
Large language models are challenging to adapt to new enterprise tasks. Prompting is error-prone and achieves limited quality gains, while fine-tuning requires large amounts of human-labeled data that is not available for most enterprise tasks. Today, we’re introducing a new model tuning method that requires only unlabeled usage data, letting enterprises improve quality and cost for AI using just the data they already have. Our method, Test-time Adaptive Optimization (TAO), leverages test-time compute (as popularized by o1 and R1) and reinforcement learning (RL) to teach a model to do a task better based on past input examples alone, meaning that it scales with an adjustable tuning compute budget, not human labeling effort. Crucially, although TAO uses test-time compute, it uses it as part of the process to train a model; that model then executes the task directly with low inference costs (i.e., not requiring additional compute at inference time). Surprisingly, even without labeled data, TAO can achieve better model quality than traditional fine-tuning, and it can bring inexpensive open source models like Llama to within the quality of costly proprietary models like GPT-4o and o3-mini.
TAO is part of our research team’s program on Data Intelligence — the problem of making AI excel at specific domains using the data enterprises already have. With TAO, we achieve three exciting results:
- On specialized enterprise tasks such as document question answering and SQL generation, TAO outperforms traditional fine-tuning on thousands of labeled examples. It brings efficient open source models like Llama 8B and 70B to a similar quality as expensive models like GPT-4o and o3-mini1 without the need for labels.
