Announcing the General Availability of Unity Catalog Volumes
Discover, govern, query and share any non-tabular data
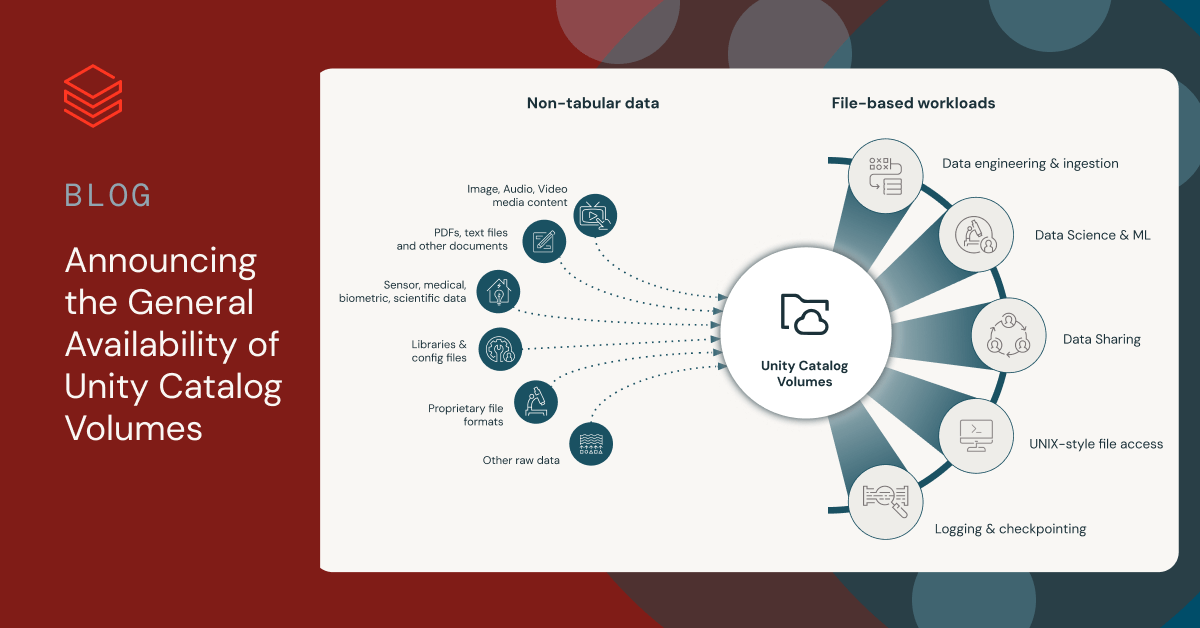
Today, we are excited to announce that Unity Catalog Volumes is now generally available on AWS, Azure, and GCP. Unity Catalog provides a unified governance solution for Data and AI, natively built into the Databricks Data Intelligence Platform. With Unity Catalog Volumes, Data and AI teams can centrally catalog, secure, manage, share, and track lineage for any type of non-tabular data, including unstructured, semi-structured, and structured data, alongside tabular data and MLmodels.
In this blog, we recap the core functionalities of Unity Catalog Volumes, provide practical examples of how they can be used to create scalable AI and ingestion applications that involve loading data from various file types and explore the enhancements introduced with the GA release.
Managing non-tabular data with Unity Catalog Volumes
Volumes are a type of object in Unity Catalog designed for the governance and management of non-tabular data. Each Volume is a collection of directories and files in Unity Catalog, acting as a logical storage unit in a Cloud object storage location. It provides capabilities for accessing, storing, and managing data in any format, whether structured, semi-structured, or unstructured.
In the Lakehouse architecture, applications usually start by importing data from files. This involves reading directories, opening and reading existing files, creating and writing new ones, as well as processing file content using different tools and libraries that are specific to each use case.
With Volumes, you can create a variety of file-based applications that read and process extensive collections of non-tabular data at cloud storage performance, regardless of their format. Unity Catalog Volumes lets you work with files using your preferred tools, including Databricks workspace UIs, Spark APIs, Databricks file system utilities (dbutils.fs), REST APIs, language-native file libraries such as Python’s os module, SQL connectors, the Databricks CLI, Databricks SDKs, Terraform, and more.
