
Retrieval Augmented Generation (RAG) is the top use case for Databricks customers who want to customize AI workflows on their own data. The pace of large language model releases is incredibly fast, and many of our customers are looking for up-to-date guidance on how to build the best RAG pipelines. In a previous blog post, we ran over 2,000 long context RAG experiments on 13 popular open source and commercial LLMs to uncover their performance on various domain-specific datasets. After we released this blog post, we received a lot of enthusiastic requests to further benchmark more state of the art models.
In September, OpenAI released a new o1 family of powerful large language models (LLMs) that rely on extra inference-time compute to enhance “reasoning.” We were eager to see how these new models performed on our internal benchmarks; does more inference-time compute lead to significant improvements?
We designed our evaluation suite to stress-test RAG workflows with very long contexts. The Google Gemini 1.5 models are the only state of the art models that boast a context length of 2 million tokens, and we were excited to see how the Gemini 1.5 models (released in May) held up. 2 million tokens is roughly equivalent to a small corpus of hundreds of documents; in this scenario, developers building custom AI systems could in principle skip retrieval and RAG entirely and simply include the entire corpus in the LLM context window. Can these extreme long context models really replace retrieval?
In this followup blog post, we benchmark new state-of-the-art models OpenAI o1-preview, o1-mini, as well as Google Gemini 1.5 Pro, Gemini 1.5 Flash (May release). After running these additional experiments, we found that:
- OpenAI o1 models show a consistent improvement over Anthropic and Google models on our long context RAG Benchmark up to 128k tokens.
- Despite lower performance than the SOTA OpenAI and Anthropic models, Google Gemini 1.5 models have consistent RAG performance at extreme context lengths of up to 2 million tokens.
- Models fail on long context RAG in highly distinct ways
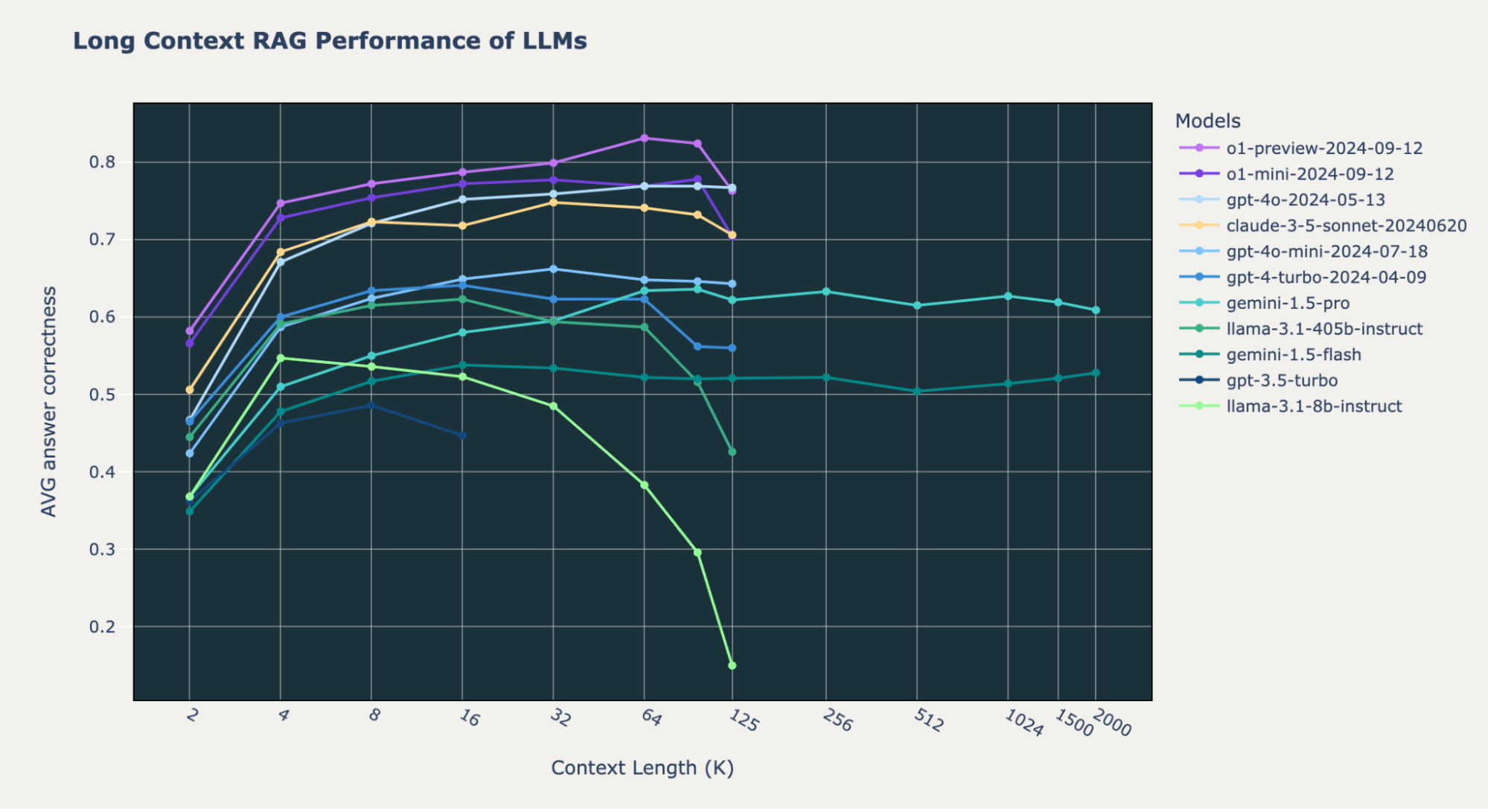
Recap of our previous blog post:
We designed our internal benchmark in order to test the long context, end-to-end RAG capabilities of the state of the art LLMs. The basic setup is as follows:
- Retrieve document chunks from a vector database with documents embedded using OpenAI’s text-embedding-3-large. Documents are split into 512 token chunks with a stride of 256 tokens.
