How to Build a Credit Data Platform on the Databricks Lakehouse
Breaking Barriers Toward Financial Inclusion


Get started and build a credit data platform for your business by visiting the demo at Databricks Demo Center.
Introduction
According to the World Bank's reporting on financial inclusion, a staggering 1.7 billion adults were deemed underbanked. Many underbanked individuals find it difficult to secure loans from traditional financial institutions, leading them to turn to informal lenders who offer loans at exorbitant interest rates. This group typically includes younger generations, low-income individuals in developing nations, and rural residents, many of which have gone mobile in order to gain financial access.
When it comes to the underbanked, mobile banking has typically stepped in to meet the consumer needs in areas where traditional banking is perceived to be weak. The number of smartphone users worldwide has consistently grown by a minimum of 5% annually over the past five years, presenting a new and promising opportunity for lending. Financial institutions need to leverage this opportunity by utilizing machine learning and other advanced analytics to assess a customer's creditworthiness and gradually build up a credit history through their platforms, expanding the scope of financial inclusion and opening doors to previously unattainable credit opportunities.
In the spirit of financial inclusion and expanding traditional thinking, this blog serves as a guide and reusable public Lakehouse demo for how banks, fintechs, and non-banks can enter the low-hanging fruit markets that are waiting and eager for better financial services.
Extending Credit - Doing Well and Doing Good are Not Mutually Exclusive
As Deloitte points out in their report on financial inclusion, 'doing well and doing good are not mutually exclusive'; this is resonating with many data teams in the industry. Let's define some terms to understand this concept better.
Credit decisioning is the process of assessing an individual's creditworthiness to determine their ability to repay a loan or credit. It is an essential part of the lending industry and involves various stages, including data collection, data processing, and data analysis and loss estimation. Traditionally, credit decisioning has been a lengthy process–even for short-term loans–which are the types of loans most commonly purchased by the underbanked. Moreover, the process is heavily biased towards those individuals with prior credit history or long-term loans. With the advent of buy-now-pay-later (BNPL) offerings, digital markets for home purchases, and non-banks offering credit, the world stage for credit decisioning has completely transformed.
As AI-assisted credit decisioning continues to advance, the banking and payment industries are witnessing a surge in customer demands for a Databricks Lakehouse design. This design offers a credit data platform that provides a holistic and efficient solution to the credit decisioning process. The platform can enable data integration, audit, AI-powered decisions, and explainability, providing a single source of truth for data analytics. The credit data platform includes machine learning models that can analyze vast amounts of data and provide more accurate predictions about a borrower's creditworthiness, improving the speed and accuracy of the credit decisioning process. The credit data platform can help fintechs, banks, or non-banks looking to offer financial services make informed credit decisions, reduce the risk of default, and offer better rates and terms to their customers. Before delving into the technology solution, we will cover the areas in which financial institutions are struggling to serve markets today.
Part I - Why Change?
Challenges in Banking
Implementing a credit data platform can be a significant challenge for banks and other financial institutions. Consider the following reasons.
Challenge #1 - Lack of existing data
Good credit modeling is a large data curation exercise.
Many underbanked individuals find it difficult to secure loans from traditional financial institutions, leading them to turn to informal lenders who offer loans at exorbitant interest rates. Credit decisioning for underbanked customers can be challenging, as these individuals may not have a traditional credit history or financial records that can be used to assess their creditworthiness. Furthermore, credit decisioning data is often stored across different sources and incompatible formats, making it difficult for data users to fully merge together and extract valuable insights. This results in data only being available to data engineers and scientists, but not to end users such as marketing and finance teams, call center agents, and bank tellers.
Challenge #2 - Security and Governance
Data without limits does not mean operating without governance.
Banks and other financial institutions face significant challenges when building a credit data platform. They must ensure that the platform is secure, compliant with regulatory requirements, and protects sensitive customer data. Achieving these goals requires addressing various challenges related to security and governance, such as data privacy, access control, quality, and compliance. However, data governance and enterprise security control can be challenging due to the complexity of data ecosystems, evolving threats, insider risks, and resource constraints. To effectively manage and secure their data, organizations must address these challenges at the foundation - it cannot be an afterthought.