- We can also use multi-task TAO to improve an LLM broadly across many tasks. Using no labels, TAO improves the performance of Llama 3.3 70B by 2.4% on a broad enterprise benchmark.
- Increasing TAO’s compute budget at tuning time yields better model quality with the same data, while the inference costs of the tuned model stay the same.
Figure 1 shows how TAO improves Llama models on three enterprise tasks: FinanceBench, DB Enterprise Arena, and BIRD-SQL (using the Databricks SQL dialect)². Despite only having access to LLM inputs, TAO outperforms traditional fine-tuning (FT) with thousands of labeled examples and brings Llama within the same range as expensive proprietary models.
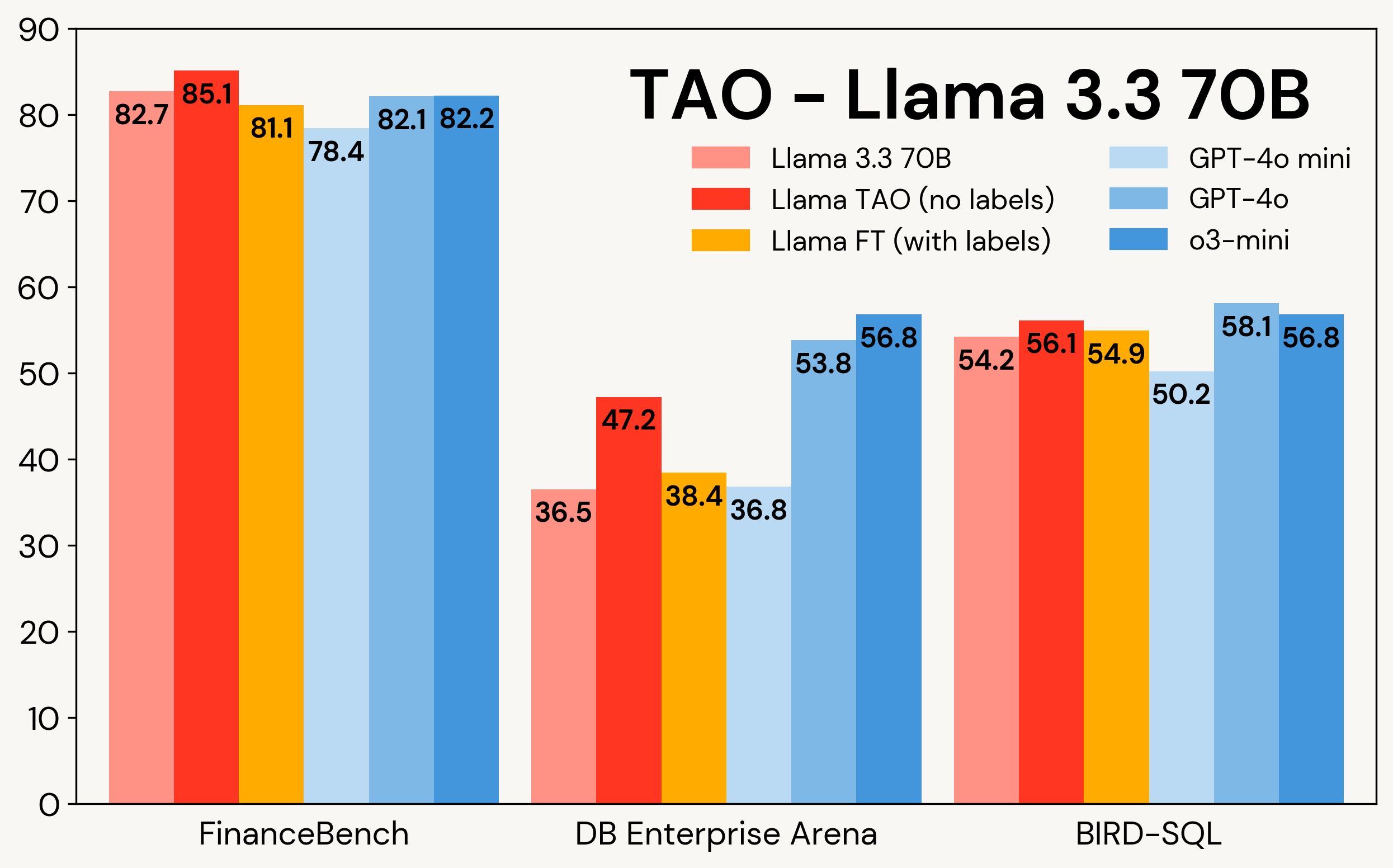
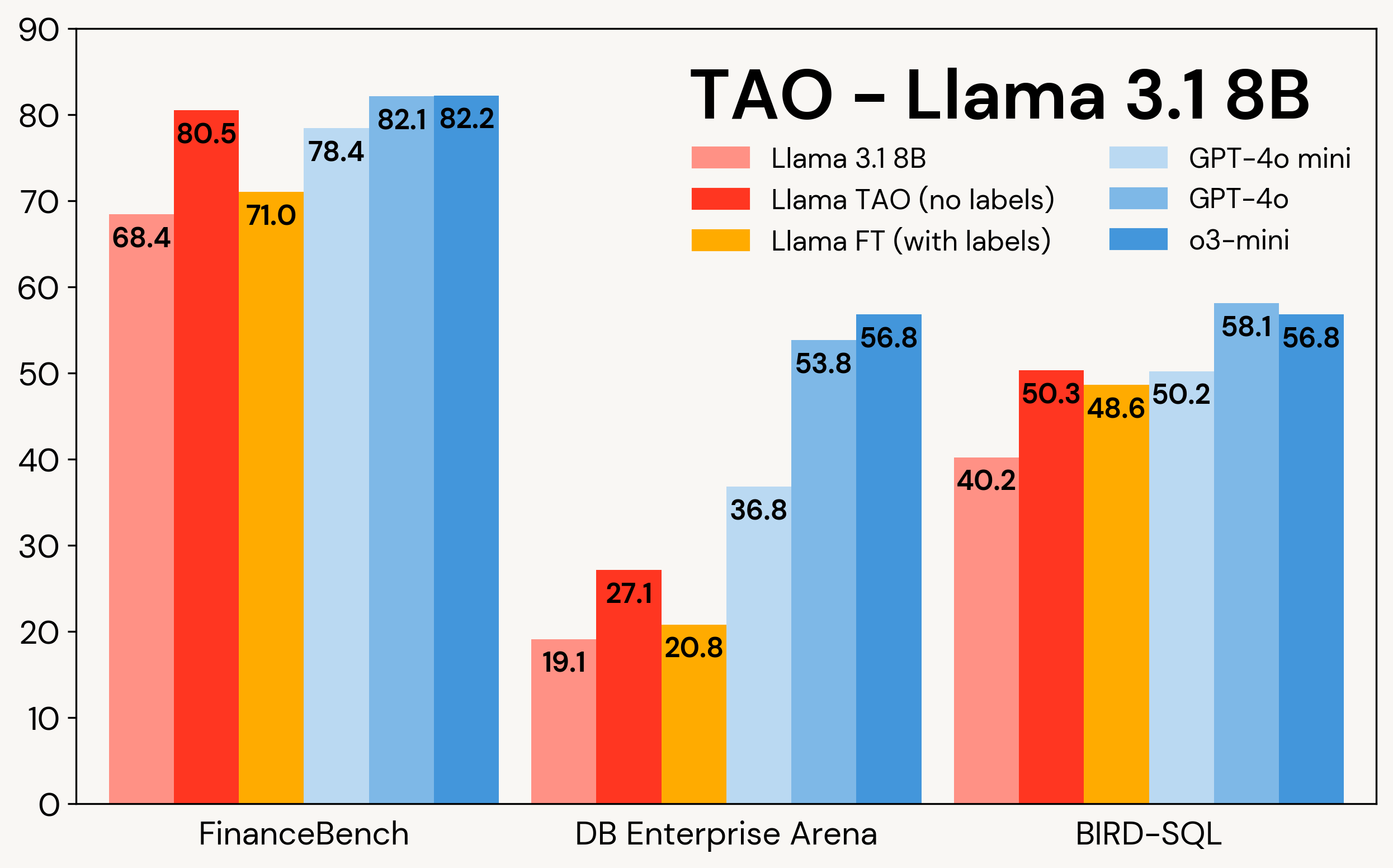
Figure 1: TAO on Llama 3.1 8B and Llama 3.3 70B across three enterprise benchmarks. TAO leads to substantial improvements in quality, outperforming fine-tuning and challenging expensive proprietary LLMs.
TAO is now available in preview to Databricks customers who want to tune Llama, and it will be powering several upcoming products. Fill out this form to express your interest in trying it on your tasks as part of the private preview. In this post, we describe more about how TAO works and our results with it.
How Does TAO Work? Using Test-Time Compute and Reinforcement Learning to Tune Models
