Improving Retrieval and RAG with Embedding Model Finetuning
Summary
- How finetuning embedding models boost retrieval and RAG accuracy
- Key performance gains across benchmarks
- Getting started with embedding finetuning on Databricks
Finetuning Embedding Models for Better Retrieval and RAG
TL;DR: Finetuning an embedding model on in-domain data can significantly improve vector search and retrieval-augmented generation (RAG) accuracy. With Databricks, it’s easy to finetune, deploy, and evaluate embedding models to optimize retrieval for your specific use case—leveraging synthetic data without manual labeling.
Why It Matters: If your vector search or RAG system isn’t retrieving the best results, finetuning an embedding model is a simple yet powerful way to boost performance. Whether you’re dealing with financial documents, knowledge bases, or internal code documentation, finetuning can give you more relevant search results and better downstream LLM responses.
What We Found: We finetuned and tested two embedding models on three enterprise datasets and saw major improvements in retrieval metrics (Recall@10) and downstream RAG performance. This means finetuning can be a game-changer for accuracy without requiring manual labeling, leveraging only your existing data.
Want to try embedding finetuning? We provide a reference solution to help you get started. Databricks makes vector search, RAG, reranking, and embedding finetuning easy. Reach out to your Databricks Account Executive or Solutions Architect for more information.
Why Finetune Embeddings?
Embedding models power modern vector search and RAG systems. An embedding model transforms text into vectors, making it possible to find relevant content based on meaning rather than just keywords. However, off-the-shelf models aren’t always optimized for your specific domain—that’s where finetuning comes in.
Finetuning an embedding model on domain-specific data helps in several ways:
- Boost retrieval accuracy: Custom embeddings improve search results by aligning with your data.
- Enhance RAG performance: Better retrieval reduces hallucinations and enables more grounded generative AI responses.
- Improve cost and latency: A smaller finetuned model can sometimes outperform larger, expensive alternatives.