Challenge #3 - Explainability and Fairness
Make your "data insights" actionable
Explainability and fairness are essential in credit decisioning because they promote unbiased and understandable decisions that protect consumers from discrimination and ensure equitable outcomes. Lack of fairness and explainability can erode trust in the credit system and discourage consumers from applying for credit. However, evaluating fairness in credit decisions and explaining outcomes can be challenging due to several factors. These include the complexity of credit scoring models, potential data biases, and potential for human biases.
Credit Decisioning Solution
In this blog, we demonstrate how setting the right data foundations through the Databricks Lakehouse can address the aforementioned challenges and enable companies to create better credit models and achieve their business goals, including serving their underbanked customers, assessing credit risk and exposure, introducing novel products such as buy-now-pay-later, and others.

Good credit models require a wide variety of data depicting the bank customers from as many angles as possible, including their spending habits, potential previous delinquencies, sources of income, and many more. We report on the left hand side of the picture the different financial data sources we need to create a modern credit decisioning platform, including credit bureau data, customer information, real-time transactional data, as well as partner data (telecom data that we use to augment the traditional banking information). It is easy to see that all data sources have totally different file formats, velocity of ingestion, volume, and source platform.
Data Unification
To solve the variety challenge, we begin with Data Unification - the ability to ingest any source of data in a single source of truth location.
- Using Delta Live Tables, a declarative framework for building reliable, maintainable, and testable data processing pipelines, we can streamline the ingestion of all these data sources into a single pipeline, storage location, and file format, Delta Lake. With capabilities such as time traveling, schema enforcement and detection, and the ability to merge streaming and batch data, Delta lake provides reliability and performance, the cornerstone of a modern data platform. All data is streaming in today's world - near real-time ingestion is table stakes, and Delta Live Tables provides a simple interface to focus on the 'what' instead of the 'how' for provisioning infrastructure.
- Data unification also means simplified governance and security since all data is in the same location and in the same format. Credit scoring requires sources that contain a lot of Personal Identifiable Information (PII). Through the Databricks Governance solution, known as Unity Catalog, we can easily achieve the highest level of security without jeopardizing the usability and consumability of the data. Unity Catalog allows us to easily apply granular table access controls (ACLs) using simple SQL statements irrespective of the format of the data, even if it is unstructured or stream, apply row- and column-level filtering and masking, and manage external locations and storage credentials.
