DSPy on Databricks
A Framework for Programming RAG and other Compound AI Systems
by Arnav Singhvi, Michael Carbin and Matei Zaharia
Large language models (LLMs) have generated interest in effective human-AI interaction through optimizing prompting techniques. “Prompt engineering” is a growing methodology for tailoring model outputs, while advanced techniques like Retrieval Augmented Generation (RAG) enhance LLMs’ generative capabilities by fetching and responding with relevant information.
DSPy, developed by the Stanford NLP Group, has emerged as a framework for building compound AI systems through “programming, not prompting, foundation models.” DSPy now supports integrations with Databricks developer endpoints for Model Serving and Vector Search.
Engineering Compound AI
These prompting techniques signal a shift towards complex “prompting pipelines” where AI developers incorporate LLMs, retrieval models (RMs), and other components while developing compound AI systems.
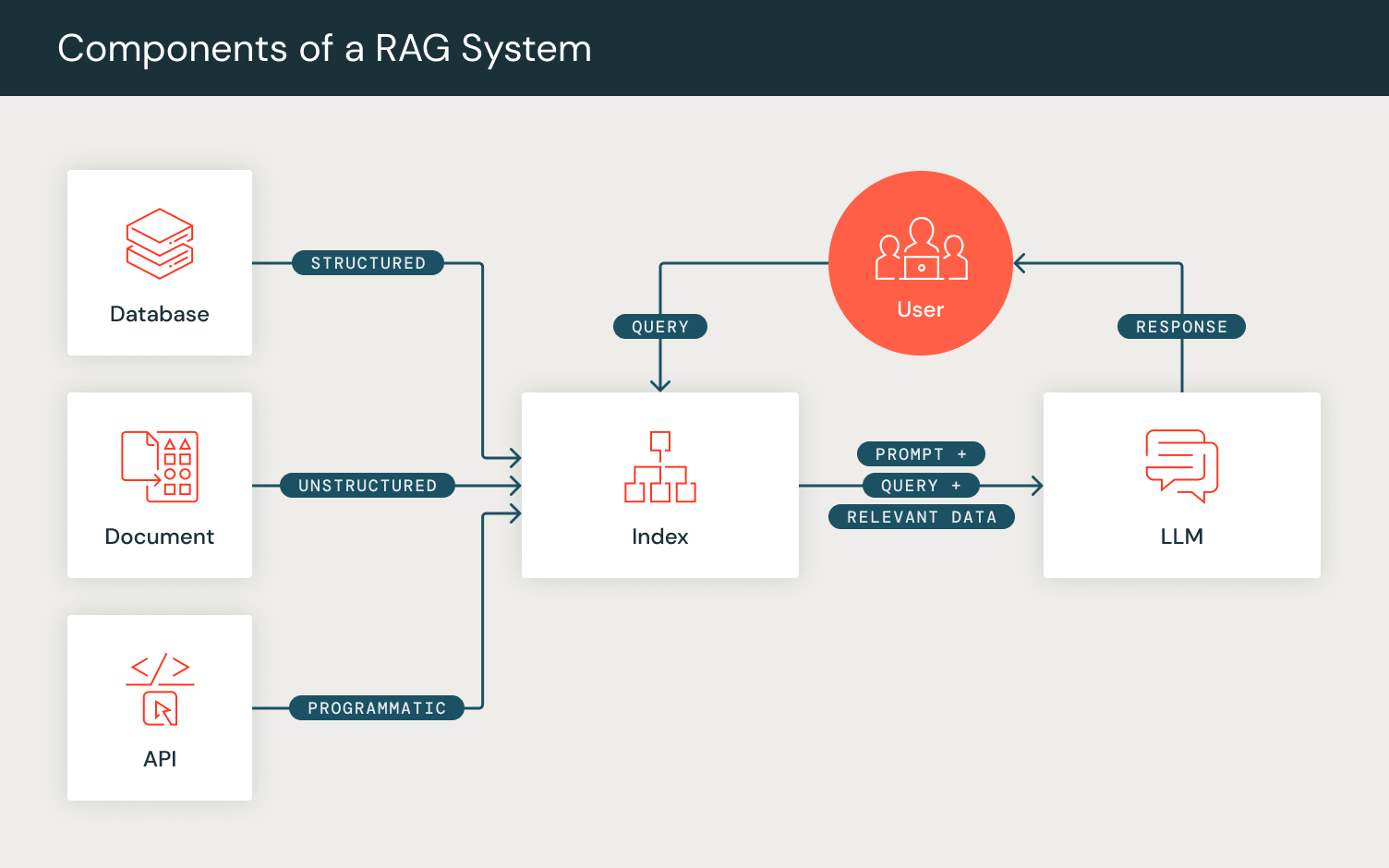
Programming not Prompting: DSPy
DSPy optimizes AI-driven systems performance by composing LLM calls alongside other computational tools towards downstream task metrics. Unlike traditional “prompt engineering,” DSPy automates prompt tuning by translating user-defined natural language signatures into complete instructions and few-shot examples. Mirroring end-to-end pipeline optimization as in PyTorch, DSPy enables users to define and compose AI systems layer by layer while optimizing for the desired objective.