Instead of requiring human annotated output data, the key idea in TAO is to use test-time compute to have a model explore plausible responses for a task, then use reinforcement learning to update an LLM based on evaluating these responses. This pipeline can be scaled using test-time compute, instead of expensive human effort, to increase quality. Moreover, it can easily be customized using task-specific insights (e.g., custom rules). Surprisingly, applying this scaling with high-quality open source models leads to better results than human labels in many cases.

Specifically, TAO comprises four stages:
- Response Generation: This stage begins with collecting example input prompts or queries for a task. On Databricks, these prompts can be automatically collected from any AI application using our AI Gateway. Each prompt is then used to generate a diverse set of candidate responses. A rich spectrum of generation strategies can be applied here, ranging from simple chain-of-thought prompting to sophisticated reasoning and structured prompting techniques.
- Response Scoring: In this stage, generated responses are systematically evaluated. Scoring methodologies include a variety of strategies, such as reward modeling, preference-based scoring, or task-specific verification utilizing LLM judges or custom rules. This stage ensures each generated response is quantitatively assessed for quality and alignment with criteria.
- Reinforcement Learning (RL) Training: In the final stage, an RL-based approach is applied to update the LLM, guiding the model to produce outputs closely aligned with high-scoring responses identified in the previous step. Through this adaptive learning process, the model refines its predictions to enhance quality.