Data Decisions
Once the proper data foundation has been set, we can move to Data Decisioning and find the hidden patterns and correlations we call "data insights":
- Effective cross-team collaboration is extremely important for successfully building data products within the financial services industry. MLFlow's glass-box AutoML capability, enhanced with the discoverability and lineage of the Databricks Feature Store and the GUI-based data profiling and dashboarding integrated in the Databricks Notebooks, allows to very quickly create a baseline model through automated experimentation, model selection, and hyperparameter tuning.
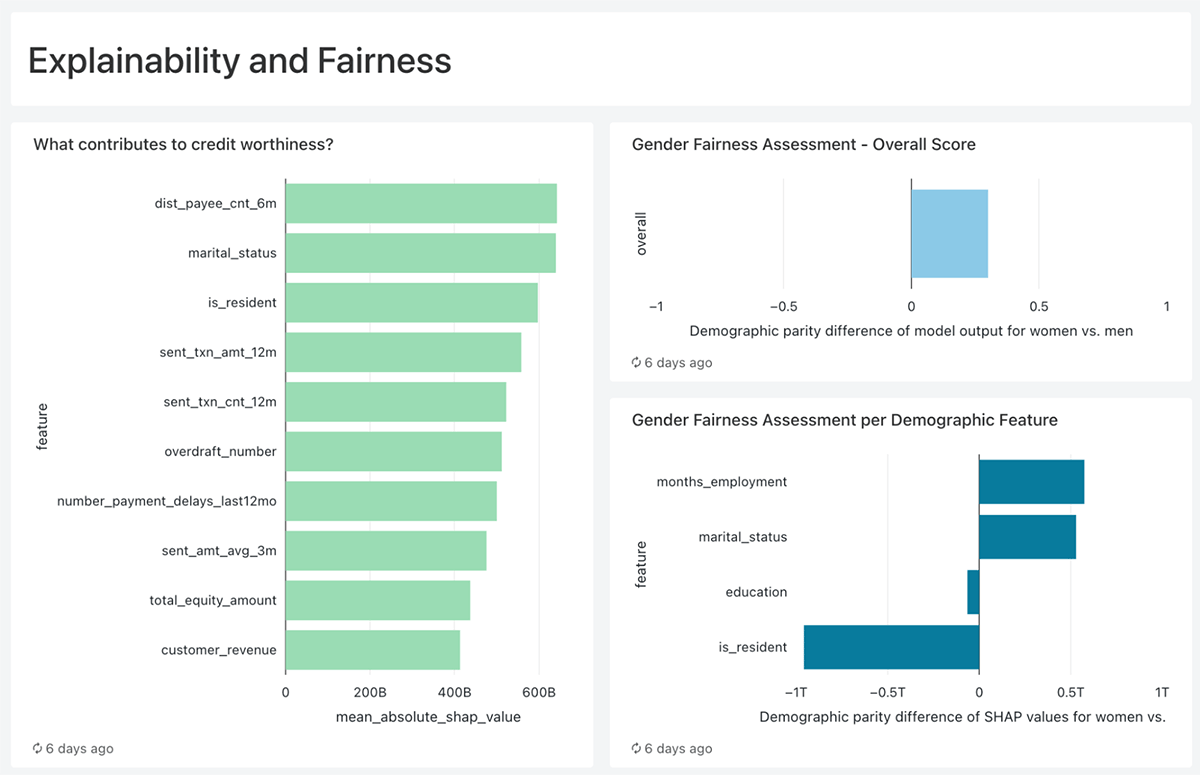
- As we already mentioned, if the data insights and machine learning predictions are not explainable, fair, and actionable, it is very likely that they will only stay in the Notebooks. In this demo, we use SHAP (SHapley Additive exPlanations) to tie back statistics to business processes by offering details such as "What contributes to credit worthiness?" or "Why a particular customer will default" making it easier for credit agents and marketing teams to address each person individually.
Data Democratization
Nowadays, data is accessible and usable only by the data teams, such as data scientists and data engineers. Data teams, however, are not the end users of a use case, such as the credit decisioning - it is the credit agents evaluating an application, call center agents communicating with a customer, or marketing teams preparing promotional materials for upselling the underbanked customers. These personas, however, more often than not, do not have access neither to the data nor to dashboards or machine learning predictions. In the old days, data teams would export any requested data to csv or pdf files and send it to the business users over email. This approach is not secure, scalable, or simple.
Unity Catalog and Databricks data warehousing solution, Databricks SQL, allows financial services organizations to "democratize" their data and insights and allow access to them by not only data users but everyone in the organization through capabilities such as the BI visualizations and Delta Sharing, an open protocol for securely live sharing of any data with no replication, centralized governance, an cross-platform recipients.
Databricks Lakehouse for Financial Services
The combination of data and user unification, actionable decisioning, and data democratization are the fundamentals of the Databricks Lakehouse for Financial Services. It is the ultimate democratization of data access without sacrificing security and governance, as we will show.

Business Outcomes
To start our tour of the Lakehouse demo for credit decisioning, we want to show the impact any financial institution can achieve. In unifying our data and making it available for analytics, we are driving business outcomes that bring in new clients, a win for both FSIs and prospects alike.