- Vary the total number of tokens by including more retrieved documents in the context window. We vary the total number of tokens from 2,000 tokens up to 2,000,000 tokens.
- The system has to correctly answer questions based on the retrieved documents. The answer is judged by a calibrated LLM-as-a-judge using GPT-4o.
Our internal benchmark consists of 3 separate curated datasets: Databricks DocsQA, FinanceBench, and Natural Questions (NQ).
In our previous blog post Long Context RAG Performance of LLMs, we found that:
- Retrieving more documents can indeed be beneficial: Retrieving more information for a given query increases the likelihood that the right information is passed on to the LLM. Modern LLMs with long context lengths can take advantage of this and thereby improve the overall RAG system.
- Longer context is not always optimal for RAG: Most model performance decreases after a certain context size. Notably, Llama-3.1-405b performance starts to decrease after 32k tokens, GPT-4-0125-preview starts to decrease after 64k tokens, and only a few models can maintain consistent long context RAG performance on all datasets.
- Models fail at long context tasks in highly distinct ways: We conducted deep dives into the long-context performance of DBRX and Mixtral and identified unique failure patterns such as rejecting due to copyright concerns or always summarizing the context. Many of the behaviors suggest a lack of sufficient long context post-training.
In this blog post, we apply the same analysis to OpenAI o1-preview, o1-mini and Google Gemini 1.5 Pro and Gemini 1.5 Flash. For a full description of our datasets, methodology and experimental details, please refer to Long Context RAG Performance of LLMs.