- Continuous Improvement: The only data TAO needs is example LLM inputs. Users naturally create this data by interacting with an LLM. As soon as your LLM is deployed, you begin generating training data for the next round of TAO. On Databricks, your LLM can get better the more you use it, thanks to TAO.
Crucially, although TAO uses test-time compute, it uses it to train a model that then executes a task directly with low inference costs. This means that the models produced by TAO have the same inference cost and speed as the original model - significantly less than test-time compute models like o1, o3 and R1. As our results show, efficient open source models trained with TAO can challenge leading proprietary models in quality.
TAO provides a powerful new method in the toolkit for tuning AI models. Unlike prompt engineering, which is slow and error–prone, and fine-tuning, which requires producing expensive and high-quality human labels, TAO lets AI engineers achieve great results by simply providing representative input examples of their task.
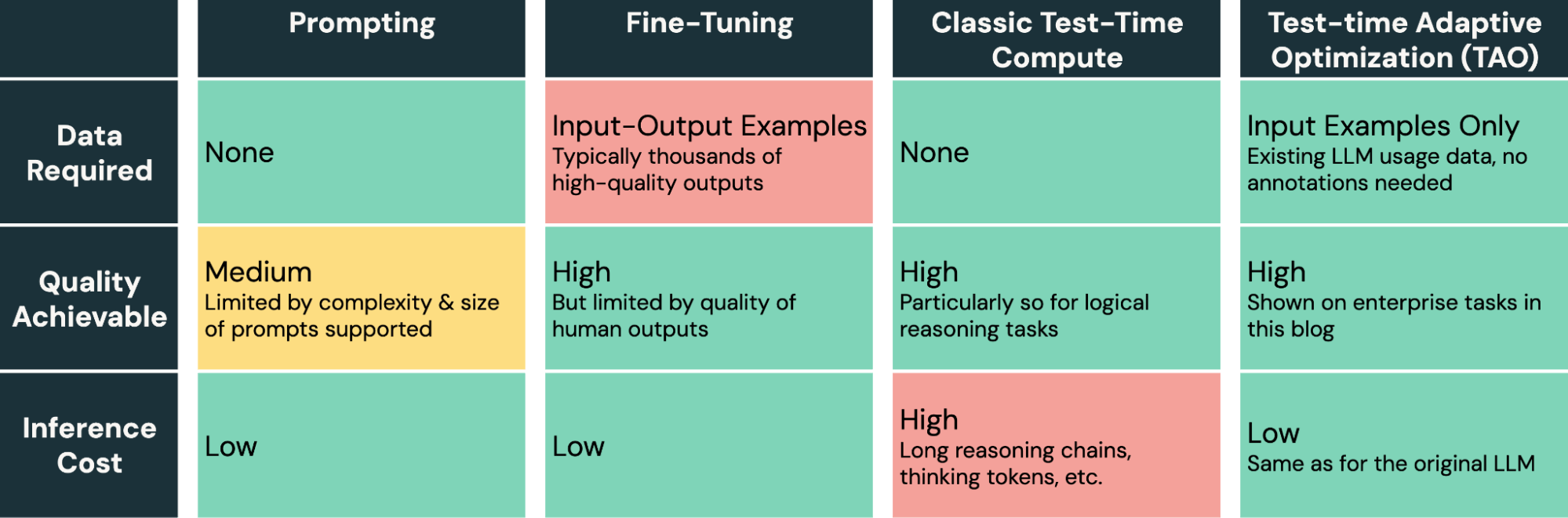
TAO is a highly flexible method that can be customized if needed, but our default implementation in Databricks works well out-of-the-box on diverse enterprise tasks. At the core of our implementation are new reinforcement learning and reward modeling techniques our team developed that enable TAO to learn by exploration and then tune the underlying model using RL. For example, one of the ingredients powering TAO is a custom reward model we trained for enterprise tasks, DBRM, that can produce accurate scoring signals across a wide range of tasks.
