What’s New in Data Engineering and Streaming at Data + AI Summit 2023

It's Thursday and we are fresh off a week of announcements from the 2023 Data + AI Summit. The theme of this year's Summit has been "Generation AI," a theme exploring LLMs, lakehouse architectures and all the latest innovations in data and AI.
Supporting the innovation of modern generative AI is the modern data engineering stack afforded by Delta Lake, Spark, and the Databricks Lakehouse Platform. The Databricks Lakehouse provides data engineers with advanced capabilities to help them tackle the challenges of building and orchestrating sophisticated data pipelines with solutions such as Delta Live Tables and Databricks Workflows - integral tools for data engineering on the Databricks Lakehouse Platform across batch and streaming data.
In this blog post, we are excited to recap the key data engineering and data streaming highlights and announcements from the week. Let's dive in and explore the advancements that are set to shape the future of data engineering and data streaming on the Databricks Lakehouse Platform.
Data Streaming with Delta Live Tables and Spark Structured Streaming
The Databricks Lakehouse Platform dramatically simplifies data streaming to deliver real-time analytics, machine learning and applications on one platform. Foundationally built on Spark Structured Streaming, the most popular open-source streaming engine, tools like Delta Live Tables empower data engineers to build streaming data pipelines for all their real-time use cases.
Here are a few of the biggest data streaming developments we blogged about during the week:
- Delta Live Tables <> Unity Catalog Integration: Unity Catalog now supports Delta Live Tables pipelines! Now any data team can define and execute fine-grained data governance policies on data assets produced by Delta Live Tables. Read more here.
- Databricks SQL Materialized Views and Streaming Tables: The best data warehouse gets the best of data engineering with incremental ingest and computation, unlockng infrastructure-free data pipelines that are simple to set up and deliver fresh data to the business. Read more here.
- 1 Year of Project Lightspeed: Last year we announced Project Lightspeed, an initiative dedicated to faster and simpler stream processing with Apache Spark. This year, we took a look back at the innovation and progress over the last year of Project Lightspeed, including some recent announcements like subsecond latency. You can read more here.
Learn more about the above announcements in these two sessions (soon available on demand):
- Project Lightspeed Update: Unlocking the Power of Real-Time Data Processing
- Delta Live Tables A to Z: Best Practices for Modern Data Pipelines
Orchestration with Databricks Workflows
Databricks Workflows is the unified orchestration tool fully integrated with the Databricks Lakehouse offering users a simple workflow authoring experience, full observability with actionable insights and proven reliability trusted by thousands of Databricks customers every day to orchestrate their production workloads.
During the summit, the Workflows product team offered a glimpse into the roadmap for the coming year. Here are several exciting items on the roadmap to look out for in the coming months:
- Serverless compute - For both Databricks Workflows and Delta Live Tables, abstracting away cluster configurations for data engineers and making ETL and orchestration even more simple, reliable, scalable and cost-efficent.
- Enhanced control flow for Workflows - Allowing users to create more sophisticated workflows - fully parameterized, executed dynamically and defined as modular DAGs for higher efficiency and easy debugging.
- Orchestration across teams - The ability to manage complex data dependencies across organizational boundaries, such as triggering a workflow when data gets updated or when another team's workflow finished successfully.
- Easy CI/CD, version control, and Workflows as code - Introducing a new end-to-end CI/CD flow with full git integration, and the ability to express Workflows as Python.
Learn more on the above by checking out the session What's new in Databricks Workflows? (soon available on demand).
Customer Momentum
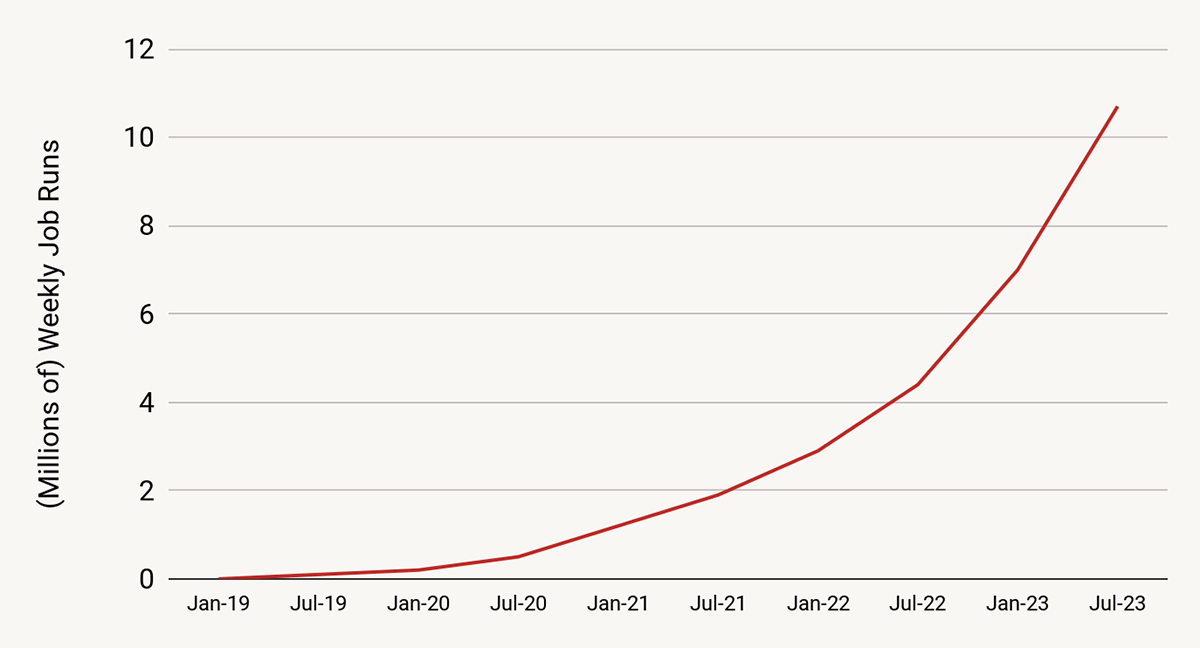
Organizations are increasingly turning to the Databricks Lakehouse Platform as the best place to run data engineering and data streaming workloads. The growth of streaming job runs, for example, is still growing at over 150% per year and recently crossed 10 million streaming jobs per week.
Over a thousand talks were submitted for this year's Data + AI Summit, among them many Databricks customers. We're very happy to feature some of the amazing work our customers are doing with data engineering and data streaming on the lakehouse, check out a small sample of these sessions here:
- Akamai - Taking Your Cloud Vendor to the Next Level: Solving Complex Challenges with Azure Databricks
- AT&T - Building and Managing a Data Platform for a Delta Lake that Exceeds 13 Petabytes and Has Thousands of Users
- Block - Change Data Capture with Delta Live Tables (Introduction to Data Streaming on the Lakehouse)
- Corning - Data Engnieering with Databricks Workflows (Introduction to Data Engineering on the Lakehouse)
- Discovery+ - Deploying the Lakehouse to Improve the Viewer Experience
- Grammarly - Deep Dive into Grammarly's Data Platform
- Honeywell - Using Cisco Spaces Firehose API as a Stream of Data for Real-Time Occupancy Modelling
- T-Mobile - The Value of the Lakehouse: Articulating the Benefit of a Modern Data Platform
Weren't Able to Attend This Year's Summit?
Look no further, we have you covered! You can find all Data Engineering and Data Streaming sessions here (sessions will be made available on-demand shortly after the conclusion of the conference). A good starting point for those who are new to the Databricks Lakehouse platform are these two introductory sessions:
See you next year at Data + AI Summit 2024!
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read