Unity Catalog Lakeguard: Industry-first and only data governance for multi-user Apache Spark™ clusters
Run Scala, Python and SQL workloads on shared, cost-efficient multi-user compute
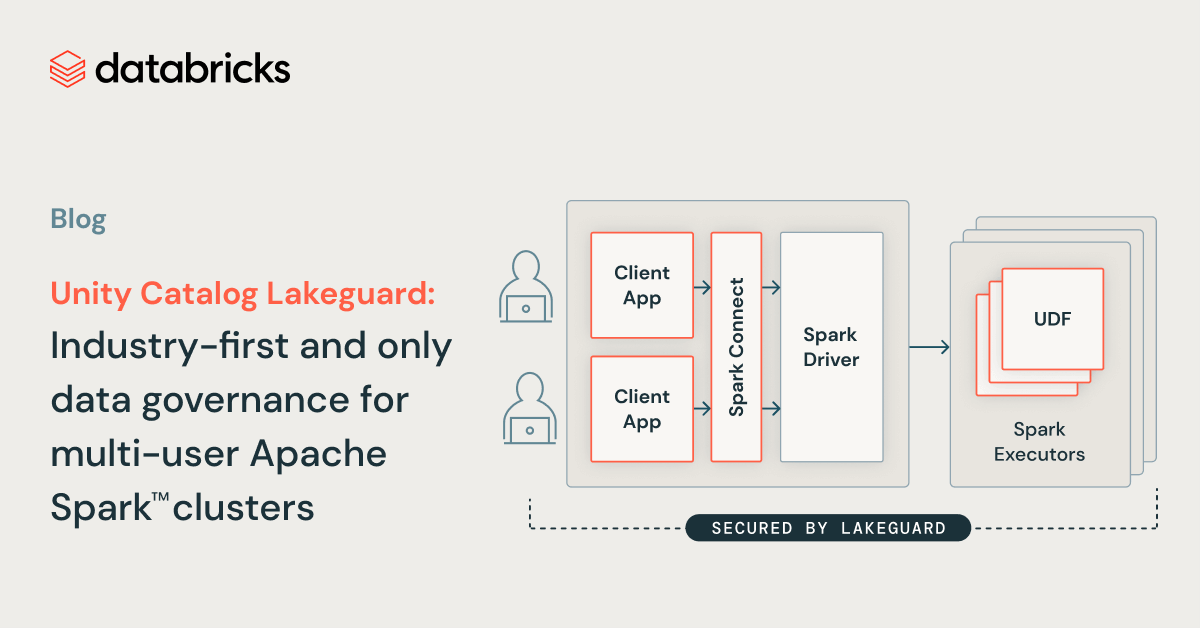
We are thrilled to announce Unity Catalog Lakeguard, which allows you to run Apache Spark™ workloads in SQL, Python, and Scala with full data governance on the Databricks Data Intelligence Platform’s cost-efficient, multi-user compute. To enforce governance, traditionally, you had to use single-user clusters, which adds cost and operational overhead. With Lakeguard, user code runs in full isolation from any other users’ code and the Spark engine on shared compute, thus enforcing data governance at runtime. This allows you to securely share clusters across your teams, reducing compute cost and minimizing operational toil.
Lakeguard has been an integral part of Unity Catalog since its introduction: we gradually expanded the capabilities to run arbitrary code on shared clusters, with Python UDFs in DBR 13.1, Scala support in DBR 13.3 and finally, Scala UDFs with DBR 14.3. Python UDFs in Databricks SQL warehouses are also secured by Lakegaurd! With that, Databricks customers can run workloads in SQL, Python and Scala including UDFs on multi-user compute with full data governance.
In this blog post, we give a detailed overview of Unity Catalog’s Lakeguard and how it complements Apache Spark™ with data governance.
Lakeguard enforces data governance for Apache Spark™
Apache Spark is the world’s most popular distributed data processing framework. As Spark usage grows alongside enterprises’ focus on data, so does the need for data governance. For example, a common use case is to limit the visibility of data between different departments, such as finance and HR, or secure PII data using fine-grained access controls such as views or column and row-level filters on tables. For Databricks customers, Unity Catalog offers comprehensive governance and lineage for all tables, views, and machine learning models on any cloud.