OpenAI o1 results: a new SOTA on Long Context RAG
The new SOTA: The OpenAI o1-preview and o1-mini models beat all the other models on our three long context RAG benchmarks, with the o1-mini results closely matching those of GPT-4o (Figures 1-2). Such a performance improvement over GPT-4o-mini is quite impressive,as the “mini” version of the new release is better than the strongest from the last release.
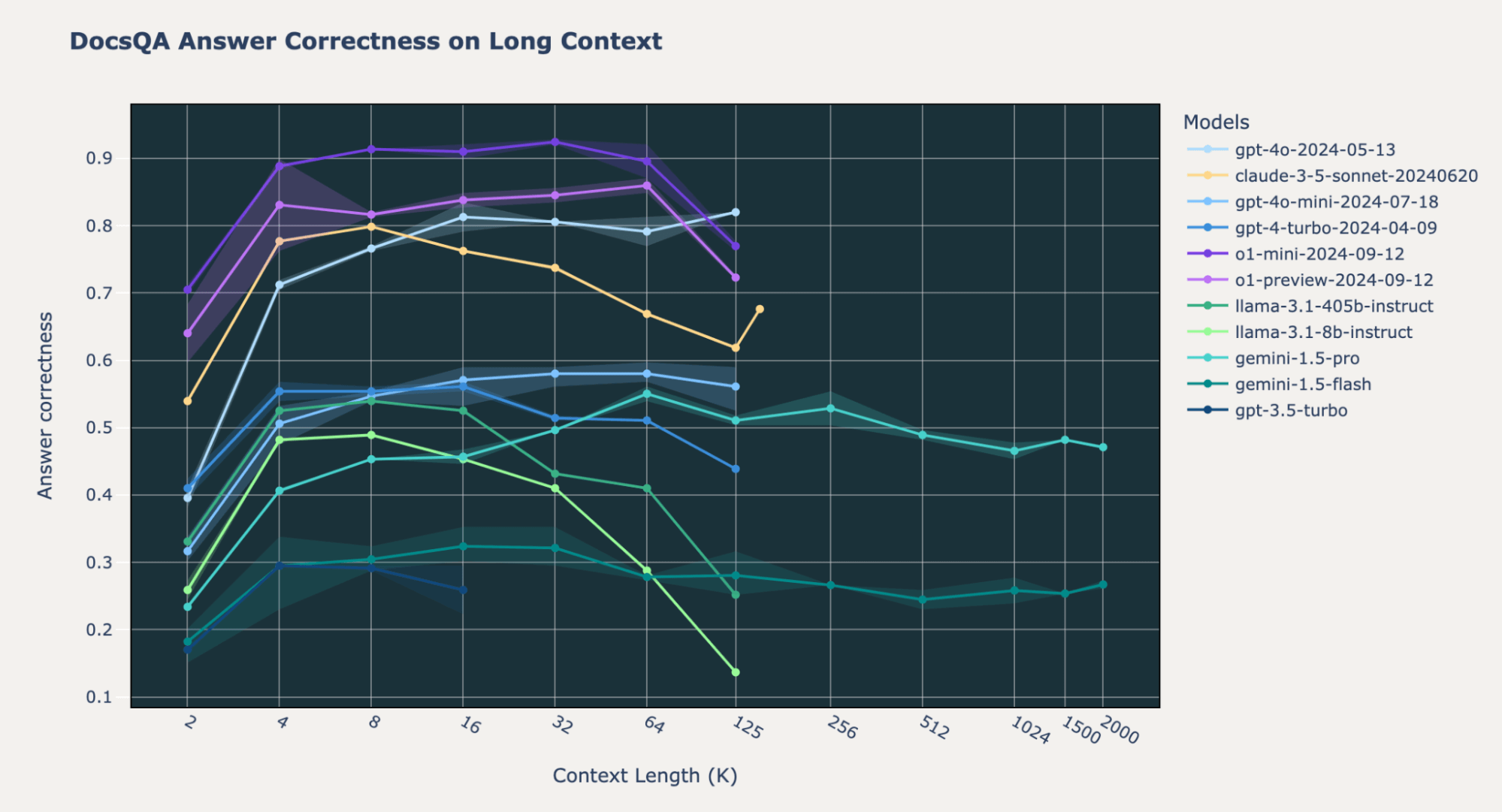
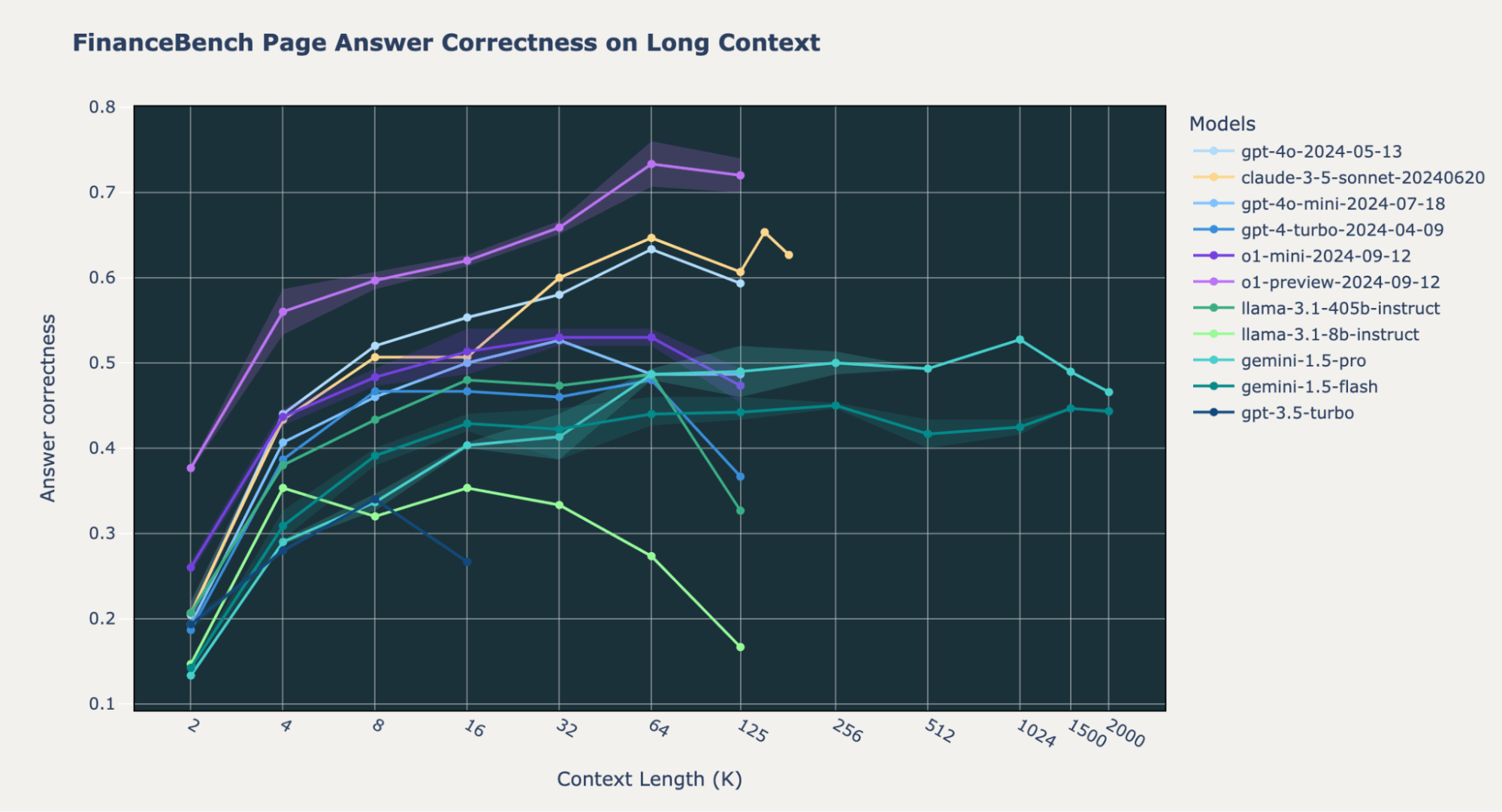
We noticed some differences in o1 model behavior across benchmarks. On our internal Databricks DocsQA and FinanceBench datasets, the o1-preview and o1-mini models do significantly better than the GPT-4o and Gemini models across all context lengths. This is mostly true for the Natural Questions (NQ) dataset; however, we noticed that both the o1-preview and o1-mini models have lower performance at short context length (2k tokens). We delve into this peculiar behavior at the end of this blogpost.
Gemini 1.5 Models Maintain Consistent RAG performance up to 2 Million Tokens
Although the overall answer correctness of the Google Gemini 1.5 Pro and Gemini 1.5 Flash models is much lower than that of the o1 and GPT-4o models up to 128,000 tokens, the Gemini models maintain consistent performance at extremely long contexts up to 2,000,000 tokens.
On Databricks DocsQA and FinanceBench, the Gemini 1.5 models do worse than OpenAI o1, GPT4o-mini, and Anthropic Claude-3.5-Sonnet. However, on NQ, all of these models have comparable high performance with answer correctness values consistently above 0.8. For the most part, the Gemini 1.5 models don’t have a performance decrease at the end of their maximum context length, unlike many of the other models.