Upselling and serving the underbanked customers
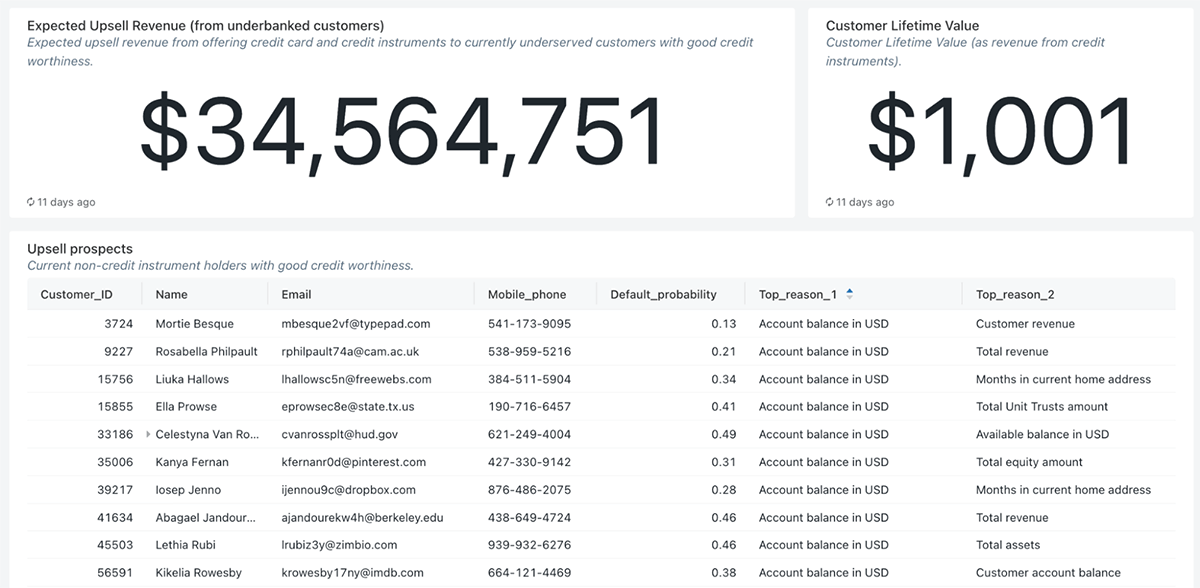
Through dashboarding capabilities enriched with customer lifetime values models (CLV), we can easily report the financial benefits of identifying and serving creditworthy customers (underbanked) who currently do not have any credit instruments with the bank. The dashboard combines raw data, machine learning predictions, as well as explainability information, not only identifying the probability of default for each underbanked customer but also the top three reasons unique to each customer, making it very actionable for credit agents evaluating the creditworthiness as well as the marketing team communicating with the customers. Finally, as reported below, we also offer a way to assess the fairness of our credit scoring models and make sure we do not disadvantage any groups of customers.
Part II - How to Serve More Clients with the Lakehouse Architecture
Building the Platform
In this section we will go even deeper into the technical implementation and architecture of the credit decisioning demo and see how the Lakehouse helps financial organizations use their data to achieve their business goals.
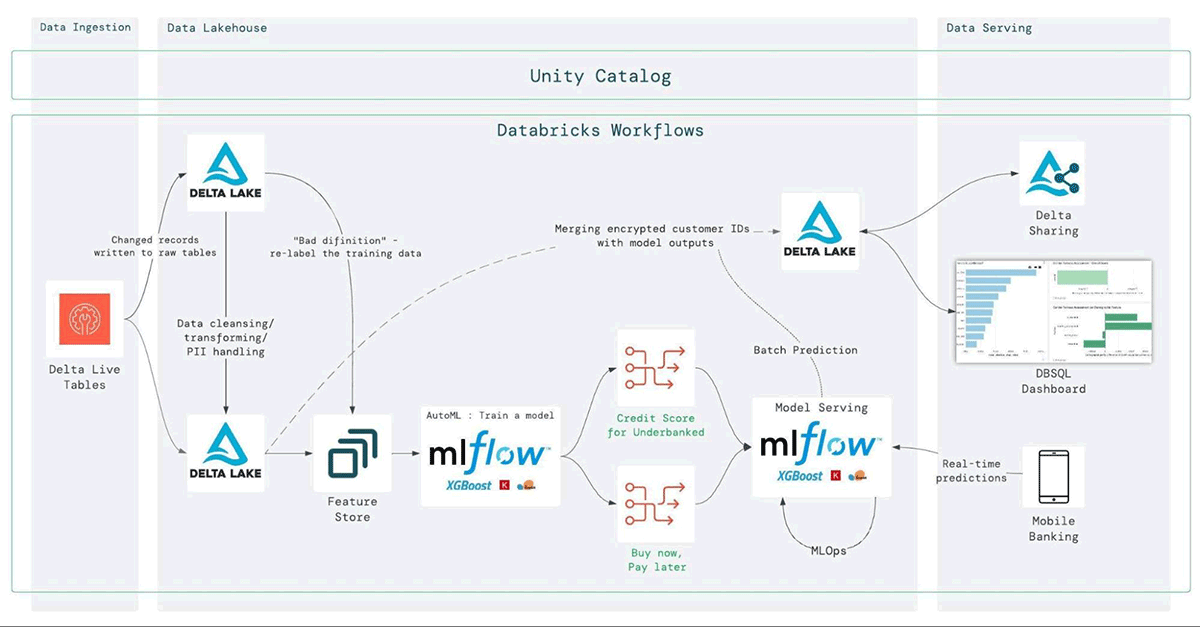
The picture above depicts the actual architecture of the credit decisioning solution and shows how we achieve the aforementioned goals, including data unification, governance, and democratization.