"In the journey to data democratization, streamlining the tooling available to users is a crucial step. Unity Catalog Volumes allowed us to simplify how users access unstructured data, exclusively via Databricks Volumes. With Unity Catalog Volumes, we were able to replace a complex RBAC approach to storage account access in favor of a unified access model for structured and unstructured data with Unity Catalog. Users have gone from many clicks and access methods to a single, direct access model that guarantees a more sophisticated and simpler to manage UX, both reducing risk and hardening the overall environment. " — Sergio Leoni, Head of Data Engineering & Data Platform, Plenitude
In our Public Preview blog post, we provided a detailed overview of Volumes and the use cases they enable. In what follows, we demonstrate the different capabilities of Volumes, including new features available with the GA release. We do this by showcasing two real-world scenarios that involve loading data from files. This step is essential when building AI applications or ingesting data.
Using Volumes for AI applications
AI applications often deal with large amounts of non-tabular data such as PDFs, images, videos, audio files, and other documents. This is particularly true for machine learning scenarios such as computer vision and natural language processing. Generative AI applications also fall under this category, where techniques such as Retrieval Augmented Generation (RAG) are used to extract insights from non-tabular data sources. These insights are critical in powering chatbot interfaces, customer support applications, content creation, and more.
Using Volumes provides various benefits to AI applications, including:
- Unified governance for tabular and non-tabular AI data sets: All data involved in AI applications, be it non-tabular data managed through Volumes or tabular data, is now brought together under the same Unity Catalog umbrella.
- End-to-end lineage across AI applications: The lineage of AI applications now extends from the enterprise knowledge base organized as Unity Catalog Volumes and tables, through data pipelines, model fine-tuning and other customizations, all the way to model serving endpoints or endpoints hosting RAG chains in Generative AI. This allows for full traceability, auditability, and accelerated root-cause analysis of AI applications.
- Simplified developer experience: Many AI libraries and frameworks do not natively support Cloud object storage APIs and instead expect files on the local file system. Volumes’ built-in support for FUSE allows users to seamlessly leverage these libraries while working with files in familiar ways.
- Streamlined syncing of AI application responses to your source data sets: With features such as Job file arrival triggers or Auto Loader’s file detection, now enhanced to support Volumes, you can ensure that your AI application responses are up-to-date by automatically updating them with the latest files added to a Volume.
As an example, let's consider RAG applications. When incorporating enterprise data into such an AI application, one of the initial stages is to upload and process documents. This process is simplified by using Volumes. Once raw files are added to a Volume, the source data is broken down into smaller chunks, converted into a numeric format through embedding, and then stored in a vector database. By using Vector Search and Large Language Models (LLMs), the RAG application will thus provide relevant responses when users query the data.
In what follows, we demonstrate the initial steps of creating an RAG application, starting from a collection of PDF files stored locally on the computer. For the complete RAG application, see the related blog post and demo.
We start by uploading the PDF files compressed into a zip file. For the sake of simplicity, we use the CLI to upload the PDFs though similar steps can be taken using other tools like REST APIs or the Databricks SDK. We begin by listing the Volume to decide the upload destination, then create a directory for our files, and finally, upload the archive to this new directory:
Now, we unzip the archive from a Databricks notebook. Given Volumes’ built-in FUSE support, we can run the command directly where the files are located inside the Volume:
Using Python UDFs, we extract the PDF text, chunk it, and create embeddings. The gen_chunks UDF takes a Volume path and outputs text chunks. The gen_embedding UDF processes a text chunk to return a vector embedding.
We then use the UDFs in combination with Auto Loader to load the chunks into a Delta table, as shown below. This Delta table must be linked with a Vector Search index, an essential component of a RAG application. For brevity, we refer the reader to a related tutorial for the steps required to configure the index.
In a production setting, RAG applications often rely on extensive knowledge bases of non-tabular data that are constantly changing. Thus, it is crucial to automate the update of the Vector Search index with the latest data to keep application responses current and prevent any data duplication. To achieve this, we can create a Databricks Workflows pipeline that automates the processing of source files using code logic, as previously described. If we additionally configure the Volume as a monitored location for file arrival triggers, the pipeline will automatically process new files once added to a Volume. Various methods can be used to regularly upload these files, such as CLI commands, the UI, REST APIs, or SDKs.
Aside from internal data, enterprises may also leverage externally provisioned data, such as curated datasets or data purchased from partners and vendors. By using Volume Sharing, you can incorporate such datasets into RAG applications without first having to copy the data. Check out the demo below to see Volume Sharing in action.