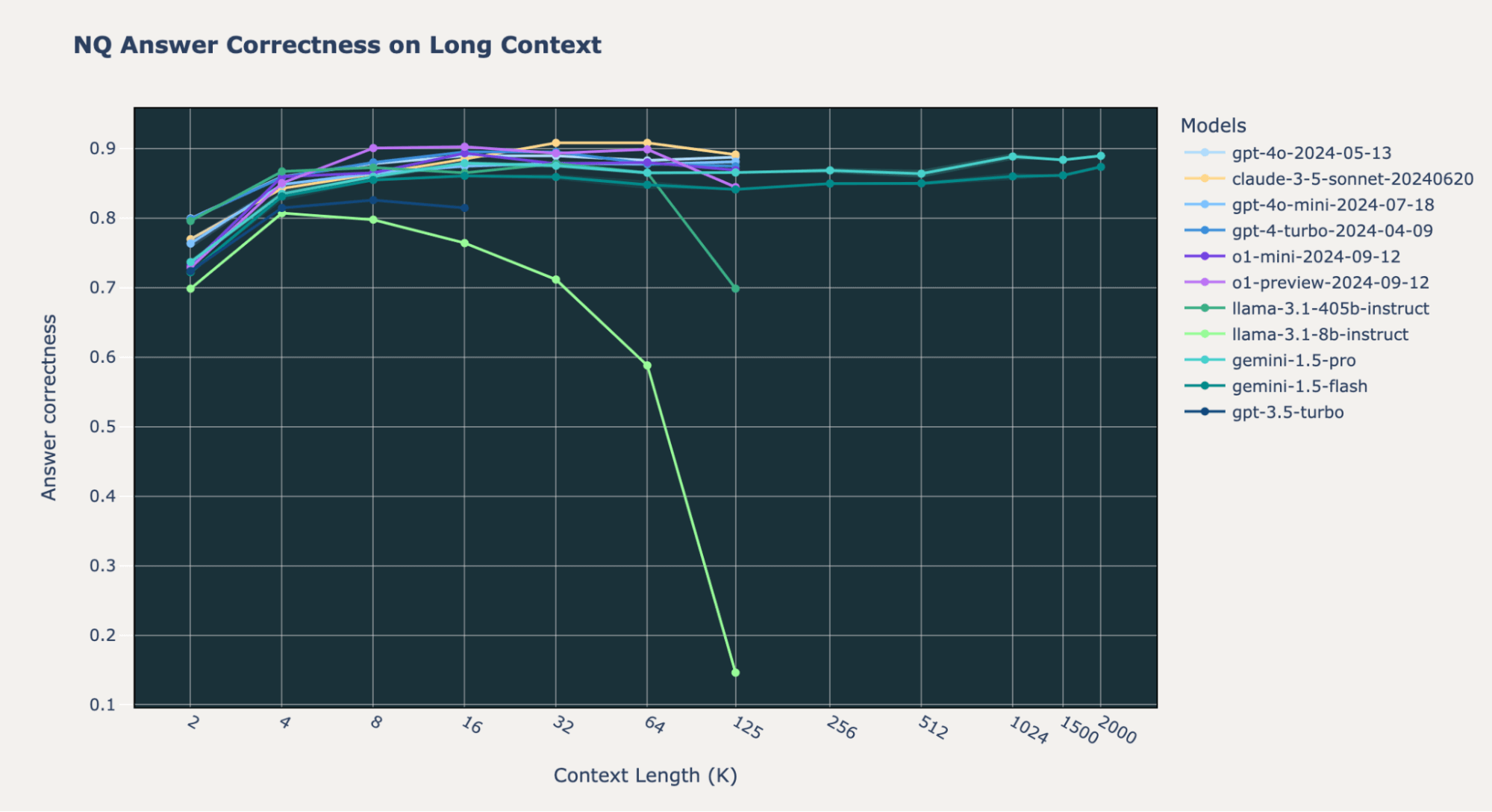
These results imply that for a corpus smaller than 2 million tokens, it is possible to skip the retrieval step in a RAG pipeline and instead directly feed the entire dataset into the Gemini models. Although this would be quite expensive and have lower performance, such a setup could allow developers to trade higher costs for a more simplified developer experience when building LLM applications.
LLMs Fail at Long Context RAG in Different Ways
To assess the failure modes of generation models at longer context length, we analyzed samples from OpenAI o1 and Gemini 1.5 Pro using the same methodology as our previous blog post. We extracted the answers for each model at different context lengths, manually inspected several samples, and – based on those observations – defined the following broad failure categories:
- repeated_content: when the LLM answer is completely (nonsensical) repeated words or characters.
- random_content: when the model produces an answer that is completely random, irrelevant to the content, or doesn't make logical or grammatical sense.
- fail_follow_inst: when the model doesn't understand the intent of the instruction or fails to follow the instruction specified in the question. For example, when the instruction is about answering a question based on the given context while the model is trying to summarize the context.
- empty_resp: the generation answer is empty
- wrong_answer: when the model attempts to follow the instruction but the provided answer is wrong.
- others: the failure doesn't fall under any of the categories listed above
We added two more categories, since this behavior was especially prevalent with the Gemini models:
- refusal: the model either refuses to answer the question, mentions that the answer can't be found in the context, or states that the context is not relevant to the question.
- task failure due to API filtering: the model API simply blocked the prompt due to strict filtering guidelines. Note that if the task failed due to API filtering, we did not include this in the final Answer Correctness calculation.
