Big Book of MLOps Updated for Generative AI
Comprehensive refresh including new developments for Data Science and ML practitioners for the world of GenAI and Databricks AI
by Joseph Bradley, Niall Turbitt, Michael Shtelma, Rafi Kurlansik and Matthew Thomson
Last year, we published the Big Book of MLOps, outlining guiding principles, design considerations, and reference architectures for Machine Learning Operations (MLOps). Since then, Databricks has added key features simplifying MLOps, and Generative AI has brought new requirements to MLOps platforms and processes. We are excited to announce a new version of the Big Book of MLOps covering these product updates and Generative AI requirements.
This blog post highlights key updates in the eBook, which can be downloaded here. We provide updates on governance, serving, and monitoring and discuss the accompanying design decisions to make. We reflect these updates in improved reference architectures. We also include a new section on LLMOps (MLOps for Large Language Models), where we discuss implications on MLOps, key components of LLM-powered applications, and LLM-specific reference architectures.
This blog post and eBook will be useful to ML Engineers, ML Architects, and other roles looking to understand the latest in MLOps and the impact of Generative AI on MLOps.
The rest of the blog post is structured as follows:
- Big Book v1 recap
- We recap the core principles and concepts covered in the first edition of the Big Book of MLOps.
- What's new?
- We outline new features introduced since the first edition, and how they impact MLOps on Databricks.
- Reference architectures
- We present our prescribed MLOps reference architecture, taking new features and recommendations into consideration.
- LLMOps
- We unpack key changes required for Generative AI models, specifically looking at LLM-powered applications.
- Get started updating your MLOps architecture
- Resources to learn more about MLOps and LLMOps on Databricks.
- Resources to learn more about MLOps and LLMOps on Databricks.
Big Book v1 recap
If you have not read the original Big Book of MLOps, this section gives a brief recap. The same motivations, guiding principles, semantics, and deployment patterns form the basis of our updated MLOps best practices.
Why should I care about MLOps?
We keep our definition of MLOps as a set of processes and automation to manage data, code and models to meet the two goals of stable performance and long-term efficiency in ML systems.
MLOps = DataOps + DevOps + ModelOps
In our experience working with customers like CareSource and Walgreens, implementing MLOps architectures accelerates the time to production for ML-powered applications, reduces the risk of poor performance and non-compliance, and reduces long-term maintenance burdens on Data Science and ML teams.
Guiding principles
Our guiding principles remain the same:
- Take a data-centric approach to machine learning.
- Always keep your business goals in mind.
- Implement MLOps in a modular fashion.
- Process should guide automation.
The first principle, taking a data-centric approach, lies at the heart of the updates in the eBook. As you read below, you will see how our "Lakehouse AI" philosophy unifies data and AI at both the governance and model/pipeline layers.
Semantics of development, staging and production
We structure MLOps in terms of how ML assets—code, data, and models—are organized into stages from development, to staging, and to production. These stages correspond to steadily stricter access controls and stronger quality guarantees.

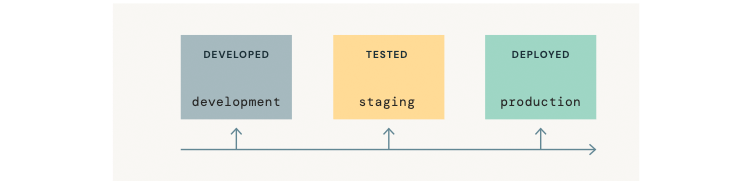
ML deployment patterns
We discussed how code and/or models are deployed from development towards production, and the tradeoffs in deploying code, models, or both. We show architectures for deploying code, but our guidance remains largely the same for deploying models.
For more details on any of these topics, please refer to the original eBook.
What's new?
In this section, we outline the key product features that improve our MLOps architecture. For each of these, we highlight the benefits they bring and their impact on our end-to-end MLOps workflow.