Using Volumes at the start of your ingestion pipelines
In the previous section, we demonstrated how to load data from unstructured file formats stored in a Volume. You can just as well use Volumes for loading data from semi-structured formats like JSON or CSV or structured formats like Parquet, which is a common first step during ingestion and ETL tasks.
You can use Volumes to load data into a table using your preferred ingestion tools, including Auto Loader, Delta Live Tables (DLT), COPY INTO, or by running CTAS commands. Additionally, you can ensure that your tables are updated automatically when new files are added to a Volume by leveraging features such as Job file arrival triggers or Auto Loader file detection. Ingestion workloads involving Volumes can be executed from the Databricks workspace or an SQL connector.
Here are a few examples of using Volumes in CTAS, COPY INTO, and DLT commands. Using Auto Loader is quite similar to the code samples we covered in the previous section.
You can also quickly load data from Volumes into a table from the UI using our newly introduced table creation wizard for Volumes. This is especially helpful for ad-hoc data science tasks when you want to create a table quickly using the UI without needing to write any code. The process is demonstrated in the screenshot below.

Unity Catalog Volumes GA Release in a Nutshell
The general availability release of Volumes includes several new features and enhancements, some of which have been demonstrated in the previous section. Summarized, the GA release includes:
- Volume Sharing with Delta Sharing and Volumes in the Databricks Marketplace: Now, you can share Volumes through Delta Sharing. This enables customers to securely share extensive collections of non-tabular data, such as PDFs, images, videos, audio files, and other documents and assets, along with tables, notebooks, and AI models, across clouds, regions, and accounts. It also simplifies collaboration between business units or partners, as well as the onboarding of new collaborators. Additionally, customers can leverage Volumes sharing in Databricks Marketplace, making it easy for data providers to share any non-tabular data with data consumers. Volume Sharing is now in Public Preview across AWS, Azure, and GCP.
- File management using tool of your choice: You can run file management operations such as uploading, downloading, deleting, managing directories, or listing files using the Databricks CLI (AWS | Azure | GCP), the Files REST API (AWS | Azure | GCP) – now in Public Preview, and the Databricks SDKs for (AWS | Azure | GCP). Additionally, the Python, Go, Node.js, and JDBC Databricks SQL connectors provide the PUT, GET, and REMOVE SQL commands that allow for the uploading, downloading, and deleting of files stored in a Volume (AWS | Azure | GCP), with support for ODBC coming soon.
- Volumes support in Scala and Python UDFs and Scala IO: You can now access Volume paths from UDFs and execute IO operations in Scala across all compute access modes (AWS | Azure | GCP).
- Job file arrival triggers support for Volumes: You can now configure Job file arrival triggers for storage accessed through Volumes (AWS | Azure | GCP), a convenient way to trigger complex pipelines when new files are added to a Volume.
- Access files using Cloud storage URIs: You can now access data in external Volumes using Cloud storage URIs, in addition to the Databricks Volume paths (AWS | Azure | GCP). This makes it easier to use existing code when you get started in adopting Volumes.
- Cluster libraries, job dependencies, and init scripts support for Volumes: Volumes are now supported as a source for cluster libraries, job dependencies, and init scripts from both the UI and APIs. Refer to this related blog post for more details.
- Discovery Tags. You can now define and manage Volume-level tagging using the UI, SQL commands, and information schema (AWS | Azure | GCP).
- Enhancements of the Volumes UI. The Volumes UI has been upgraded to support various file management operations, including creating tables from files and downloading and deleting multiple files at once. We’ve also increased the maximum file size for uploads and downloads from 2 GB to 5 GB.
Getting Started with Volumes
To get started with Volumes, follow our comprehensive step-by-step guide for a quick tour of the key Volume features. Refer to our documentation for detailed instructions on creating your first Volume (AWS | Azure | GCP). Once you've created a Volume, you can leverage the Catalog Explorer (AWS | Azure | GCP) to explore its contents, use the SQL syntax for Volume management (AWS | Azure | GCP), or share Volumes with other collaborators (AWS | Azure | GCP). We also encourage you to review our best practices (AWS | Azure | GCP) to make the most out of your Volumes.
Never miss a Databricks post
What's next?

Platform & Products & Announcements
December 17, 2024/2 min read