Improving Task Performance with TAO
In this section, we dive deeper into how we used TAO to tune LLMs on specialized enterprise tasks. We selected three representative benchmarks, including popular open source benchmarks and internal ones we developed as part of our Domain Intelligence Benchmark Suite (DIBS).

For each task, we evaluated several approaches:
- Using an open source Llama model (Llama 3.1-8B or Llama 3.3-70B) out of the box.
- Fine-tuning on Llama. To do this, we used or created large, realistic input-output datasets with thousands of examples, which is usually what is required to achieve good performance with fine-tuning. These included:
- 7200 synthetic questions about SEC documents for FinanceBench.
- 4800 human-written inputs for DB Enterprise Arena.
- 8137 examples from the BIRD-SQL training set, modified to match the Databricks SQL dialect.
- TAO on Llama, using just the example inputs from our fine-tuning datasets, but not the outputs, and using our DBRM enterprise-focused reward model. DBRM itself is not trained on these benchmarks.
- High-quality proprietary LLMs – GPT 4o-mini, GPT 4o and o3-mini.
As shown in Table 3, across all three benchmarks and both Llama models, TAO significantly improves the baseline Llama performance, even beyond that of fine-tuning.

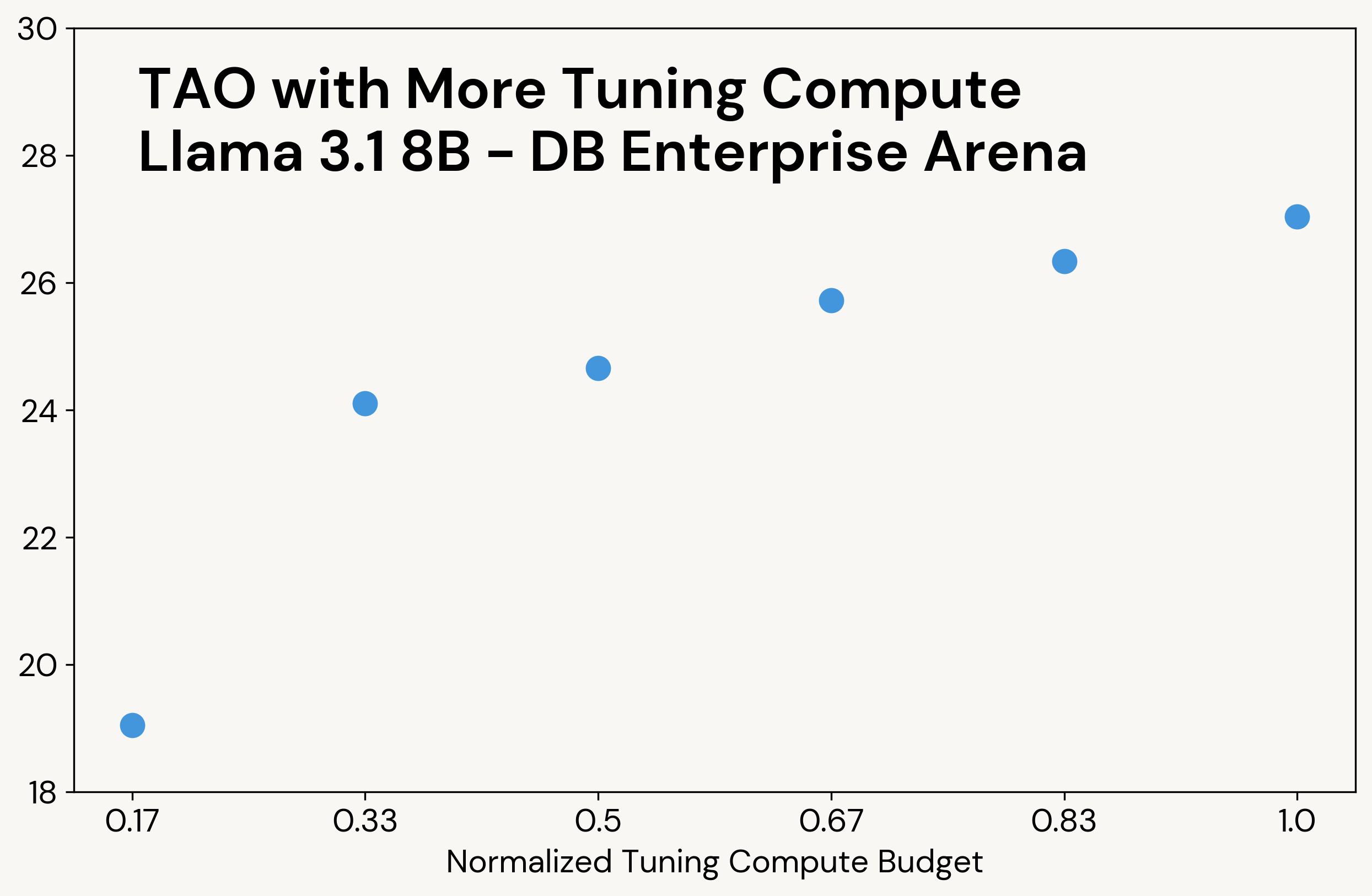
Like classic test-time compute, TAO produces higher-quality results when it is given access to more compute (see Figure 3 for an example). Unlike test-time compute, however, this additional compute is only used during the tuning phase; the final LLM has the same inference cost as the original LLM. For example, o3-mini produces 5-10x more output tokens than the other models on our tasks, resulting in a proportionally higher inference cost, while TAO has the same inference cost as the original Llama model.
Improving Multitask Intelligence with TAO