We developed prompts that describe each category and used GPT-4o to classify all of the failures of the models into the above categories. We also note that the failure patterns on these datasets may not be representative of other datasets; it’s also possible for the pattern to change with different generation settings and prompt templates.
o1-preview and o1-mini failures
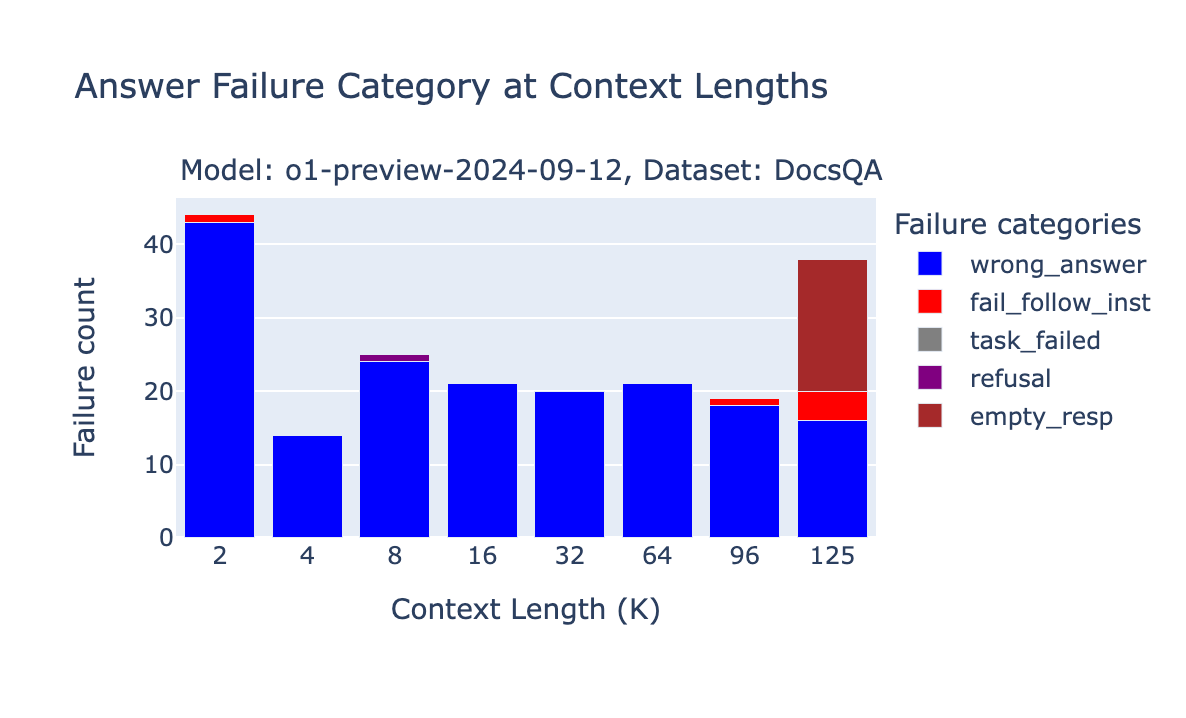
While the OpenAI o1-preview and o1-mini scores ranked at the top of our benchmark, we still noticed some unique failures due to context length. Due to the unpredictable length of the reasoning tokens used in o1 models, if the prompt grows due to intermediate “reasoning” steps, OpenAI doesn’t fail the request directly but instead returns a response with an empty string.
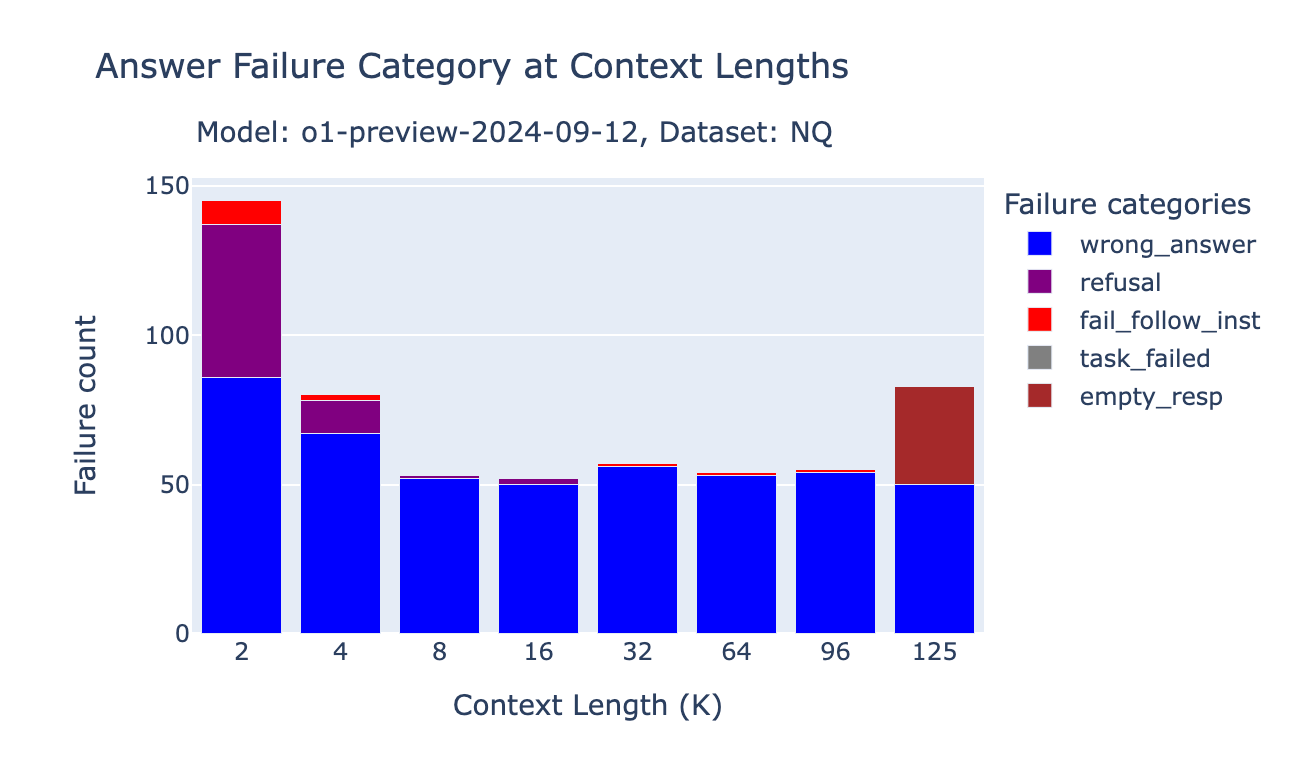
o1 model behavior change on NQ
Despite the performance increase on the Databricks DocsQA and FinanceBench datasets, we observed performance drops for the o1-preview and o1-mini models on NQ at short context length. We found that at short context length, if the information is not in the retrieved documents, o1 models are more likely to simply respond “Information not available” (our prompts include an instruction “if there is no relevant passage, please answer using your knowledge” - see our the Appendix of previous blogpost for the full prompts).