In this blog post, we show that finetuning an embedding model is an effective way to improve retrieval and RAG performance for task-specific, enterprise use cases.
Results: Finetuning Works
We finetuned two embedding models (gte-large-en-v1.5 and e5-mistral-7b-instruct) on synthetic data and evaluated them on three datasets from our Domain Intelligence Benchmark Suite (DIBS) (FinanceBench, ManufactQA, and Databricks DocsQA). We then compared them against OpenAI’s text-embedding-3-large.
Key Takeaways:
- Finetuning improved retrieval accuracy across datasets, often significantly outperforming baseline models.
- Finetuned embeddings performed as well as or better than reranking in many cases, showing they can be a strong standalone solution.
- Better retrieval led to better RAG performance on FinanceBench, demonstrating end-to-end benefits.
Retrieval Performance
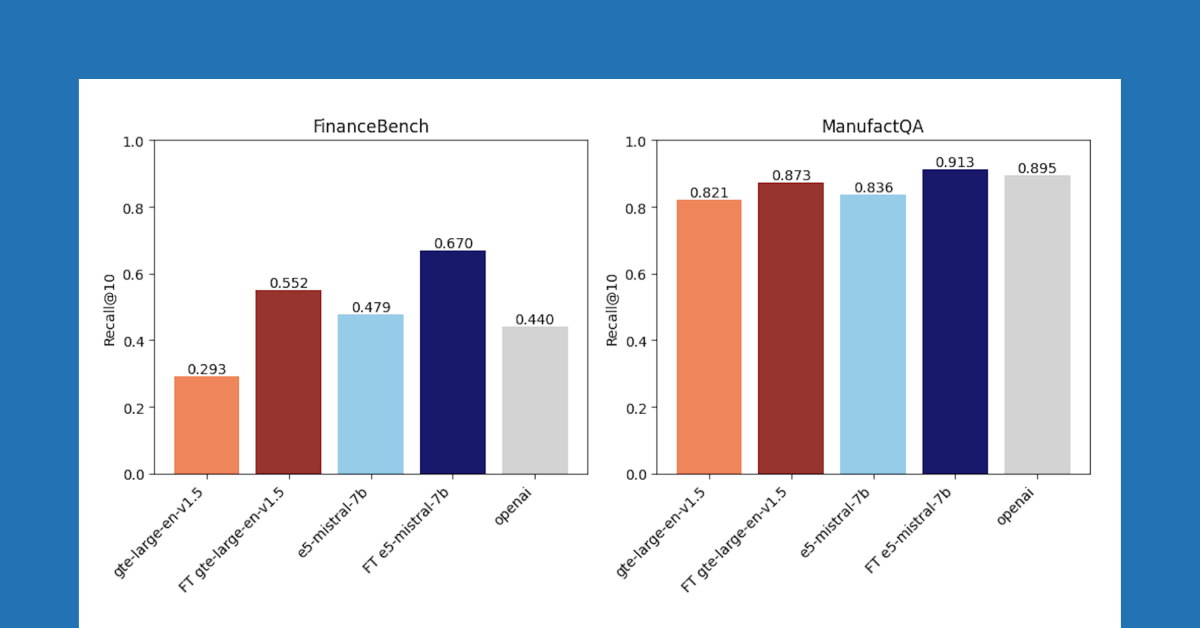
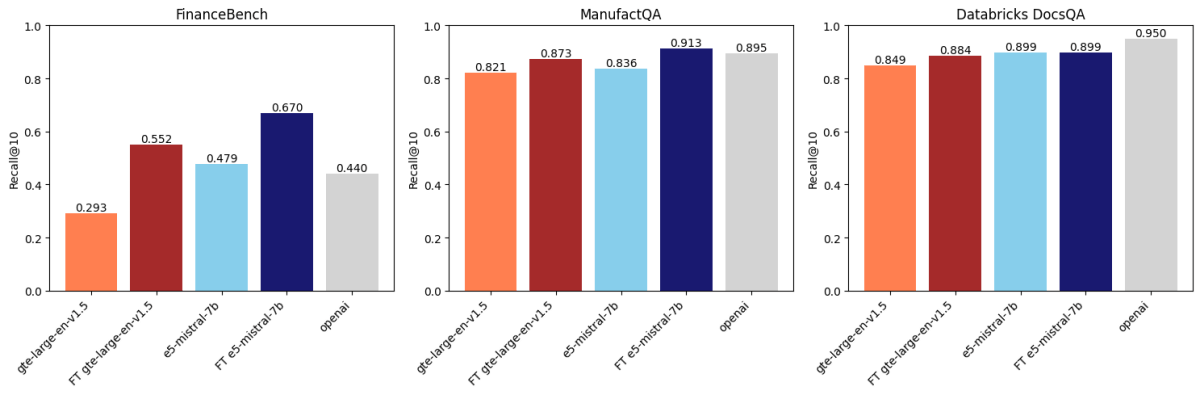
After comparing across three datasets, we found that embedding finetuning improves accuracy on two of these datasets. Figure 1 shows that for FinanceBench and ManufactQA, finetuned embeddings outperformed their base versions, sometimes even beating OpenAI’s API model (light grey). For Databricks DocsQA, however, OpenAI text-embedding-3-large accuracy surpasses all finetuned models. It is possible that this is because the model has been trained on public Databricks documentation. This shows that while finetuning can be effective, it strongly depends on the training dataset and the evaluation task.
Finetuning vs. Reranking
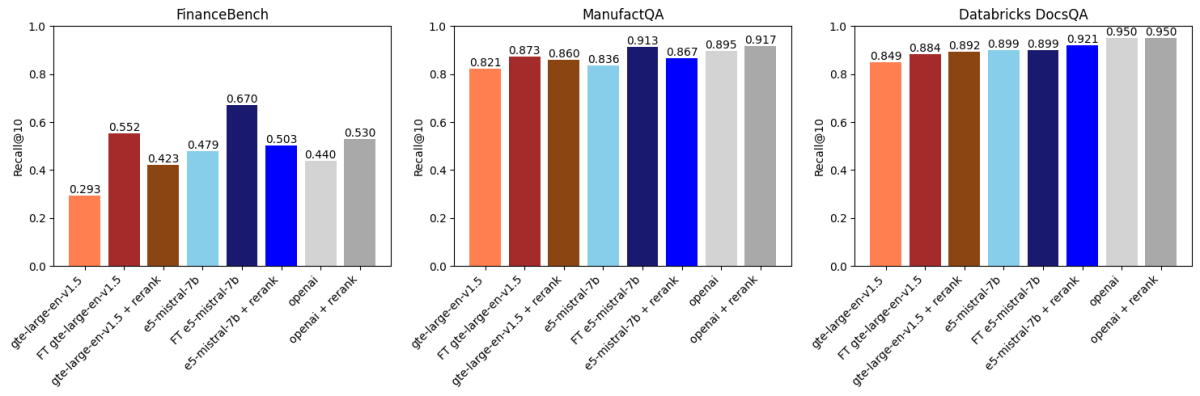
We then compared the above results with API-based reranking using voyageai/rerank-1 (Figure 2). A reranker typically takes the top k results retrieved by an embedding model, reranks these results by relevance to the search query, and then returns the reranked top k (in our case k=30 followed by k=10). This works because rerankers are usually larger, more powerful models than embedding models and also model the interaction between the query and the document in a way that is more expressive.
What we found was:
- Finetuning gte-large-en-v1.5 outperformed reranking on FinanceBench and ManufactQA.
- OpenAI’s text-embedding-3-large benefited from reranking, but the improvements were marginal on some datasets.