- Starting with the ingestion, we use Delta Live Tables (DLT) to connect to the various sources (below) and ingest them into a single source of truth location. DLT has several other capabilities making it an extremely easy to use data engineering tool, including automated data quality checks and reports, autoscaling, schema detection, execution scheduling, deep monitoring and observability, and others. Using DLT we can easily clean and curate the ingested data (into the silver and gold layers).
Data engineering teams no longer need various tools, languages, platforms, or services to streamline ETL processes. All they need is python or SQL to handle the ingestion and transformation of any data source, be it structured, unstructured, or in the form of a stream. This way, DLT significantly simplifies the data architecture, reduces the time and effort required, minimizes the data quality problems, and overall, helps the data teams work more effectively towards their organizations' data goals.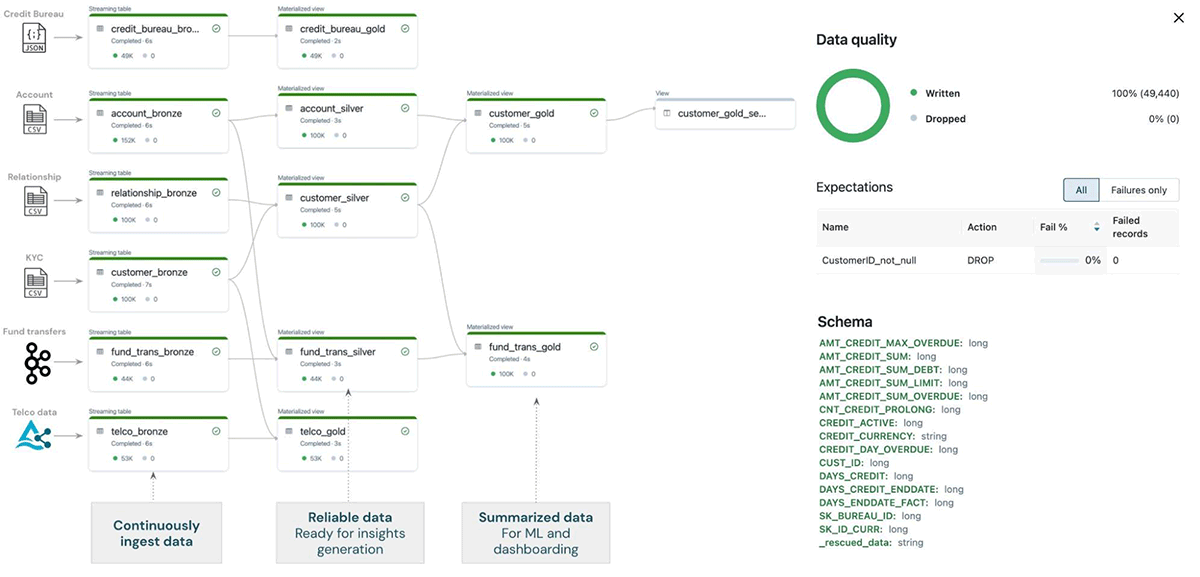
- The next step is to properly secure the data while making it discoverable and consumable. The Lakehouse makes it easy to achieve a fine grained governance on all users and data. Historically, it was difficult to unify data governance and security as data was spread across multiple locations and formats. In the Lakehouse, all data is in one place and one format (be it unstructured, structured, or stream), hence achieving overall governance is much simpler to achieve.