We also noticed a significant portion of samples where the o1 models failed to provide the correct answer even with the oracle document was present. Such performance regression is surprising for such a strong model.
In the following example without an oracle document present, o1 refuses to answer the question, while GPT-4o answered based on its own knowledge:
|
query |
expected_answer |
answer_o1_preview |
answer_gpt4o |
oracle_present |
|
when does dragon ball super episode 113 start |
October 29 , 2017 |
Information not available. |
October 29, 2017 |
FALSE |
|
who plays colin on young and the restless |
Tristan Rogers |
Information not available. |
Tristan Rogers |
FALSE |
In the following example, o1-preview failed to answer the question when the oracle document was retrieved:
|
query |
expected_answer |
answer_o1_preview |
answer_gpt4o |
oracle_present |
|
who is the longest serving member of the house in history |
John Dingell |
Name not provided |
John Dingell |
TRUE |
|
when does episode 29 of boruto come out |
October 18 , 2017 |
Information not available in the provided context |
October 18, 2017 |
TRUE |
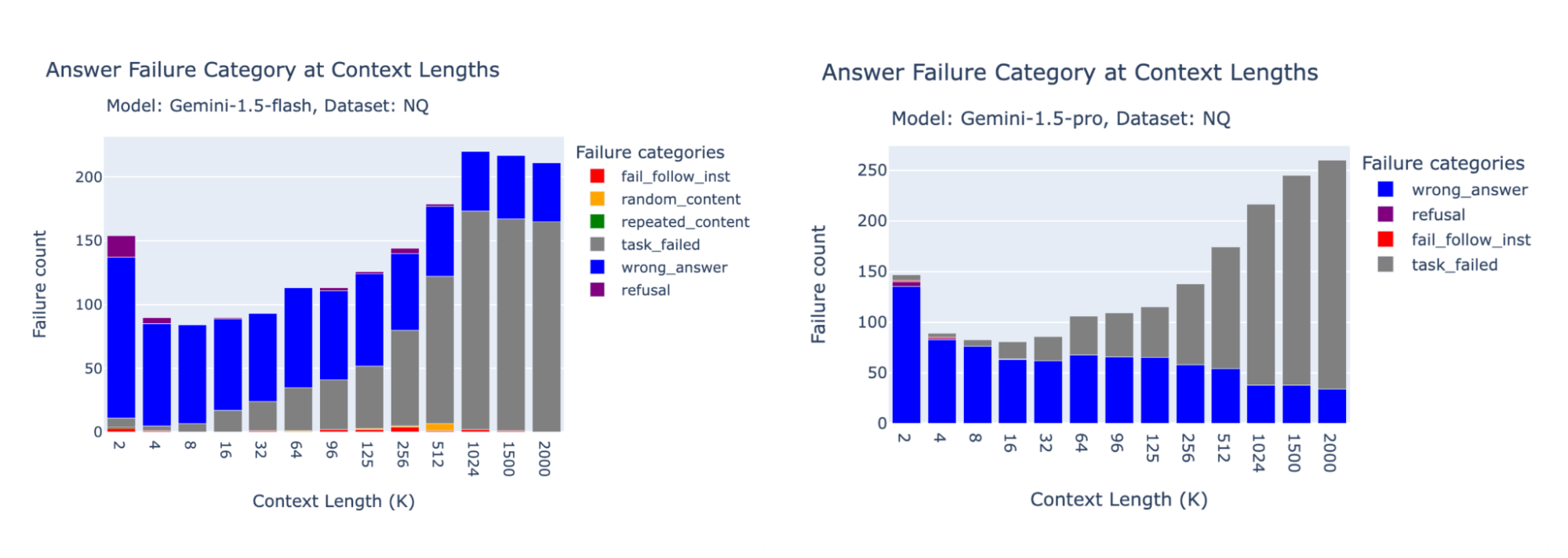
Gemini 1.5 Pro and Flash Failures
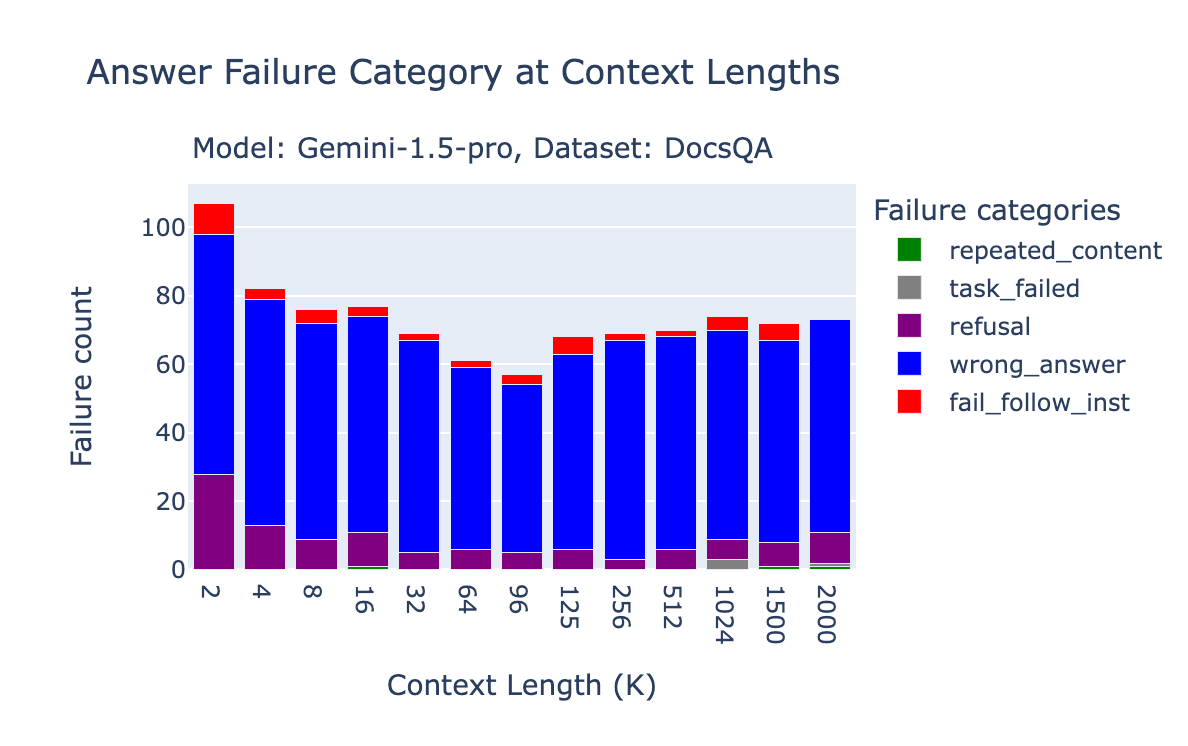
The bar charts below show the failure attribution for Gemini 1.5 Pro and Gemini 1.5 Flash on FinanceBench, Databricks DocsQA and NQ.
