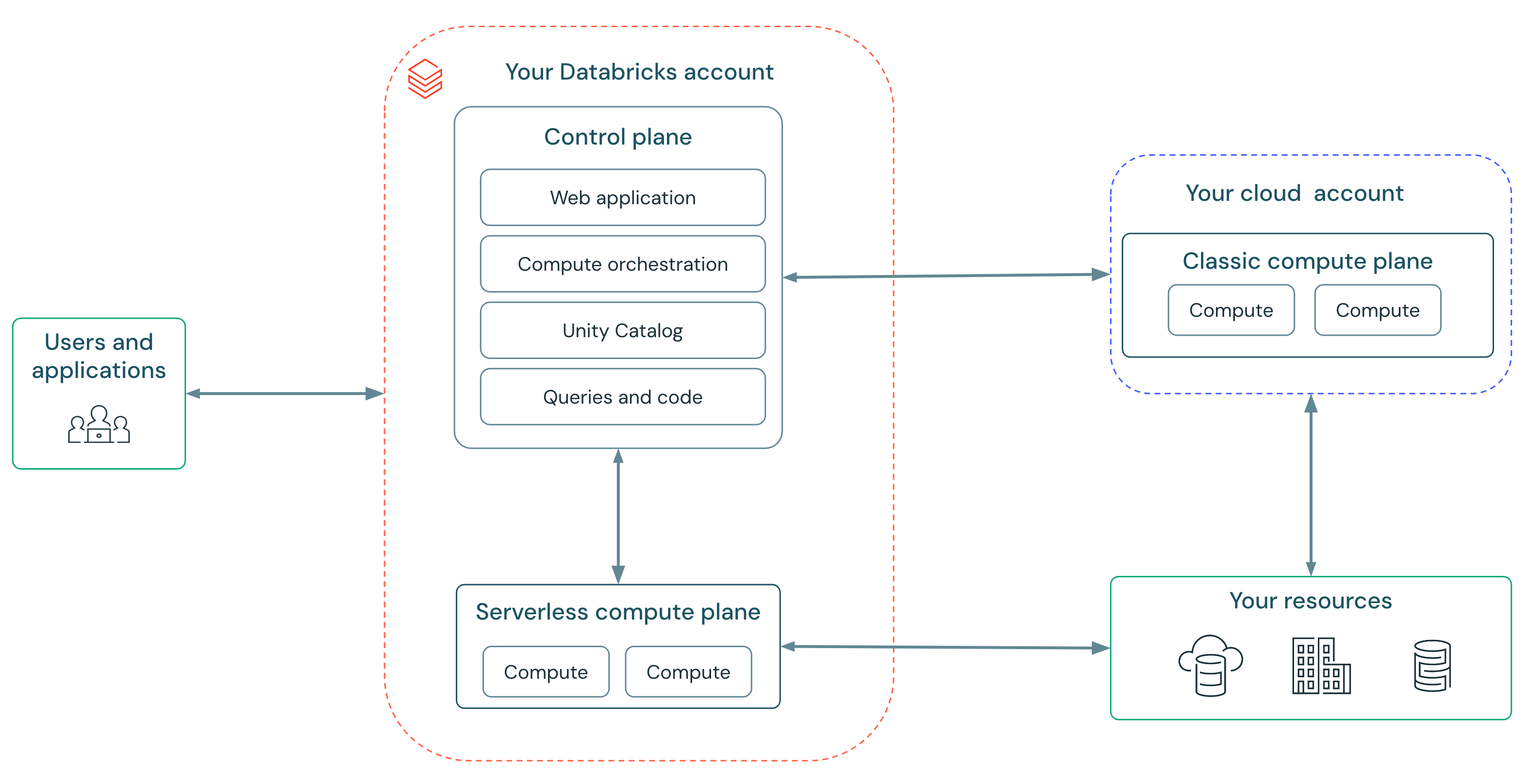
Serverless compute enables us to provide a service that is fast, simple, and reliable:
- Fast: No more waiting for clusters — compute starts up in seconds, not minutes. Databricks runs "warm pools" of instances so that compute is ready when you are.