So far, we’ve used TAO to improve LLMs on individual narrow tasks, such as SQL generation. However, as agents become more complex, enterprises increasingly need LLMs that can perform more than one task. In this section, we show how TAO can broadly improve model performance across a range of enterprise tasks.
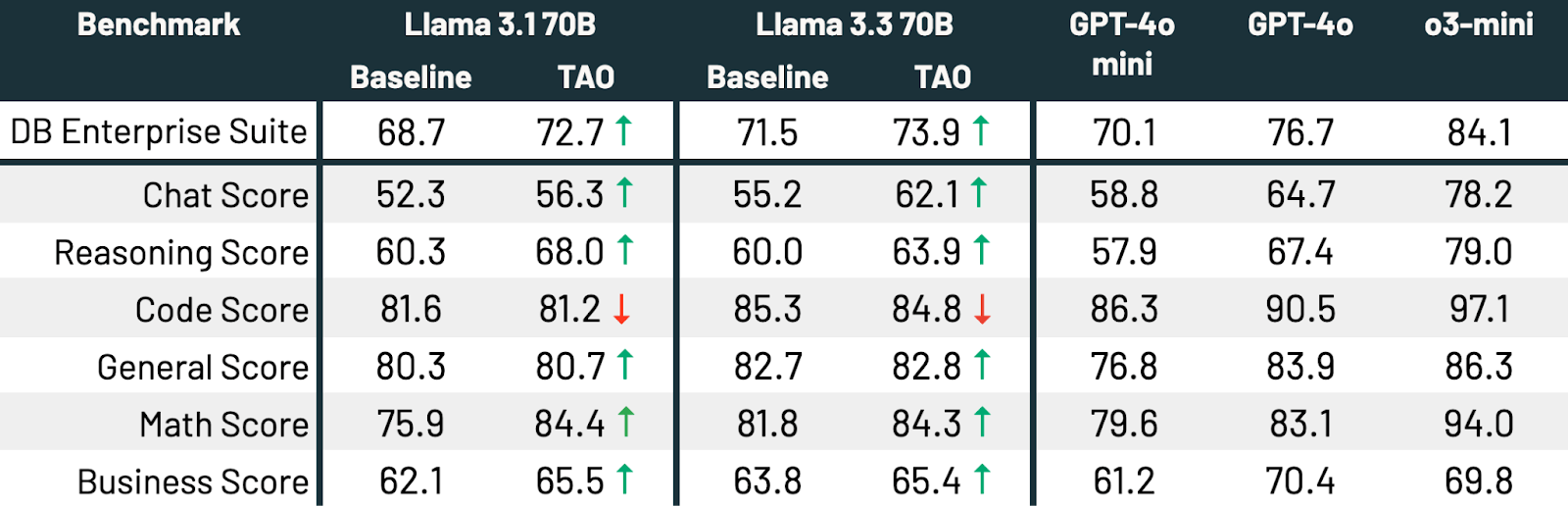
In this experiment, we gathered 175,000 prompts that reflect a diverse set of enterprise tasks, including coding, math, question-answering, document understanding, and chat. We then ran TAO on Llama 3.1 70B and Llama 3.3 70B. Finally, we tested a suite of enterprise-relevant tasks, which includes popular LLM benchmarks (e.g. Arena Hard, LiveBench, GPQA Diamond, MMLU Pro, HumanEval, MATH) and internal benchmarks in multiple areas relevant to enterprises.
TAO meaningfully improves the performance of both models[t][u]. Llama 3.3 70B and Llama 3.1 70B improve by 2.4 and 4.0 percentage points, respectively. TAO brings Llama 3.3 70B significantly closer to GPT-4o on enterprise tasks[v][w]. All of this is achieved with no human labeling cost, just representative LLM usage data and our production implementation of TAO. Quality improves across every subscore except coding, where performance is static.
Using TAO in Practice
TAO is a powerful tuning method that works surprisingly well on many tasks by leveraging test-time compute. To use it successfully on your own tasks, you will need:
- Sufficient example inputs for your task (several thousand), either collected from a deployed AI application (e.g., questions sent to an agent) or generated synthetically.
- A sufficiently accurate scoring method: for Databricks customers, one powerful tool here is our custom reward model, DBRM, that powers our implementation of TAO, but you can augment DBRM with custom scoring rules or verifiers if they are applicable for your task.
