Lakehouse Playhouse: Introducing Apache Spark for Kids
by Conor Murphy
Happy April Fools' Day! There is currently no integration or partnership with Scratch to develop any Databricks-related offering for kids.
Are your child’s coding projects getting bottlenecked by scalability issues? Maybe your 8-year-old’s after-school assignment executes just fine on their toy data set but gets stuck when scaling to gigabytes, terabytes, or even petabytes of data. Apache Spark is the de facto open source standard tool for manipulating large data sets, but to date, kids have been largely unable to leverage this powerful technology. Luckily, there’s Scratch, an open source project that gives children a safe and playful programming environment to learn, create, and collaborate on coding projects such as games and animations.
Scratch strongly aligns with our own mission to simplify and democratize data and AI. Today, we’re thrilled to announce the end to scalability issues for budding child programmers everywhere through a new Scratch API for Spark!

Scaling your Scratch Workloads
Scratch has taken the classroom by storm with 42 million people creating over 113 million projects. Aimed at children 8 and older, it’s been translated into 74 languages and is used all across the globe. Despite Scratch inspiring and training the next generation of computer scientists, there are limitations. As we’ve heard from children time and time again, Scratch’s single-threaded concurrency, paltry machine learning capabilities, and lack of distributed functionality make running production Scratch workloads a veritable nightmare. What’s a kid to do?
This is where Scratch on Spark comes in. Scratch’s colorful and intuitive drag-and-drop functionality provides kids everywhere a linearly scalable solution for their most data-intensive classroom applications. Need to connect back to the toy boats sitting at the dock in the data Lakehouse? Drag the blue tile and just like that, you’re connected to a highly-optimized, scalable, and ACID-compliant Delta table. Need to handle those pesky HIPAA requirements to encrypt your Operation board game data? That’s the red tile. Need to put it into production? Click that green flag in the Scratch UI to CI/CD your latest creation into your production Scratch environment.
Creating a Spark cluster is easy in the scratch UI: just drag and drop tiles to build out your workflow. It even adjusts the cluster size as the data scales!
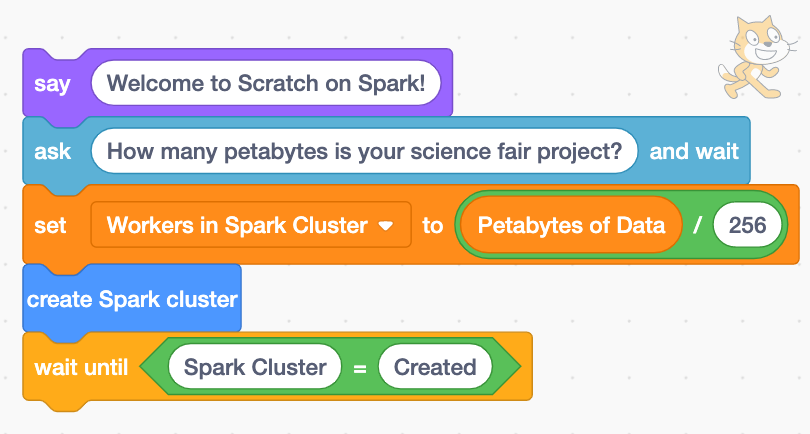
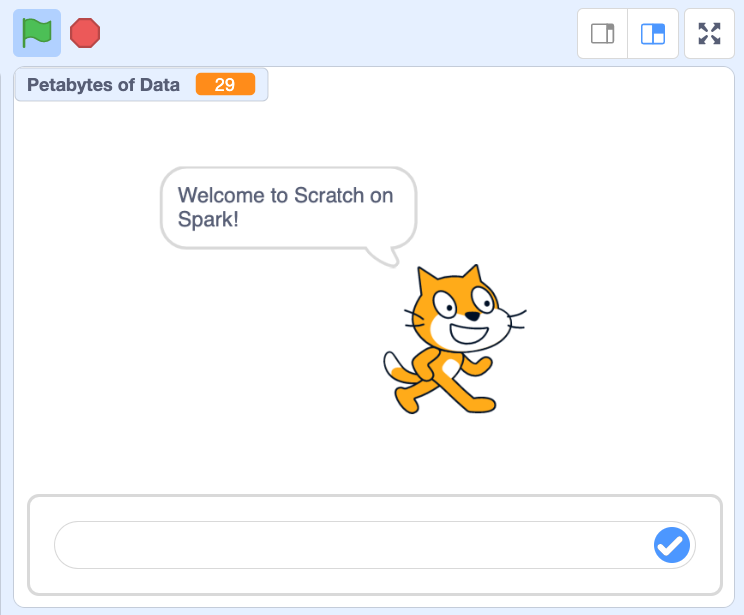
Below shows how the code blocks above interface with the Scratch cat to process petabytes of data using sliders and text boxes. Now that’s a good kitty!