Gemini’s generation API is very sensitive to the topics in our prompts. We found that on our NQ benchmark there were many task failures due to prompt content filtering. This was surprising, as NQ is a standard academic benchmark that we were able to successfully benchmark with all other API models. We therefore found that some of the Gemini performance decreases in Gemini wereas simply due to safety filtering! Note however that we decided to not include task failure due to API filtering in the final accuracy measure.
Here is an example of a rejected response from the Google Gemini API BlockedPromptException:
On FinanceBench, a large portion of errors for Gemini 1.5 Pro were due to “refusal,” where the model either refuses to answer the question or mentions that the answer can't be found in the context. This is more pronounced at shorter context lengths, where the OpenAI text-embedding-3-large retriever might not have retrieved the correct documents. Specifically, at 2k context length, the 96.2% of “refusal” cases are indeed when the oracle doc is not present. The accuracy is 89% at 4k, 87% at 8k, 77% at 16k.
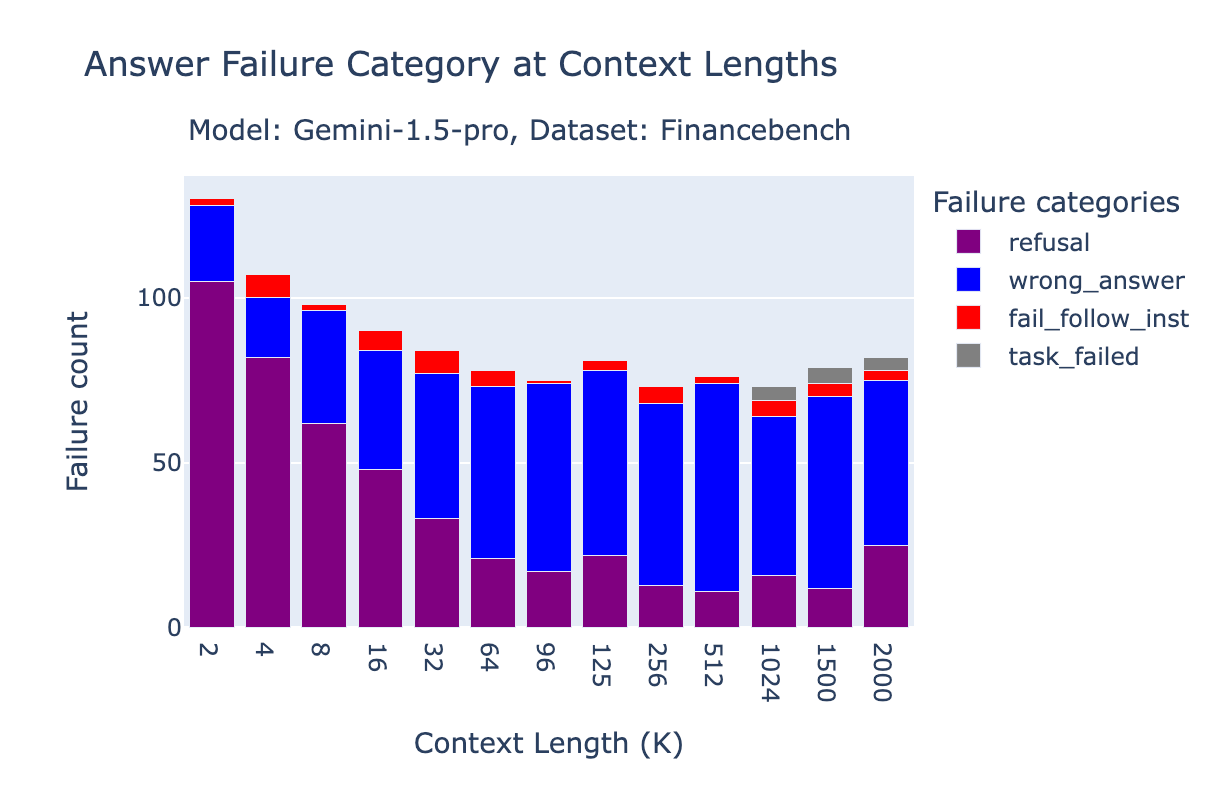
On the Databricks DocsQA dataset, the majority of failures are simply due to incorrect answers.