Programs in DSPy have two main methods:
- Initialization: Users can define the components of their prompting pipelines as DSPy layers. For instance, to account for the steps involved in RAG, we define a retrieval layer and a generation layer.
- We define a retrieval layer `dspy.Retrieve` which uses the user-configured RM to retrieve a set of relevant passages/documents for an inputted search query.
- We then initialize our generation layer, for which we use the `dspy.Predict` module, which internally prepares the prompt for generation. To configure this generation layer, we define our RAG task in a natural language signature format, specified by a set of input fields (“context, query”) and the expected output field (“answer”). This module then internally formats the prompt to match this defined formatting, and then returns the generation from the user-configured LM.
- Forward: Akin to PyTorch forward passes, the DSPy program forward function allows for user composition of the prompting pipeline logic. By using the layers we initialized, we set up the computational flow of RAG by retrieving a set of passages given a query and then using these passages as context alongside the query to generate an answer, outputting the expected output in a DSPy dictionary object.
Let’s take a look at RAG in action using the DSPy program and DBRX’s generation.
For this example, we use a sample question from the HotPotQA Dataset which includes questions that require multiple steps to deduce the correct answer.
Let’s first configure our LM and RM in DSPy. DSPy offers a variety of language and retrieval model integrations, and users can set these parameters to ensure any DSPy defined program runs through these configurations.
Let’s now declare our defined DSPy RAG program and simply pass in the question as the input.
During the retrieval step, the query is passed to the self.retrieve layer which outputs the top-3 relevant passages, which are internally formatted as below:
With these retrieved passages, we can pass this alongside our query into the dspy.Predict module self.generate_answer, matching the natural language signature input fields “context, query”. This internally applies some basic formatting and phrasing, and enables you to direct the model with your exact task description without prompt engineering the LM.
Once the formatting is declared, the input fields “context” and “query” are populated and the final prompt is sent to DBRX:
DBRX generates an answer which is populated in the Answer: field, and we can observe this prompt-generation through calling:
This outputs the last prompt-generation from the LM with the generated answer “Steve Yzerman”, which is the correct answer!
DSPy has been widely used across various language model tasks such as fine-tuning, in-context learning, information extraction, self-refinement, and numerous others. This automated approach outperforms standard few-shot prompting with human-written demonstrations by up to 46% for GPT-3.5 and 65% for Llama2-13b-chat on natural language tasks like multi-hop RAG and math benchmarks like GSM8K.
DSPy on Databricks
DSPy now supports integrations with Databricks developer endpoints for Model Serving and Vector Search. Users can configure Databricks-hosted foundation model APIs under the OpenAI SDK through dspy.Databricks. This ensures users can evaluate their end-to-end DSPy pipelines on Databricks-hosted models. Currently, this supports models on the Model Serving Endpoints: chat (DBRX Instruct, Mixtral-8x7B Instruct, Llama 2 70B Chat), completion (MPT 7B Instruct) and embedding (BGE Large (En)) models.
Chat Models
Completion Models
Embedding Models
Retriever Models/Vector Search
Additionally, users can configure retriever models through Databricks Vector Search. Following the creation of a Vector Search index and endpoint, users can specify the corresponding RM parameters through dspy.DatabricksRM:
Users can configure this globally by setting the LM and RM to corresponding Databricks endpoints and running DSPy programs.
With this integration, users can build and evaluate end-to-end DSPy applications, such as RAG, using Databricks endpoints!
Check out the official DSPy GitHub repository, documentation and Discord to learn more about how to transform generative AI tasks into versatile DSPy pipelines with Databricks!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.