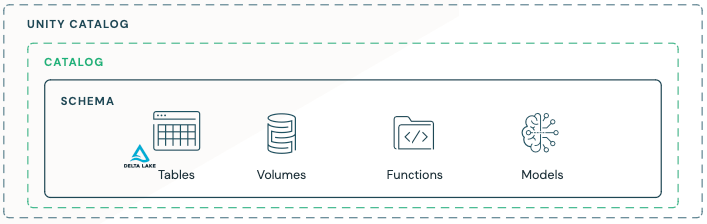
Unity Catalog
A data-centric AI platform must provide unified governance for both data and AI assets on top of the Lakehouse. Databricks Unity Catalog centralizes access control, auditing, lineage, and data discovery capabilities across Databricks workspaces.
Unity Catalog now includes MLflow Models and Feature Engineering. This unification allows simpler management of AI projects which include both data and AI assets. For ML teams, this means more efficient access and scalable processes, especially for lineage, discovery, and collaboration. For administrators, this means simpler governance at project or workflow level.
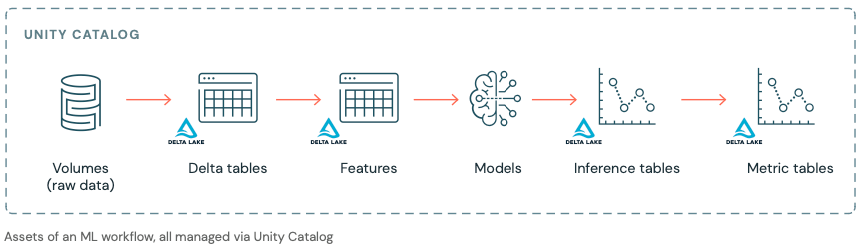
Within Unity Catalog, a given catalog contains schemas, which in turn may contain tables, volumes, functions, models, and other assets. Models can have multiple versions and can be tagged with aliases. In the eBook, we provide recommended organization schemes for AI projects at the catalog and schema level, but Unity Catalog has the flexibility to be tailored to any organization's existing practices.
Model Serving
Databricks Model Serving provides a production-ready, serverless solution to simplify real-time model deployment, behind APIs to power applications and websites. Model Serving reduces operational costs, streamlines the ML lifecycle, and makes it easier for Data Science teams to focus on the core task of integrating production-grade real-time ML into their solutions.
In the eBook, we discuss two key design decision areas:
- Pre-deployment testing ensures good system performance and generally includes deployment readiness checks and load testing.
- Real-time model deployment ensures good model accuracy (or other ML performance metrics). We discuss techniques including A/B testing, gradual rollout, and shadow deployment.
We also discuss implementation details in Databricks, including:
- Using model aliases for tracking champion vs. challenger models
- Controlling endpoint traffic for implementing different real-time deployment techniques
- Integrating Lakehouse Monitoring with Model Serving via inference tables
Lakehouse Monitoring
Databricks Data Quality Monitoring is a data-centric monitoring solution to ensure that both data and AI assets are of high quality and reliable. Built on top of Unity Catalog, it provides the unique ability to implement both data and model monitoring, while maintaining lineage between the data and AI assets of an MLOps solution. This unified and centralized approach to monitoring simplifies the process of diagnosing errors, detecting quality drift, and performing root cause analysis.
The eBook discusses implementation details in Databricks, including:
- Using metric tables produced by Lakehouse Monitoring
- Scheduling automatic refreshes of monitoring tables
- Customizing monitoring with user-defined metrics and data slices
- Using the generated Databricks SQL dashboard and setting alerts
MLOps Stacks and Databricks asset bundles
MLOps Stacks are updated infrastructure-as-code solutions which help to accelerate the creation of MLOps architectures. This repository provides a customizable stack for starting new ML projects on Databricks, instantiating pipelines for model training, model deployment, CI/CD, and others.
MLOps Stacks are built on top of Databricks asset bundles, which define infrastructure-as-code for data, analytics, and ML. Databricks asset bundles allow you to validate, deploy, and run Databricks workflows such as Databricks jobs and Delta Live Tables, and to manage ML assets such as MLflow models and experiments.
Reference architectures
The updated eBook provides several reference architectures:
- Multi-environment view: This high-level view shows how the development, staging, and production environments are tied together and interact.
- Development: This diagram zooms in on the development process of ML pipelines.
