Simplifying Production MLOps with Lakehouse AI

Machine learning (ML) is more than just developing models; it's about bringing them to life in real-world, production systems. But transitioning from prototype to production is hard. It traditionally demands understanding model and data intricacies, tinkering with distributed systems, and mastering tools like Kubernetes. The process of combining DataOps, ModelOps, and DevOps into one unified workflow is often called 'MLOps'.
At Databricks, we believe a unified, data-centric AI platform is necessary to effectively introduce MLOps practices at your organization. Today we are excited to announce several features in the Databricks Lakehouse AI platform that give your team everything you need to deploy and maintain MLOps systems easily and at scale.
"Utilizing Databricks for ML and MLOps, Cemex was able to easily and quickly move from model training to production deployment. MLOps Stacks automated and standardized our ML workflows across various teams and enabled us to tackle more projects and get to market faster." — Daniel Natanael García Zapata -Global Data Science at Cemex
A Unified Solution for Data and AI
The MLOps lifecycle is constantly consuming and producing data, yet most ML platforms provide siloed tools for data and AI. The Databricks Unity Catalog (UC) connects the dots with the now Generally Available Models and Feature Engineering support. Teams can discover, manage, and govern features, models, and data assets in one centralized place to work seamlessly across the ML lifecycle. The implications of this may be hard to grasp, so we've enumerated some of the benefits of this unified world:
Governance
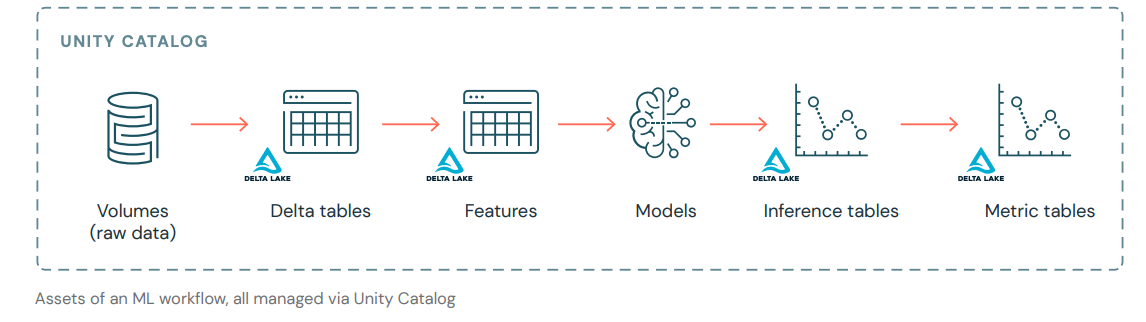
- Cross-Workspace Governance (now Generally Available): The top MLOps request we had was to enable production features and data to be used in development environments. With everything now in the UC, there is one place to control permissions: teams can grant workspaces read/write access to models, features, and training data. This allows sharing and collaboration across workspaces while maintaining isolation of development and production infrastructure.
- End-to-End Lineage (now Public Preview): With data and AI alongside each other, teams can now get end-to-end lineage for the entire ML lifecycle. If something goes awry with a production ML model, lineage can be used to understand impact and perform root cause analysis. Lineage can provide the exact data used to train a model alongside the data in the Inference Table to help generate audit reports for compliance.
- Access State-of-the-Art Models (now Public Preview): State-of-the-art and third-party models can be downloaded from the Databricks Marketplace to be managed and deployed from the UC.
"We chose Databricks Model Serving as Inference Tables are pivotal for our continuous retraining capability - allowing seamless integration of input and predictions with minimal latency. Additionally, it offers a straightforward configuration to send data to delta tables, enabling the use of familiar SQL and workflow tools for monitoring, debugging, and automating retraining pipelines. This guarantees that our customers consistently benefit from the most updated models." — Shu Ming Peh, Lead Machine Learning Engineer at Hipages Group
Deployment
- One-Click Model Deployment (Generally Available): Models in the UC can be deployed as APIs on Databricks Model Serving with one-click. Teams no longer have to be Kubernetes experts; Model Serving automatically scales up and down to handle your model traffic using a serverless architecture for CPU and GPUs. And setting up traffic splitting for A/B testing is just a simple UI configuration or API call to manage staged rollouts.
- Serve Real-Time On-Demand Features (now Generally Available): Our real-time feature engineering services remove the need for engineers to build infrastructure to look up or re-compute feature values. The Lakehouse AI platform understands what data or transformations are needed for model inference and provides the low-latency services to lookup and join the features. This not only prevents online/offline skew but also allows these data transformations to be shared across multiple projects.
- Productionization with MLOps Stacks (now Public Preview): The improved Databricks CLI gives teams the building blocks to develop workflows on top of the Databricks REST API and integrate with CI/CD. The introduction of Databricks Asset Bundles, or Bundles, allow teams to codify the end-to-end definition of a project, including how it should be tested and deployed to the Lakehouse. Today we released the Public Preview of MLOps Stacks which encapsulates the best practices for MLOps, as defined by the latest edition of the Big Book of MLOps. MLOps Stacks uses Bundles to connect all the pieces of the Lakehouse AI platform together to provide an out-of-the-box solution for productionizing models in a robust and automated way.
Monitoring
- Automatic Payload Logging (now Public Preview): Inference Tables are the ultimate manifestation of the Lakehouse paradigm. They are UC-managed Delta tables that store model requests and responses. Inference tables are extremely powerful and can be used for monitoring, diagnostics, creation of training corpora, and compliance audits. For batch inference, most teams have already created this table; for online inference, you can enable the Inference Table feature on your endpoint to automate the payload logging.
- Quality Monitoring (now Public Preview): Lakehouse Monitoring allows you to monitor your Inference Tables and other Delta tables in the Unity Catalog to get real-time alerts on drifts in model and data performance. Monitoring will auto-generate a dashboard to visualize performance metrics and alerts can be configured to send real-time notifications when metrics have crossed a threshold.
All of these features are only possible within the Lakehouse AI platform when managing both data and AI assets under one centralized governance layer. And together they paint a beautiful picture for MLOps: a data scientist can train a model using production data, detect and debug model quality degradation by examining their monitoring dashboard, deep dive on model predictions using production inference tables, and compare offline models with online production models. This accelerates the MLOps process and improves and maintains the quality of the models and data.
What's Next
All of the features mentioned above are in Public Preview or GA. Download the Big Book of MLOps and start your MLOps journey on the Lakehouse AI platform. Reach out to your Databricks account team if you want to engage professional services or do an MLOps walkthrough.
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read