- For Databricks DocsQA, reranking had a smaller impact, but finetuning still brought improvements, showing the dataset-dependent nature of these methods.
Rerankers usually incur additional per-query inference latency and cost relative to embedding models. However, they can be used with existing vector databases and can in some cases be more cost effective than re-embedding data with a newer embedding model. The choice of whether to use a reranker depends on your domain and your latency/cost requirements.
Finetuning Helps RAG Performance
For FinanceBench, better retrieval translated directly to better RAG accuracy when combined with GPT-4o (see Appendix). However, in domains where retrieval was already strong, such as Databricks DocsQA, finetuning didn’t add much—highlighting that finetuning works best when retrieval is a clear bottleneck.
Gartner®: Databricks Cloud Database Leader

How We Finetuned and Evaluated Embedding Models
Here are some of the more technical details of our synthetic data generation, finetuning, and evaluation.
Embedding Models
We finetuned two open-source embedding models:
- gte-large-en-v1.5 is a popular embedding model based on BERT Large (434M parameters, 1.75 GB). We chose to run experiments on this model because of its modest size and open licensing. This embedding model is also currently supported on the Databricks Foundation Model API.
- e5-mistral-7b-instruct belongs to a newer class of embedding models built on top of strong LLMs (in this case Mistral-7b-instruct-v0.1). Although e5-mistral-7b-instruct is better on the standard embedding benchmarks such as MTEB and is able to handle longer and more nuanced prompts, it is much larger than gte-large-en-v1.5 (since it has 7 billion parameters) and is slightly slower and more expensive to serve.
We then compared them against OpenAI’s text-embedding-3-large.
Evaluation Datasets
We evaluated all models on the following datasets from our Domain Intelligence Benchmark Suite (DIBS): FinanceBench, ManufactQA, and Databricks DocsQA.
| Dataset | Description | # Queries | # Corpus |
|---|---|---|---|
| FinanceBench | Questions about SEC 10-K documents generated by human experts. Retrieval is done over individual pages from a superset of 360 SEC 10-K filings. | 150 | 53,399 |
| ManufactQA | Questions and answers sampled from public forums of an electronic devices manufacturer. | 6,787 | 6,787 |
| Databricks DocsQA | Questions based on publicly available Databricks documentation generated by Databricks experts. | 139 | 7,561 |
We report recall@10 as our main retrieval metric; this measures whether the correct document is in the top 10 retrieved documents.
The golden standard for embedding model quality is the MTEB benchmark, which incorporates retrieval tasks such as BEIR as well as many other non-retrieval tasks. While models such as gte-large-en-v1.5 and e5-mistral-7b-instruct do well on MTEB, we were curious to see how they performed on our internal enterprise tasks.
Training Data
We trained separate models on synthetic data tailored for each of the benchmarks above:
| Training Set | Description | # Unique Samples |
| Synthetic FinanceBench | Queries generated from 2,400 SEC 10-K documents | ~6,000 |
| Synthetic Databricks Docs QA | Queries generated from public Databricks documentation. | 8,727 |
| ManufactQA | Queries generated from electronics manufacturing PDFs | 14,220 |
In order to generate the training set for each domain, we took existing documents and generated sample queries grounded in the content of each document using LLMs such as Llama 3 405B. The synthetic queries were then filtered for quality by an LLM-as-a-judge (GPT4o). The filtered queries and their associated documents were then used as contrastive pairs for finetuning. We used in-batch negatives for contrastive training, but adding hard negatives could further improve performance (see Appendix).
Hyperparameter Tuning
We ran sweeps across:
- Learning rate, batch size, softmax temperature
- Epoch count (1-3 epochs tested)
- Query prompt variations (e.g., "Query:" vs. instruction-based prompts)
- Pooling strategy (mean pooling vs. last token pooling)
All finetuning was done using the open source mosaicml/composer, mosaicml/llm-foundry, and mosaicml/streaming libraries on the Databricks platform.
How to Improve Vector Search and RAG on Databricks
Finetuning is only one approach for improving vector search and RAG performance; we list a few additional approaches below.
For Better Retrieval:
- Use a better embedding model: Many users unknowingly work with outdated embeddings. Simply swapping in a higher-performing model can yield immediate gains. Check the MTEB leaderboard for top models.
- Try hybrid search: Combine dense embeddings with keyword-based search for improved accuracy. Databricks Vector Search makes this easy with a one-click solution.
- Use a reranker: A reranker can refine results by reordering them based on relevance. Databricks provides this as a built-in feature (currently in Private Preview). Reach out to your Account Executive to try it.
For Better RAG:
- Optimize your prompts: Small tweaks in LLM prompting can improve responses dramatically. DSPy can help automate this process (see Build genAI apps using DSPy on Databricks).
- Upgrade your LLM: If retrieval is strong but answers are weak, consider using a better generative model.