As an example, in the picture below we can see how simple it is to implement row level masking on sensitive data using simple SQL statements. In this scenario we want to make sure that users from the "data-scientists" group cannot see the actual first names of the bank's customers, hence we mask the column. Everyone else, on the other hand, is able to see these names.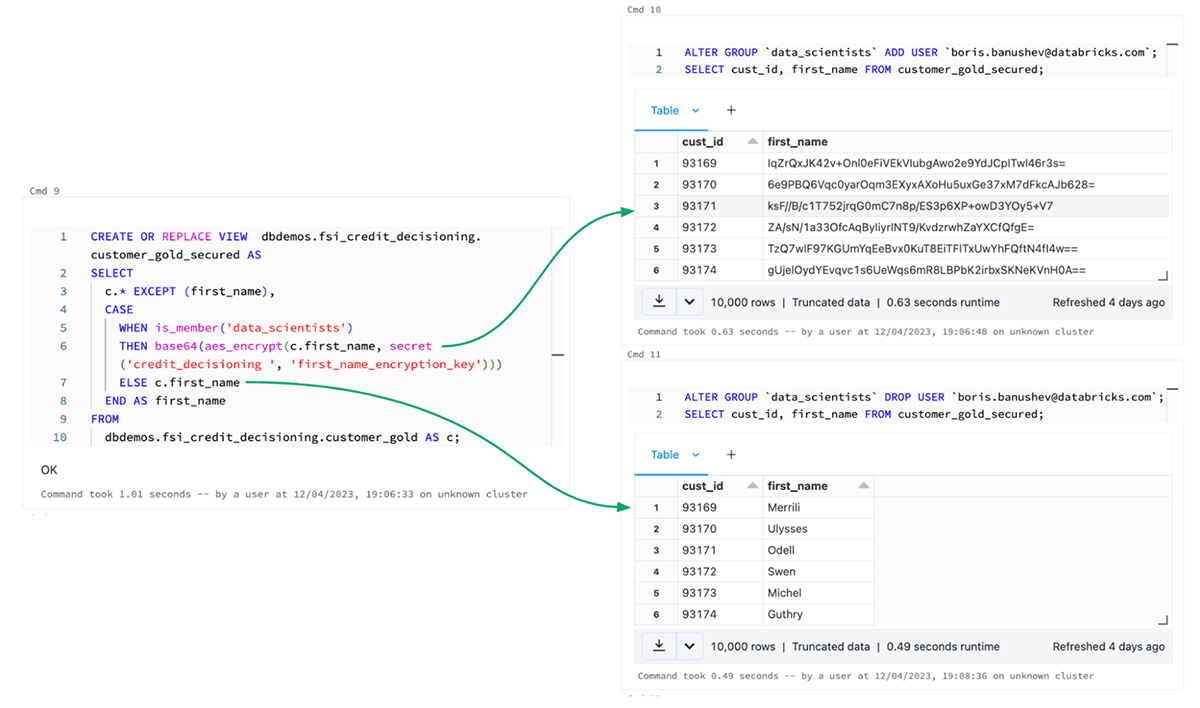
- Now that all required data has been ingested, cleaned, and properly secured and governed, we can move to exploratory data analysis (EDA) and feature engineering. We store the features into the Databricks Feature Store to have a centralized repository and share features and also ensure that the same code used to compute the feature values is used for model training and inference.This will also enable us to achieve the same level of quality, discoverability and governance for our feature sets as the Databricks Feature Store is also built on top of Delta tables.
In the picture below we can see the automated dashboarding in the Databricks Notebooks. This feature, along with the automated data profiling, the ability for many people to work in the same Notebook in different languages (SQL and python), and the embedded repository features for full CI/CD, makes cross team collaboration extremely fast on the Lakehouse. The ability to experiment quickly through feature engineering and model training is a key to producing high quality machine learning models.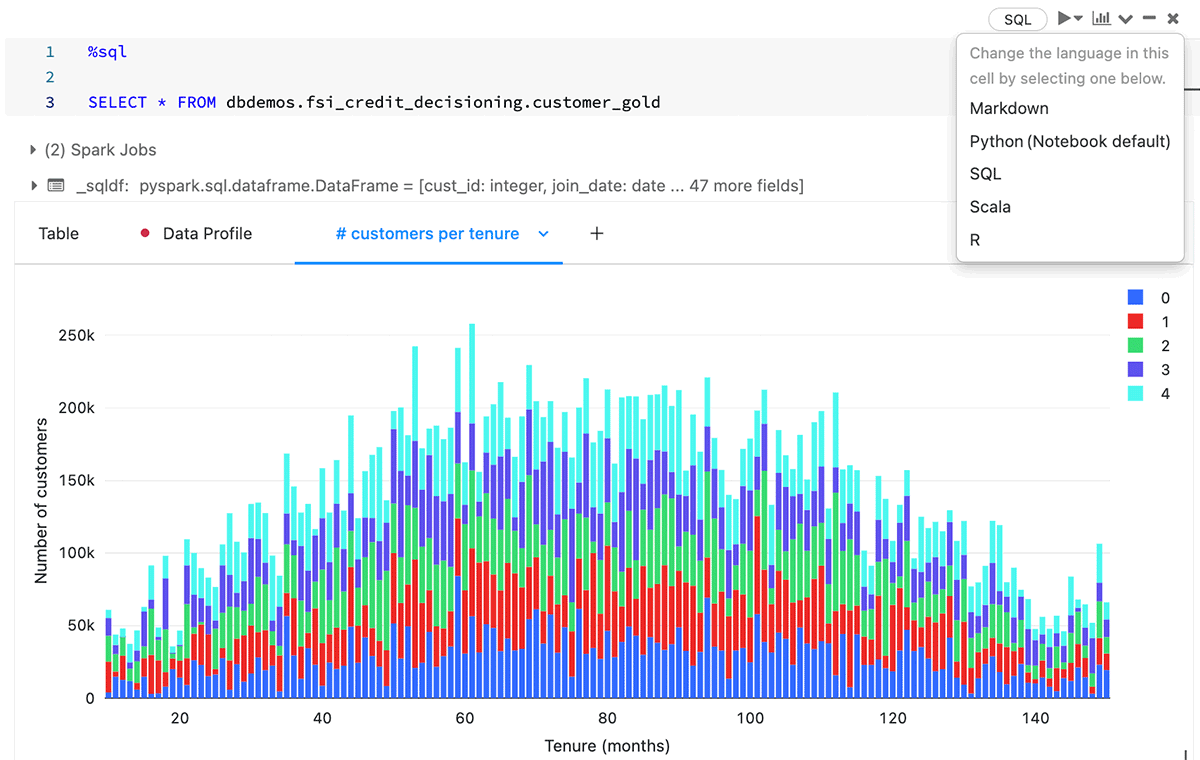
- Once the features are generated we can use Databricks's glass-blox AutoML capability to build a baseline model through automated model selection and hyperparameter tuning. MLFlow makes it easy to compare hundreds of models, evaluate them based on dozens of metrics (in the picture below), quickly deploy models for batch and real-time inferencing using MLOps best practices, monitor these models for data and concept drifts, and even achieve A/B test deployment.