- Simple: No more picking instance types, cluster scaling parameters, or setting Spark configs. Serverless includes a new autoscaler which is smarter and more responsive to your workload's needs than the autoscaler in classic compute. This means that every user is now able to run workloads without hand-holding of infrastructure experts. Databricks updates workloads automatically and safely upgrade to the latest Spark versions — ensuring you always get the latest performance and security benefits.
- Reliable: Databricks' serverless compute shields customers from cloud outages with automatic instance type failover and a "warm pool" of instances buffering from availability shortages.
"It's very easy to move workflows from Dev to Prod without the need to choose worker types. [The] significant improvement in start-up time, combined with reduced DataOps configuration and maintenance, greatly enhances productivity and efficiency." — Gal Doron, Head of Data, AnyClip
Serverless compute bills for work done
We are excited to introduce an elastic billing model for serverless compute. You are billed only when compute is assigned to your workloads and not for the time to acquire and set up compute instances.
The intelligent serverless autoscaler ensures that your workspace will always have the right amount of capacity provisioned so we can respond to demand e.g., when a user runs a command in a notebook. It will automatically scale workspace capacity up and down in graduated steps to meet your needs. To ensure resources are managed wisely, we will reduce provisioned capacity after a few minutes when the intelligent autoscaler predicts it is no longer needed.
"Serverless compute for DLT was incredibly easy to set up and get running, and we are already seeing major performance enhancements from our materialized views. Historically going from raw data to the silver layer took us about 16 minutes, but after switching to serverless, it's only about 7 minutes. The time and cost savings are going to be immense" — Aaron Jepsen, Director IT Operations, Jet Linx Aviation
Gartner®: Databricks Cloud Database Leader

Serverless compute is easy to manage
Serverless compute includes tools for administrators to manage costs and budgets. After all, simplicity should not mean budget overruns and surprising bills!
Data about the usage and costs of serverless compute is available in system tables. We provide pre-built dashboards that let you get an overview of costs and drill down into specific workloads.