- Finetune an LLM: If your domain is unique and you have enough data, finetuning a model like Llama 3 can further boost RAG quality. See Mosaic AI Model Training: Fine-Tune Your LLM on Databricks for Specialized Tasks and Knowledge for more details.
Get Started with Finetuning on Databricks
Finetuning embeddings can be an easy win for improving retrieval and RAG in your AI systems. On Databricks, you can:
- Finetune and serve embedding models on scalable infrastructure.
- Use built-in tools for vector search, reranking, and RAG.
- Quickly test different models to find what works best for your use case.
Ready to try it? We’ve built a reference solution to make fine-tuning easier—reach out to your Databricks Account Executive or Solutions Architect to get access.
Appendix
|
|
|
|
|
||||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 1: Comparison of gte-large-en-v1.5, e5-mistral-7b-instruct and text-embedding-3-large. Same data as Figure 1.
Generating Synthetic Training Data
For all datasets, the queries in the training set were not the same as the queries in the test set. However, in the case of Databricks DocsQA (but not FinanceBench or ManufactQA), the documents used to generate synthetic queries were the same documents used in the evaluation set. The focus of our study is to improve retrieval on particular tasks and domains (as opposed to a zero-shot, generalizable embedding model); we therefore see this as a valid approach for certain production use cases. For FinanceBench and ManufactQA, the documents used to generate synthetic data did not overlap with the corpus used for evaluation.
There are various ways to select negative passages for contrastive training. They can either be selected randomly, or they can be pre-defined. In the first case, the negative passages are selected from within the training batch; these are often referred to as "in-batch negatives" or “soft negatives”. In the second case, the user preselects text examples that are semantically difficult, i.e. they are potentially related to the query but slightly incorrect or irrelevant. This second case is sometimes called "hard negatives". In this work, we simply used in-batch negatives; the literature indicates that using hard negatives would likely lead to even better results.
Finetuning Details
For all finetuning experiments, maximum sequence length is set to 2048. We then evaluated all checkpoints. For all benchmarking, corpus documents were truncated to 2048 tokens (not chunked), which was a reasonable constraint for our particular datasets. We choose the strongest baselines on each benchmark after sweeping over query prompts and pooling strategy.
Improving RAG Performance
A RAG system consists of both a retriever and a generative model. The retriever selects a set of documents relevant to a particular query, and then feeds them to the generative model. We selected the best finetuned gte-large-en-v1.5 models and used them for the first retrieval stage of a simple RAG system (following the general approach described in Long Context RAG Performance of LLMs and The Long Context RAG Capabilities of OpenAI o1 and Google Gemini). In particular, we retrieved k=10 documents each with a maximum length of 512 tokens and used GPT4o as the generative LLM. Final accuracy was evaluated using an LLM-as-a-judge (GPT4o).
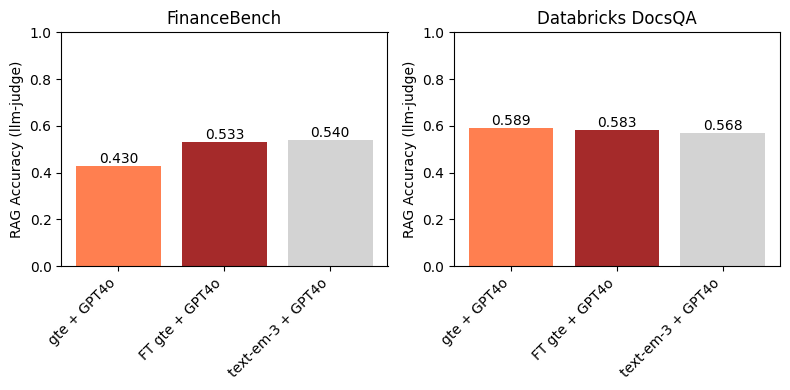
On FinanceBench, Figure 3 shows that using a finetuned embedding model leads to an improvement in downstream RAG accuracy. Additionally, it is competitive with text-embedding-3-large. This is expected, since finetuning gte led to a large improvement in Recall@10 over baseline gte (Figure 1). This example highlights the efficacy of embedding model finetuning on particular domains and datasets.
On the Databricks DocsQA dataset, we do not find any improvements when using the finetuned gte model above baseline gte. This is somewhat expected, since the margins between the baseline and finetuned models in Figures 1 and 2 are small. Interestingly, even though text-embedding-3-large has (slightly) higher Recall@10 than any of the gte models, it does not lead to higher downstream RAG accuracy. As shown in Figure 1, all the embedding models had relatively high Recall@10 on the Databricks DocsQA dataset; this indicates that retrieval is likely not the bottleneck for RAG, and that finetuning an embedding model on this dataset is not necessarily the most fruitful approach.
We would like to thank Quinn Leng and Matei Zaharia for feedback on this blogpost.