Vector Search
A highly performant vector database with governance built-in

Unlock generative AI’s full potential with Databricks Vector Search
Vector Search is a serverless vector database
seamlessly integrated in the Data Intelligence Platform
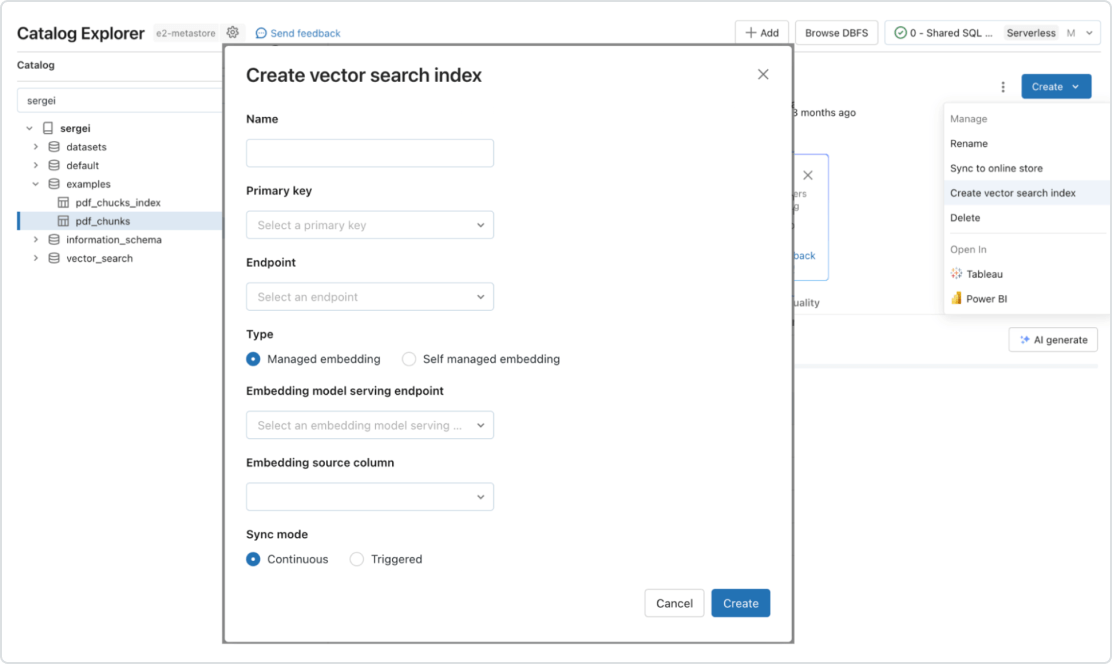
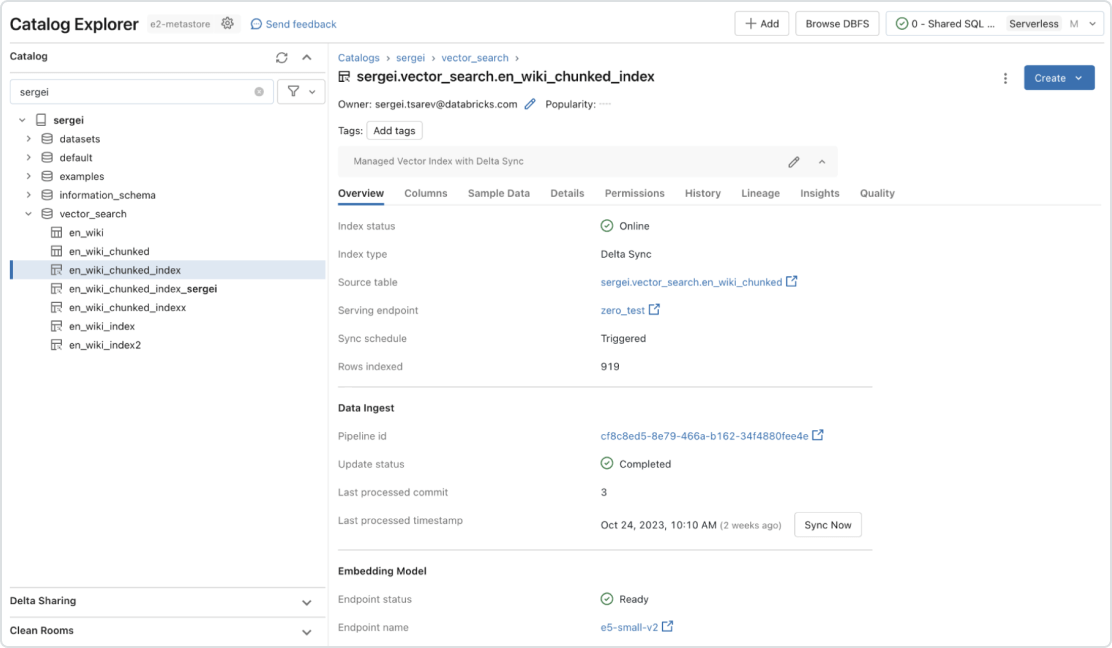
Unlike other databases, Databricks Vector Search supports automatic data synchronization from source to index, eliminating complex and costly pipeline maintenance. It leverages the same security and data governance tools organizations have already built for peace of mind. With its serverless design, Databricks Vector Search easily scales to support up to 1 billion embeddings per endpoint with a range of 30-200 queries per second.