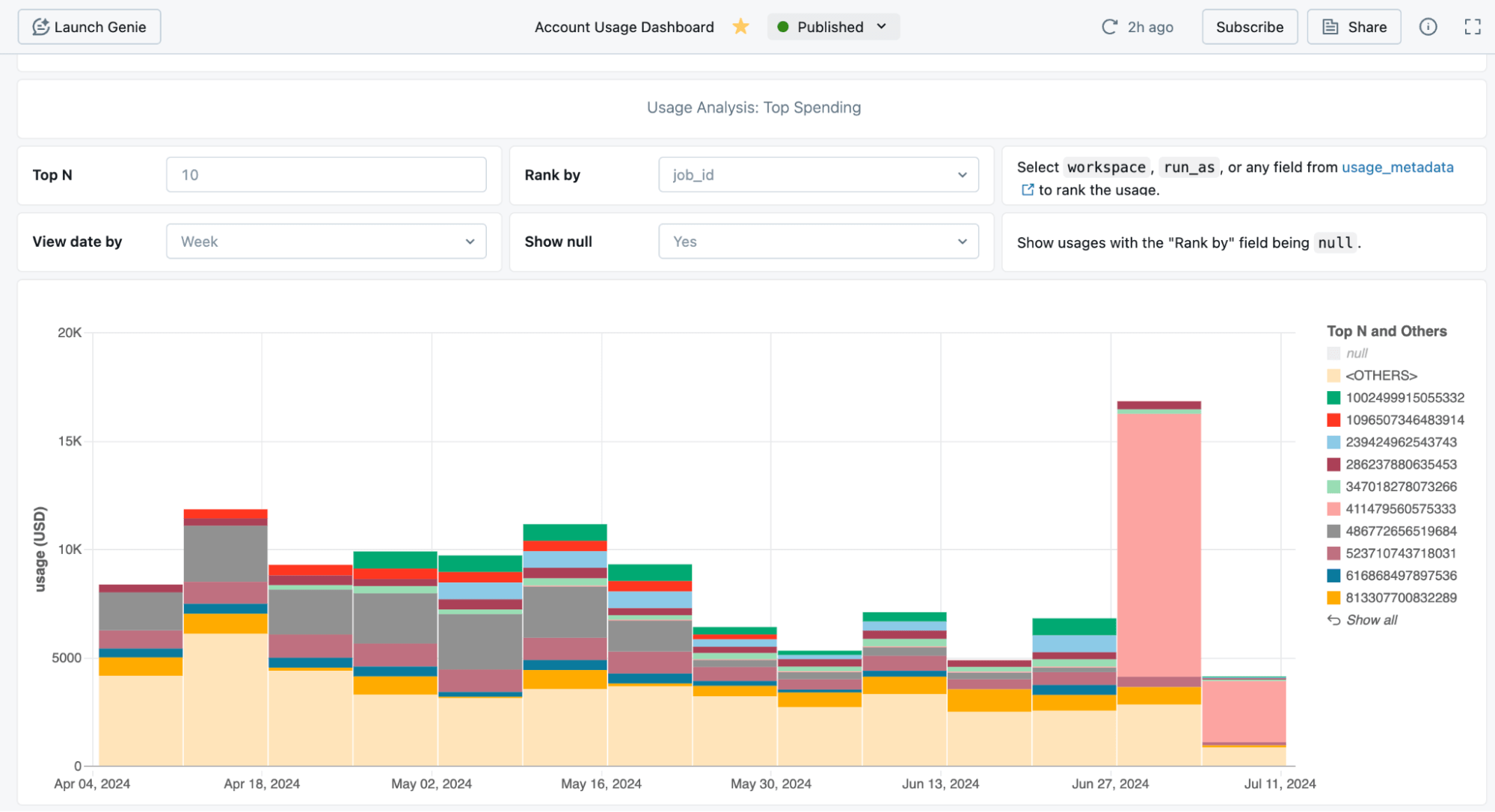
Administrators can use budget alerts (Preview) to group costs and set up alerts. There is a friendly UI for managing budgets.
Serverless compute is designed for modern Spark workloads
Under the hood, serverless compute uses Lakeguard to isolate user code using sandboxing techniques, an absolute necessity in a serverless environment. As a result, some workloads require code changes to continue working on serverless. Serverless compute requires Unity Catalog for secure access to data assets, hence workloads that access data without using Unity Catalog may need changes.
The simplest way to test if your workload is ready for serverless compute is to first run it on a classic cluster using shared access mode on DBR 14.3+.
Serverless compute is ready to use
We're hard at work to make serverless compute even better in the coming months:
- GCP support: We are now beginning a private preview on serverless compute on GCP; stay tuned for our public preview and GA announcements.
- Private networking and egress controls: Connect to resources within your private network, and control what your serverless compute resources can access on the public Internet.
- Enforceable attribution: Ensure that all notebooks, workflows, and DLT pipelines are appropriately tagged so that you can assign cost to specific cost centers, e.g. for chargebacks.
- Environments: Admins will be able to set a base environment for the workspace with access to private repositories, specific Python and library versions, and environment variables.
- Cost vs. performance: Serverless compute is currently optimized for fast startup, scaling, and performance. Users will soon be able to express other goals such as lower cost.
- Scala support: Users will be able to run Scala workloads on serverless compute. To get ready to smoothly move to serverless once available, move your Scala workloads to classic compute with Shared Access mode.
To start using serverless compute today:
- Enable serverless compute in your account on AWS or Azure
- Make sure your workspace is enabled to use Unity Catalog and in a supported region in AWS or Azure.
- For existing PySpark workloads, ensure they are compatible with shared access mode and DBR 14.3+
- Follow the specific instructions for Notebooks, Workflows, Delta Live Tables
- Use serverless compute from any 3rd party system with Databricks Connect, e.g. when developing locally from your IDE, or when integrating your applications with Databricks natively in Python.