The batch inferencing in this solution is used for predicting the creditworthiness of underbanked customers and also the probability of default (and the loss-given default) of current debt holders. The real-time inferencing is used in a Buy now, Pay later use case, where the customer does not have the required amount to complete a financial transaction and the bank wants to calculate in real-time whether the customer's credit limit can be temporarily increased so that the transaction is completed. - The next step is to use Databricks SQL and visualize all data and machine learning predictions together. We already saw some dashboards built on the Lakehouse in the business outcomes sections of the blog.
- As mentioned above, it is important to be able to empower not only data teams, but non-data teams and business users to access any data they need, since the end users of a credit decision or default prediction are not the data scientists and engineers, but the business users. The latter, however, do not often have access to this information in a timely and structured manner. Through Delta Sharing, financial institutions can securely share any data with any recipient even if they are not Databricks users.
- In order to productionalize everything into a single data pipeline containing data ingestion, ELT, machine learning training and deploying, data sharing and dashboarding we use Databricks Workflows. Workflows create robust pipelines of various data assets - be it a Databricks Notebook, DBSQL Dashboard, DLT pipelines, or python files, everything can work together in a unified workflow.
- Finally, let's use the unified data lineage that Databricks Unity Catalog automatically captures (in the picture below). We can see that in the same lineage graph we can find absolutely any data asset, including the ingested and cleaned data through DLT, the feature sets stored in the Feature Store, as well as the batch predictions created by MLFlow after training the machine learning model.