One best practice that will enable TAO and other model improvement methods is to create a data flywheel for your AI applications. As soon as you deploy an AI application, you can collect inputs, model outputs, and other events through services like Databricks Inference Tables. You can then use just the inputs to run TAO. The more people use your application, the more data you will have to tune it on, and - thanks to TAO - the better your LLM will get.
Conclusion and Getting Started on Databricks
In this blog, we presented Test-time Adaptive Optimization (TAO), a new model tuning technique that achieves high-quality results without needing labeled data. We developed TAO to address a key challenge we saw enterprise customers facing: they lacked labeled data needed by standard fine-tuning. TAO uses test-time compute and reinforcement learning to improve models using data that enterprises already have, such as input examples, making it straightforward to improve any deployed AI application in quality and reduce cost by using smaller models. TAO is a highly flexible method that shows the power of test-time compute for specialized AI development, and we believe it will give developers a powerful and simple new tool to use alongside prompting and fine-tuning.
Databricks customers are already using TAO on Llama in private preview. Fill out this form to express your interest in trying it on your tasks as part of the private preview. TAO is also being incorporated into many of our upcoming AI product updates and launches - stay tuned!
¹ Authors: Raj Ammanabrolu, Ashutosh Baheti, Jonathan Chang, Xing Chen, Ta-Chung Chi, Brian Chu, Brandon Cui, Erich Elsen, Jonathan Frankle, Ali Ghodsi, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, Jose Javier Gonzalez Ortiz, Sean Owen, Mihir Patel, Mansheej Paul, Cory Stephenson, Alex Trott, Ziyi Yang, Matei Zaharia, Andy Zhang, Ivan Zhou
² We use o3-mini-medium throughout this blog.
³ This is the BIRD-SQL benchmark modified for Databricks’ SQL dialect and products.