

Databricks AutoML allows you to quickly generate baseline models and notebooks. ML experts can accelerate their workflow by fast-forwarding through the usual trial-and-error and focus on customizations using their domain knowledge, and citizen data scientists can quickly achieve usable results with a low-code approach.
Jump-start new ML projects
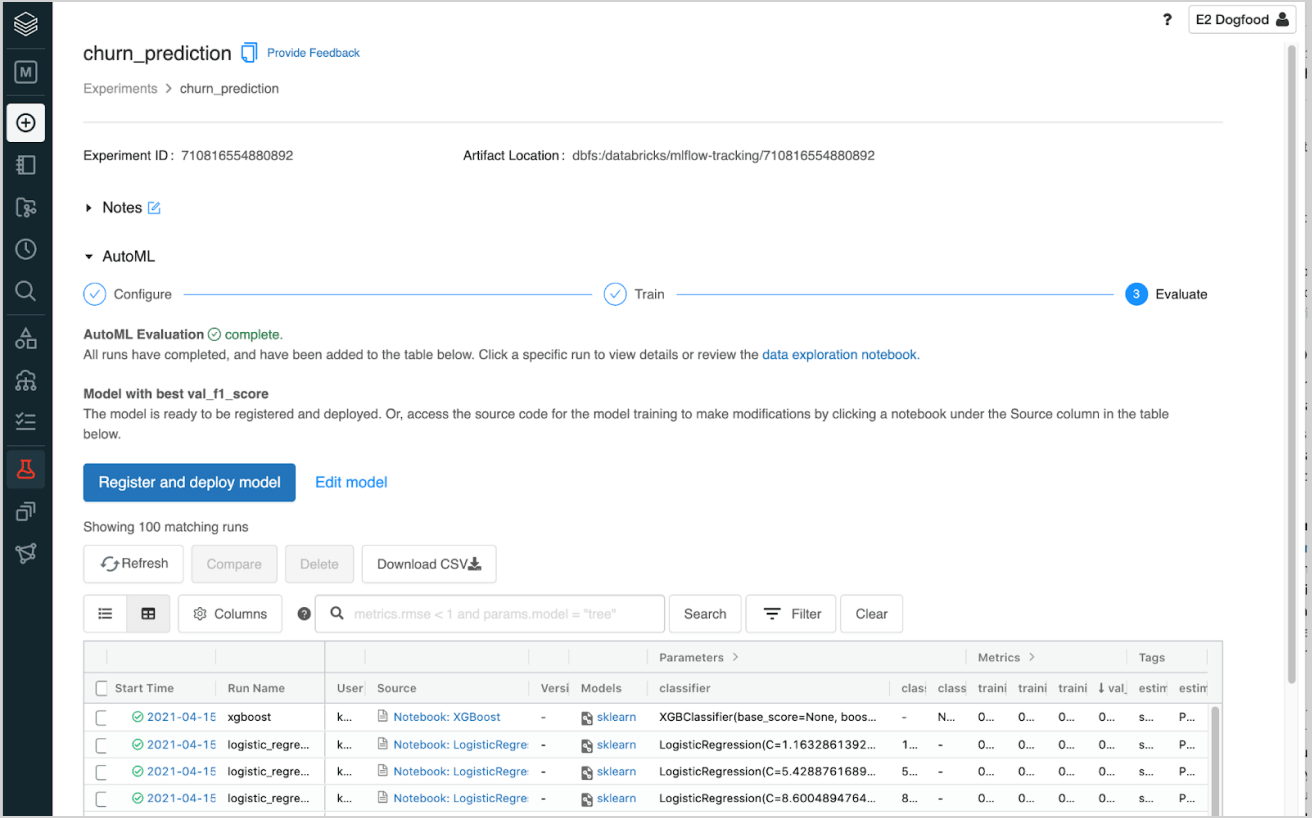
Databricks AutoML provides the training code for every trial run to help data scientists jump-start their development. Data scientists can use this to quickly assess the feasibility of using a data set for machine learning (ML) or to get a quick sanity check on the direction of an ML project.