- Staging: This diagram explains the unit tests and integration tests for ML pipelines.
- Production: This diagram details the target state, showing how the various ML pipelines interact.
Below, we provide a multi-environment view. Much of the architecture remains the same, but it is now even easier to implement with the latest updates from Databricks.
- Top-to-bottom: The three layers show code in Git (top) vs. workspaces (middle) vs. Lakehouse assets in Unity Catalog (bottom).
- Left-to-right: The three stages are shown in three different workspaces; that is not a strict requirement but is a common way to separate stages from development to production. The same set of ML pipelines and services are used in each stage, initially developed (left) before being tested in staging (middle) and finally deployed to production (right).
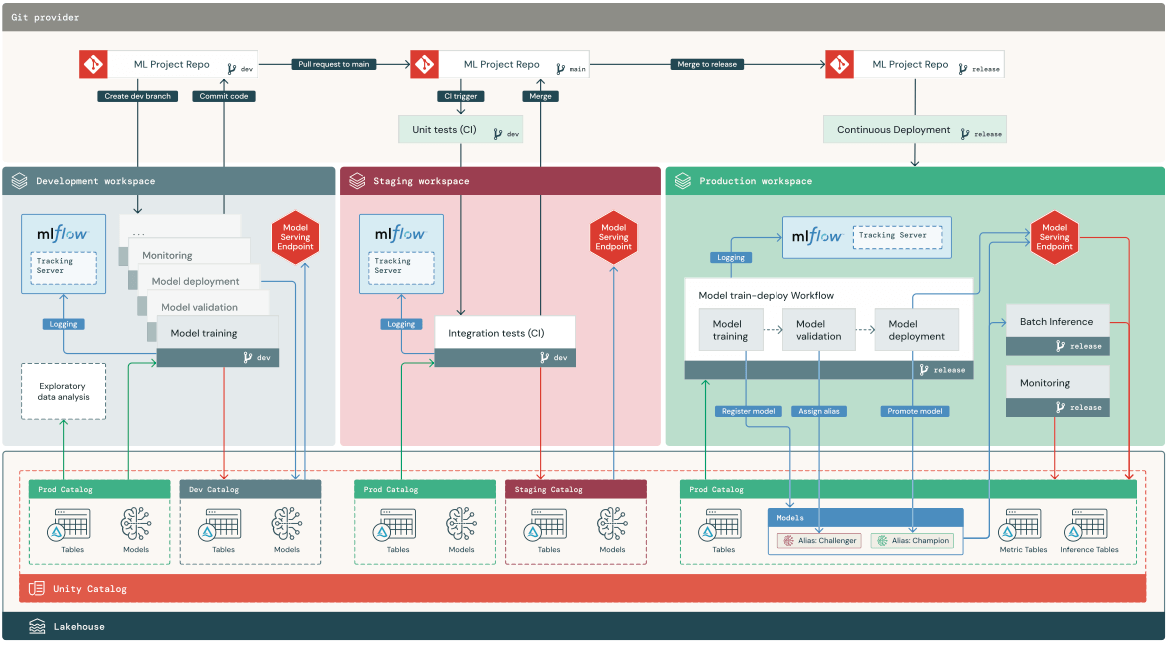

The main architectural update is that both data and ML assets are managed as Lakehouse assets in the Unity Catalog. Note that the big improvements to Model Serving and Lakehouse Monitoring have not changed the architecture, but make it simpler to implement.
LLMOps
We end the updated eBook with a new section on LLMOps, or MLOps for Large Language Models (LLMs). We speak in terms of "LLMs," but many best practices translate to other Generative AI models as well. We first discuss major changes introduced by LLMs and then provide detailed best practices around key components of LLM-powered applications. The eBook also provides reference architectures for common Retrieval-Augmented Generation (RAG) applications.
What changes with LLMs?