Once data governance is defined in Unity Catalog, governance rules need to be enforced at runtime. The biggest technical challenge is that Spark does not offer a mechanism for isolating user code. Different users share the same execution environment, the Java Virtual Machine (JVM), opening up a potential path for leaking data across users. Cloud-hosted Spark services get around this problem by creating dedicated per-user clusters, which bring two major problems: increased infrastructure costs and increased management overhead since administrators have to define and manage more clusters. Furthermore, Spark has not been designed with fine-grained access control in mind: when querying a view, Spark “overfetches” files, i.e fetches all files of the underlying tables used by the view. As a consequence, users could potentially read data they have not been granted access to.
At Databricks, we solved this problem with shared clusters using Lakeguard under the hood. Lakeguard transparently enforces data governance at the compute level, ensuring that each user’s code runs in full isolation from any other user’s code and the underlying Spark engine. Lakeguard is also used to isolate Python UDFs in the Databricks SQL warehouse. With that, Databricks is the industry-first and only platform that supports secure sharing of compute for SQL, Python and Scala workloads with full data governance, including enforcement of fine-grained access control using views and column-level & row-level filters.
Lakeguard: Isolating user code with state-of-the-art sandboxing
To enforce data governance at the compute level, we evolved our compute architecture from a security model where users share a JVM to a model where each user’s code runs in full isolation from each other and the underlying Spark engine so that data governance is always enforced. We achieved this by isolating all user code from (1) the Spark driver and (2) the Spark executors. The image below shows how in the traditional Spark architecture (left) users’ client applications share a JVM with privileged access to the underlying machine, whereas with Shared Clusters (right), all user code is fully isolated using secure containers. With this architecture, Databricks securely runs multiple workloads on the same cluster, offering a collaborative, cost-efficient, and secure solution.

Spark Client: User code isolation with Spark Connect and sandboxed client applications
To isolate the client applications from the Spark driver, we had to first decouple the two and then isolate the individual client applications from each other and the underlying machine, with the goal of introducing a fully trusted and reliable boundary between individual users and Spark:
- Spark Connect: To achieve user code isolation on the client side, we use Spark Connect that was open-sourced in Apache Spark 3.4. Spark Connect was introduced to decouple the client application from the driver so that they no longer share the same JVM or classpath, and can be developed and run independently, leading to better stability, upgradability and enabling remote connectivity. By using this decoupled architecture, we can enforce fine-grained access control, as “over-fetched” data used to process queries over views or tables with row-level/column-level filters can no longer be accessed from the client application.
- Sandboxing client applications: As a next step, we enforced that individual client applications, i.e. user code, could not access each other’s data or the underlying machine. We did this by building a lightweight sandboxed execution environment for client applications using state-of-the-art sandboxing techniques based on containers. Today, each client application runs in full isolation in its own container.
Spark Executors: Sandboxed executor isolation for UDFs
Similarly to the Spark driver, Spark executors do not enforce isolation of user-defined functions (UDF). For example, a Scala UDF could write arbitrary files to the file system because of privileged access to the machine. Analogously to the client application, we sandboxed the execution environment on Spark executors in order to securely run Python and Scala UDFs. We also isolate the egress network traffic from the rest of the system. Finally, for users to be able to use their libraries in UDFs, we securely replicate the client environment into the UDF sandboxes. As a result, UDFs on shared clusters run in full isolation, and Lakeguard is also used for Python UDFs in the Databricks SQL data warehouse.
Save time and cost today with Unity Catalog and Shared Clusters
We invite you to try Shared Clusters today to collaborate with your team and save cost. Lakeguard is an integral component of Unity catalog and has been enabled for all customers using Shared Clusters, Delta Live Tables (DLT) and Databricks SQL with Unity Catalog.
Never miss a Databricks post
What's next?

Platform & Products & Announcements
December 17, 2024/2 min read