No ML problem too big
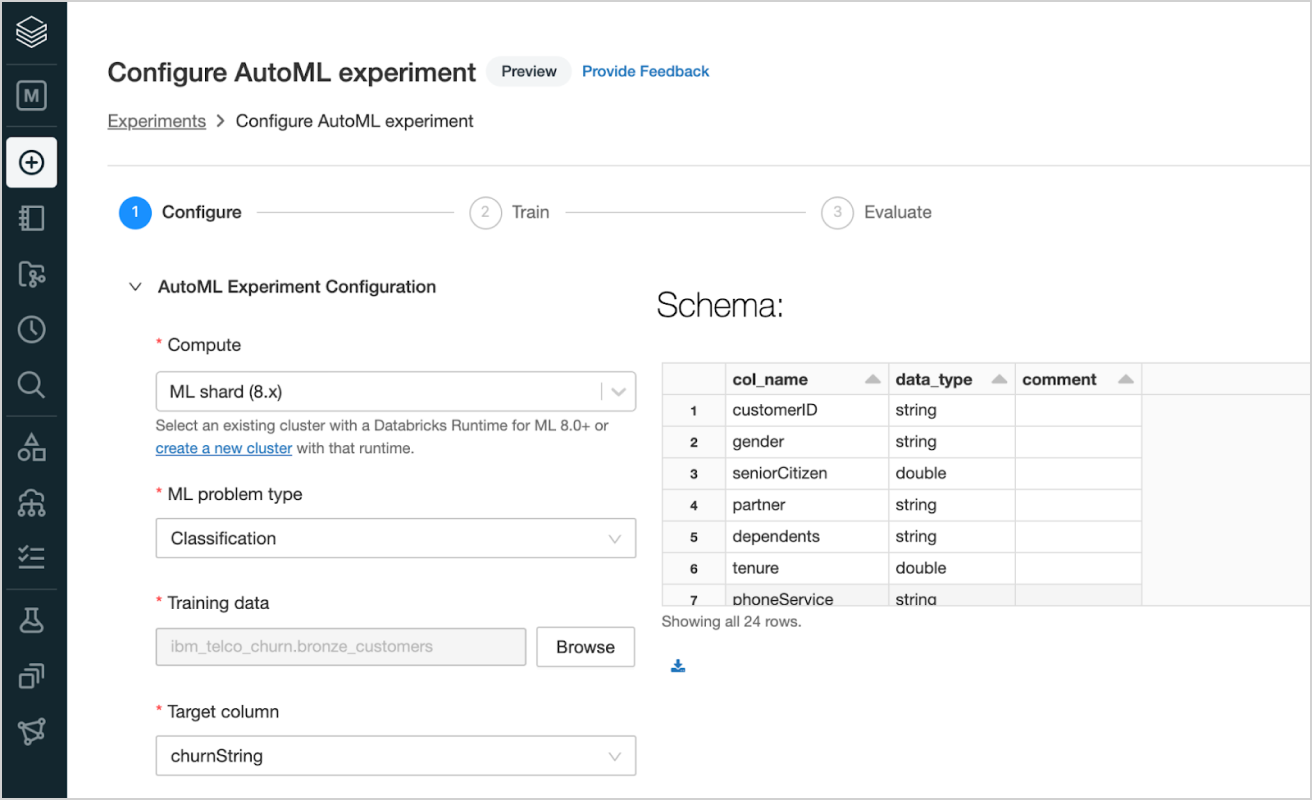
Leverage AutoML to tackle a variety of machine learning problems ranging from classification, regression, and forecasting. AutoML uses multiple algorithms from a variety of machine learning libraries for each problem type, and lets you pick the best for your problem.
Automate the grind of machine learning
Automatically set up your machine learning project with the training libraries, MLflow integration for experiment tracking and built-in ML best practices such as training and testing split, normalizing of features and hyperparameter tuning.

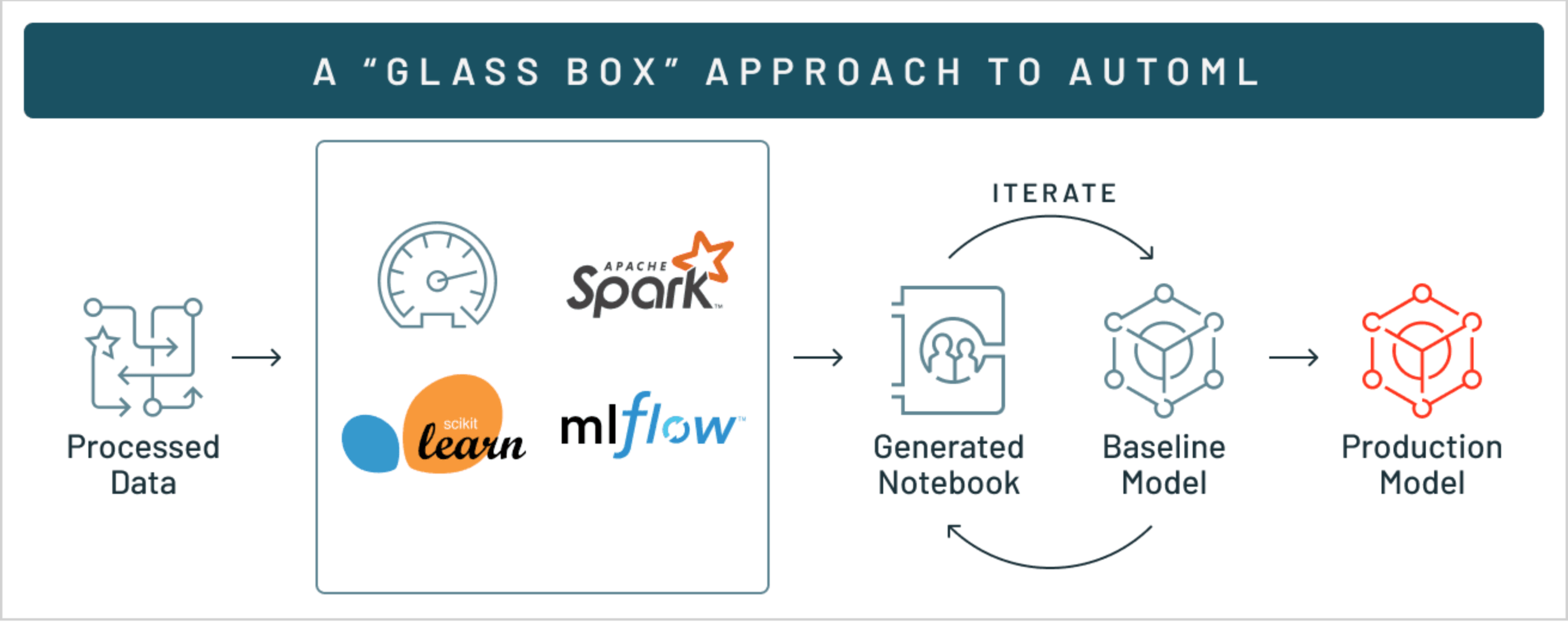
A “glass box” approach to AutoML
Use generated editable notebooks to easily customize baseline models with your domain expertise. You can also leverage these notebooks to explain how your AutoML models were trained to fulfill audit and compliance requirements.
Resources
Virtual events
Documentation
eBooks
Ready to get started?