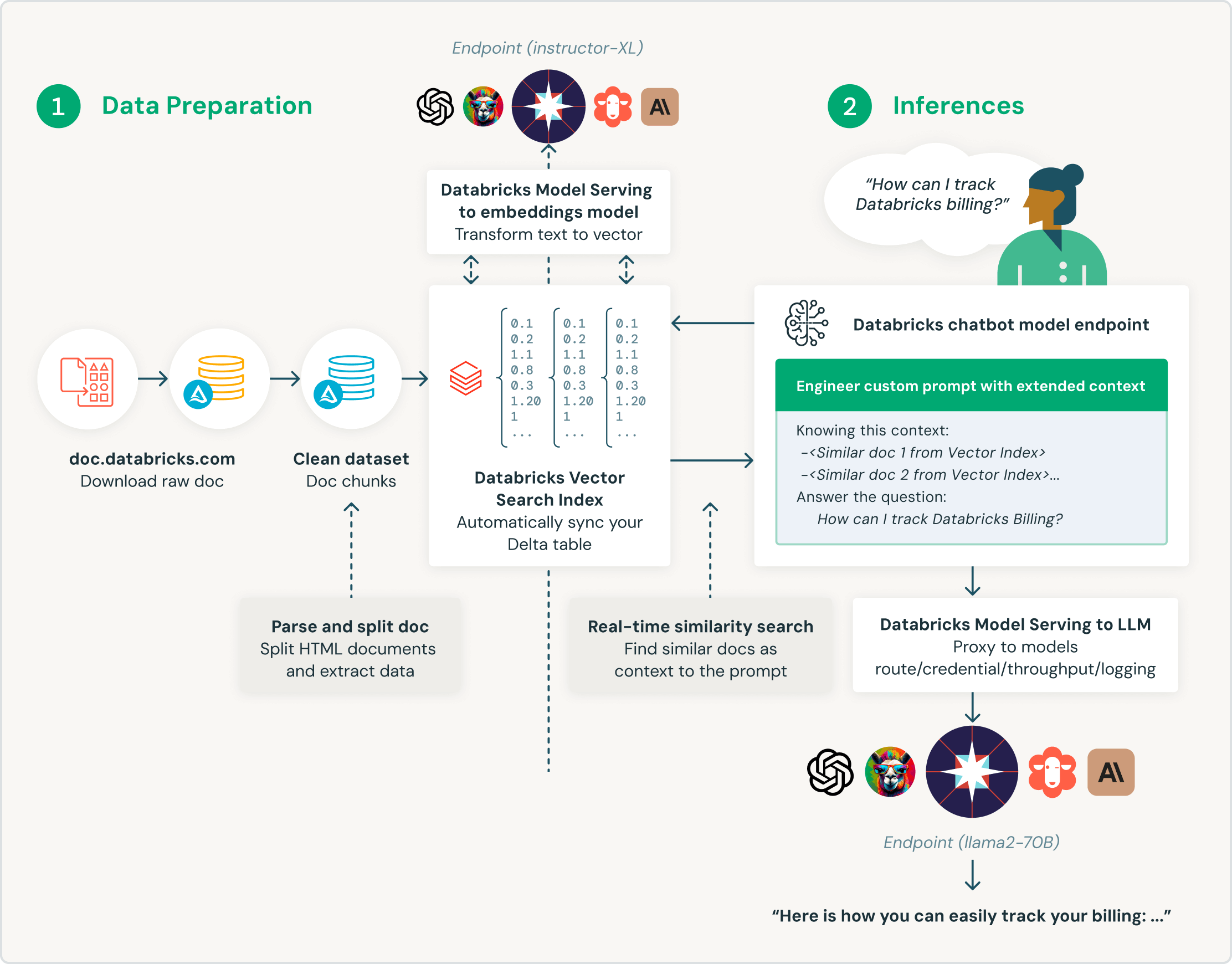
Built for retrieval augmented generation (RAG)
Databricks Vector Search is purpose-built for customers to augment their large language models (LLMs) with enterprise data. Specifically designed for retrieval augmented generation (RAG) applications, Databricks Vector Search delivers similarity search results, enriching LLM queries with context and domain knowledge, and improving accuracy and quality of results.