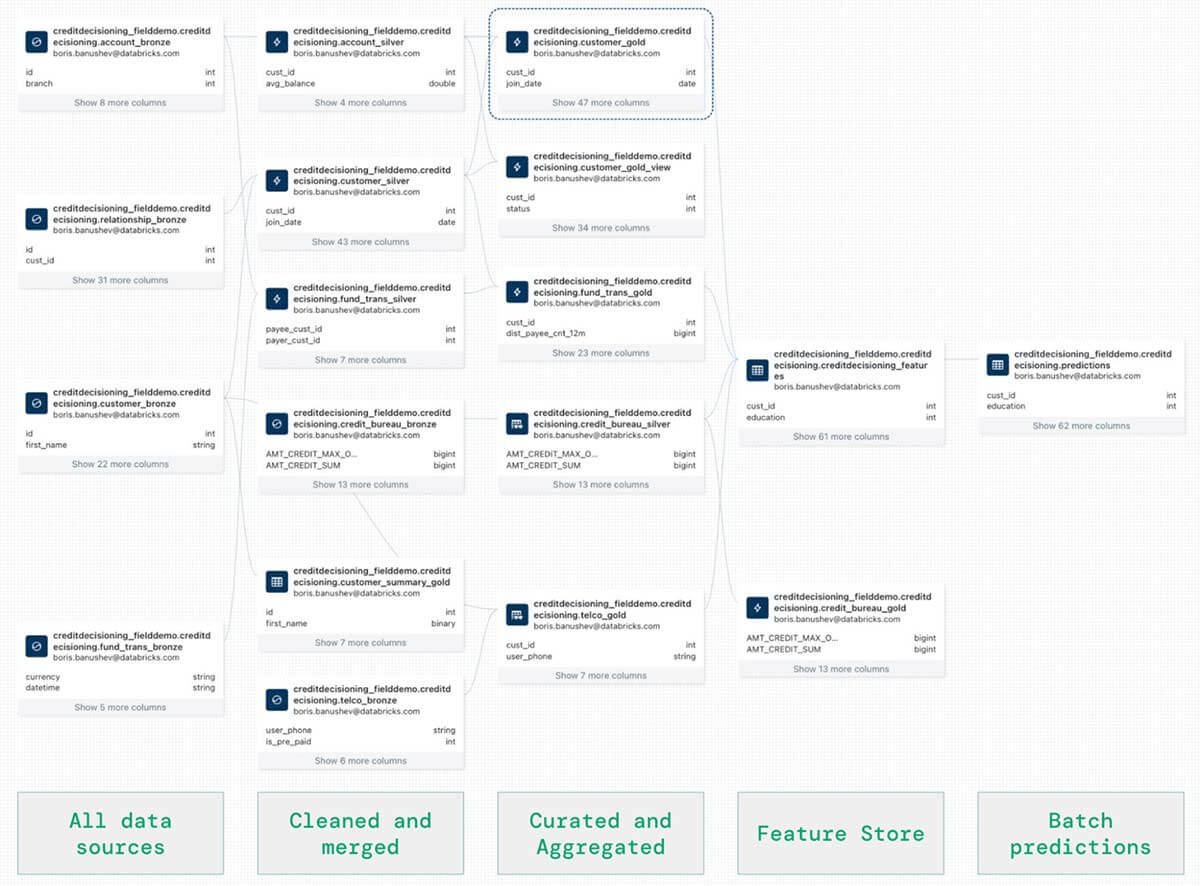
Such end to end data lineage is extremely critical for understanding compliance, audit, observability, and discoverability of data.
These are three very common scenarios, where full data lineage becomes incredibly important:
- Explainability - we need to have the means of tracing features used in machine learning to the raw data that created those features,
- Tracing missing values in a dashboard or ML model to the origin,
- Finding specific data - organizations have hundreds and even thousands of data tables and sources. Finding the table or column that contains specific information can be daunting without proper discoverability tools.
Conclusion
Some of the most customer obsessed inventions over the last 20 years were underpinned by better automation. The iPhone introduced software to detect multi-touch instead of relying on manual hardware upgrades. PayPal revolutionized payments by leveraging the peer-to-peer network. And GPT-3 has changed the world by automating sophisticated text generation that has permeated our daily lives outside of work. Ultimately, credit decisioning is benefiting from the same levels of innovation and automation. Instead of manually approving loans with incomplete data, any firm (bank or otherwise) can now extend credit to new individuals by automatically ingesting alternative data sources, governing PII to improve time to value, and automating the credit decisioning using ML and AI. The credit decisioning framework on the Databricks Lakehouse is designed to codify exactly the simplicity of this automation framework with software provided by Databricks.
To get started and build a credit data platform for your business, visit the demo at Databricks Demo Center.
Never miss a Databricks post
What's next?

Data Science and ML
October 1, 2024/10 min read
ICE/NYSE: Unlocking Financial Insights with a Custom Text-to-SQL Application

Product
November 27, 2024/6 min read