The table below is an abbreviated version of the eBook table, which lists key properties of LLMs and their implications for MLOps platforms and practices.
| Key properties of LLMs | Implications for MLOps |
|---|---|
Implications for MLOps
| Development process: Projects often develop incrementally, starting from existing, third-party or open source models and ending with custom models (fine-tuned or fully trained on curated data). |
| Many LLMs take general queries and instructions as input. Those queries can contain carefully engineered "prompts" to elicit the desired responses. | Development process: Prompt engineering is a new important part of developing many AI applications. Packaging ML artifacts: LLM "models" may be diverse, including API calls, prompt templates, chains, and more. |
| Many LLMs can be given prompts with examples or context. | Serving infrastructure: When augmenting LLM queries with context, it is valuable to use tools such as vector databases to search for relevant context. |
| Proprietary and OSS models can be used via paid APIs. | API governance: It is important to have a centralized system for API governance of rate limits, permissions, quota allocation, and cost attribution. |
| LLMs are very large deep learning models, often ranging from gigabytes to hundreds of gigabytes. | Serving infrastructure: GPUs and fast storage are often essential. Cost/performance trade-offs: Specialized techniques for reducing model size and computation have become more important. |
| LLMs are hard to evaluate via traditional ML metrics since there is often no single "right" answer. | Human feedback: This feedback should be incorporated directly into the MLOps process, including testing, monitoring, and capturing for use in future fine-tuning. |
Key components of LLM-powered applications
The eBook includes a section for each topic below, with detailed explanations and links to resources.
- Prompt engineering: Though many prompts are specific to individual LLM models, we give some tips which apply more generally.
- Leveraging your own data: We provide a table and discussion of the continuum from simple (and fast) to complex (and powerful) for using your data to gain a competitive edge with LLMs. This ranges from prompt engineering, to retrieval augmented generation (RAG), to fine-tuning, to full pre-training.
- Retrieval augmented generation (RAG): We discuss this most common type of LLM application, including its benefits and the typical workflow.
- Vector database: We discuss vector indexes vs. vector libraries vs. vector databases, especially for RAG workflows.
- Fine-tuning LLMs: We discuss variants of fine-tuning, when to use it, and state-of-the-art techniques for scalable and resource-efficient fine-tuning.
- Pre-training: We discuss when to go for full-on pre-training and reference state-of-the art techniques for handling challenges. We also strongly encourage the use of MosaicML Training, which automatically handles many of the complexities of scale.
- Third-party APIs vs. self-hosted models: We discuss the tradeoffs around data security and privacy, predictable and stable behavior, and vendor lock-in.
- Model evaluation: We touch on the challenges in this nascent field and discuss benchmarks, using LLMs as evaluators, and human evaluation.
- Packaging models or pipelines for deployment: With LLM applications using anything from API calls to prompt templates to complex chains, we provide advice on using MLflow Models to standardize packaging for deployment.
- LLM Inference: We provide tips around real-time inference and batch inference, including using large models.
- Managing cost/performance trade-offs: With LLMs being large models, we dedicate this section to reducing costs and improving performance, especially for inference.
Get started updating your MLOps architecture
This blog is merely an overview of the explanations, best practices, and architectural guidance in the full eBook. To learn more and to get started on updating your MLOps platform and practices, we recommend that you:
- Read the updated Big Book of MLOps. Throughout the eBook, we provide links to resources for details and for learning more about specific topics.
- Catch up on the Data+AI Summit 2023 talks on MLOps, including:
- Wednesday keynote on Lakehouse IQ, MosaicML, and Lakehouse AI, as well as JetBlue's personal story
- Databricks vision and product updates
- LLMOps: Everything You Need to Know to Manage LLMs, which overviews the Databricks vision for developing LLM-powered applications
- Deep Dive into the Latest Lakehouse AI Capabilities
- Advancements in Open Source LLM Tooling, Including MLflow
- Key Insights From Running LLMs in Production From MLOps.Community
- Read and watch about success stories:
- CareSource on their MLOps platform for improving healthcare
- Walgreens Boots Alliance on the details of their MLOps architecture
- Gucci on their end-to-end MLOps architecture
- Ahold Delhaize on their move to Serverless Model Serving
- The Trade Desk on scaling NLP for 100 million web pages per day
- Speak with your Databricks account team, who can guide you through a discussion of your requirements, help to adapt this reference architecture to your projects, and engage more resources as needed for training and implementation.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.