Conclusions:
We were pleasantly surprised to see strong performance from the OpenAI o1 models; as reported elsewhere, the o1 models seem to be a substantive improvement over GPT-4 and GPT-4o. We were also surprised to see consistent performance from the Gemini 1.5 models at up to 2 million tokens, albeit with lower overall accuracy. We hope that our benchmarks will help inform developers and businesses building RAG workflows.
Robust benchmarking and evaluation tools are crucial for developing complex AI systems. To this end, Databricks Mosaic AI Research is committed to sharing evaluation research (e.g. Calibrating the Mosaic Evaluation Gauntlet) and products such as Mosaic AI Agent Framework and Agent Evaluation that help developers successfully build state of the art AI products.
Appendix:
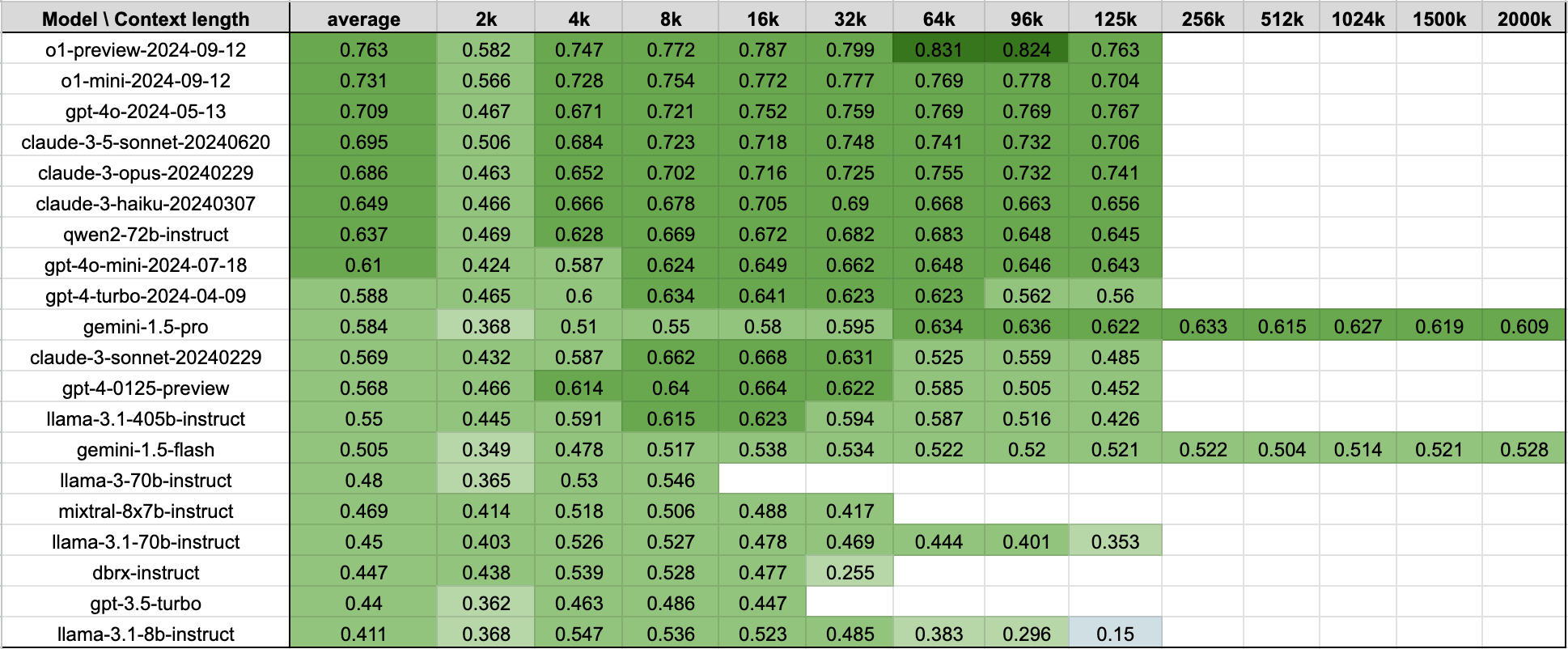
Long context RAG performance table:
By combining these RAG tasks together, we get the following table that shows the average performance of models on the 4 datasets listed above. The table is the same data as Figure 1.
Prompt templates:
We used the following prompt templates (same as in our previous blog post):
Databricks DocsQA:
|
You are a helpful assistant good at answering questions related to databricks products or spark features. You'll be provided with a question and several passages that might be relevant. Your task is to provide an answer based on the question and passages. Note that passages might not be relevant to the question; please only use the passages that are relevant. If there is no relevant passage, please answer using your knowledge. The provided passages as context: {context} The question to answer: {question} Your answer: |
FinanceBench:
|
You are a helpful assistant good at answering questions related to financial reports. You'll be provided with a question and several passages that might be relevant. Your task is to provide an answer based on the question and passages. Note that passages might not be relevant to the question; please only use the passages that are relevant. If there is no relevant passage, please answer using your knowledge. The provided passages as context: {context} The question to answer: {question} Your answer: |
NQ:
|
You are an assistant that answers questions. Use the following pieces of retrieved context to answer the question. Some elements of the context may be irrelevant, in which case you should not use them to form the answer. Your answer should be a short phrase; do not answer in a complete sentence. Question: {question} Context: {context} Answer: |