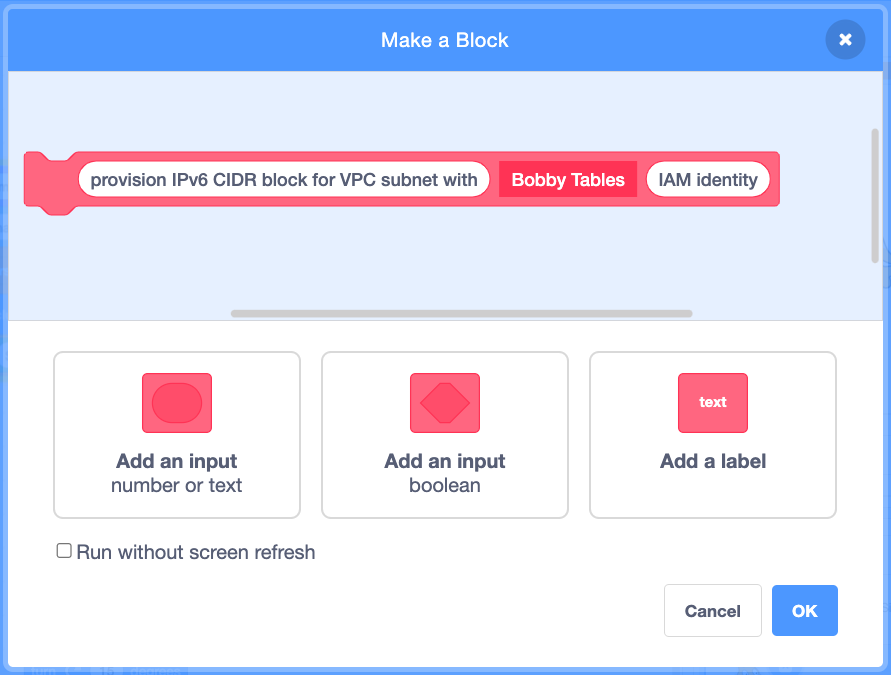
Easily extend Scratch to address production security concerns by making custom code blocks. Gotta keep that homework safe!
Early Success with Scratch on Spark
Families everywhere are already seeing traction with Scratch on Spark. Take Little Bobby Tables, who wants to play with his mom, but she’s stuck in her text editor getting that last JIRA ticket across the board. Bobby thought: “If only I could solve the memory issue of that stream-to-stream join. Then Mom could play with me.”
With a few clicks and drags in the Scratch editor, Bobby whipped up a solution. He made the Scratch Cat mascot provision Spark resources, connect to a Kafka cluster, and say “I love you, Mom.” Then it was just an inner join of the events stream with the cache of user data before dumping it into a Delta table. Once it was picked up by the real-time CEO dashboard, it was mission accomplished with no tables dropped! They were playing board games before the DevOps team got the notification for the code review.
A Bright Future for Budding Computer Scientists
The Scratch API for Spark is revolutionizing the way children are writing their applications. And to make sure kindergarteners aren’t left scratching their heads with scalability bottlenecks, there are some exciting announcements in the pipeline for a Spark integration with Scratch Jr., a flavor of Scratch for kids 5-7 years old. To be competitive in today’s classrooms, kids today need deep knowledge of the industry standard distributed computing engine for big data. By integrating these two valuable open source technologies, Databricks is democratizing data science and engineering beyond just the citizen scientist by opening up these powerful tools to classrooms worldwide.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.