Automated real-time pipelines
Real-time synchronization of source data by automatically updating the corresponding vector index as new data is introduced, modified or removed. Under the hood, Databricks does the embedding vector generation and management, and automatically manages failures, handles retries, optimizes throughput, and does automatic batch size tuning and autoscaling without any intervention needed.
Built-in governance
The unified interface defines policies on data, with fine-grained access control on embeddings. With built-in integration to Unity Catalog, Vector Search shows data lineage and tracking automatically without the need for additional tools or security policies. This ensures LLM models won’t expose confidential data to users who shouldn’t have access.
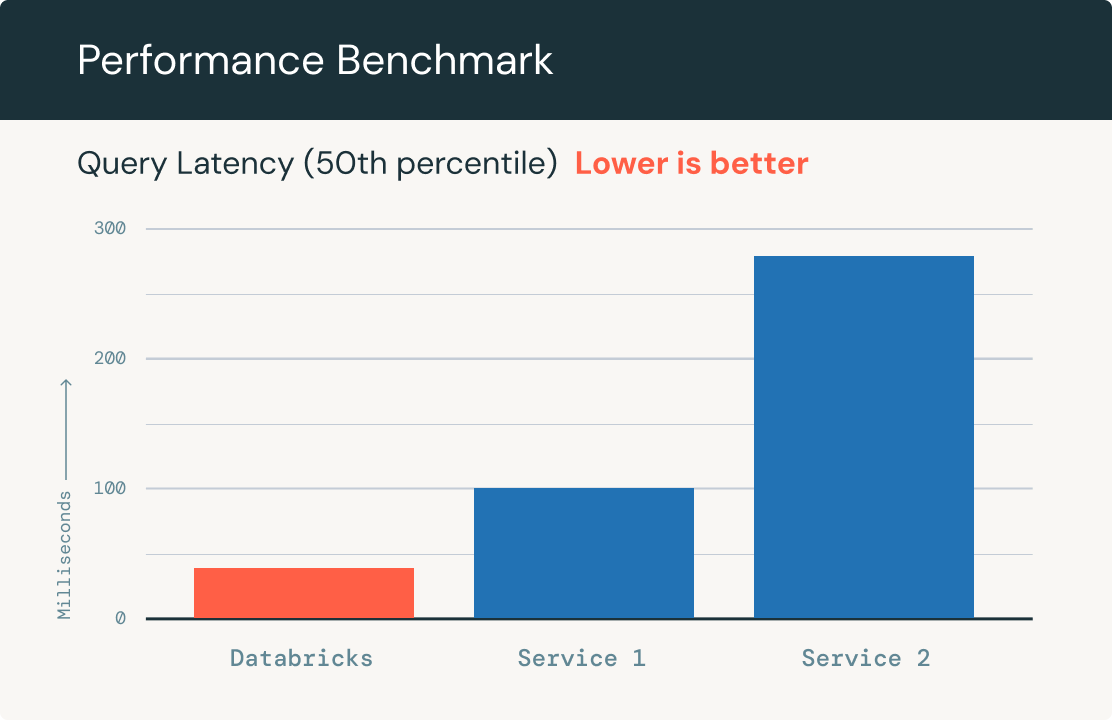
Fast query performance
Automatically scales out to handle billions of embeddings in an index and thousands of queries per second. It shows up to 5x faster performance than other leading vector databases on up to 1 million OpenAI embedding datasets.
