Improvements to Kafka integration of Spark Streaming
by Cody Koeninger, Davies Liu and Tathagata Das
Apache Kafka is rapidly becoming one of the most popular open source stream ingestion platforms. We see the same trend among the users of Spark Streaming as well. Hence, in Apache Spark 1.3, we have focused on making significant improvements to the Kafka integration of Spark Streaming. This has resulted the following additions:
- New Direct API for Kafka - This allows each Kafka record to be processed exactly once despite failures, without using Write Ahead Logs. This makes Spark Streaming + Kafka pipelines more efficient while providing stronger fault-tolerance guarantees.
- Python API for Kafka - So that you can start processing Kafka data purely from Python.
In this article, we are going to discuss these improvements in more detail.
Direct API for Kafka
[Primary Contributor - Cody]
Spark Streaming has supported Kafka since its inception, and Spark Streaming has been used with Kafka in production at many places (see this talk). However, the Spark community has demanded better fault-tolerance guarantees and stronger reliability semantics overtime. To meet this demand, Spark 1.2 introduced Write Ahead Logs (WAL). It ensures that no data received from any reliable data sources (i.e., transactional sources like Flume, Kafka, and Kinesis) will be lost due to failures (i.e., at-least-once semantics). Even for unreliable (i.e. non-transactional) sources like plain old sockets, it minimizes data loss.
However, for sources that allow replaying of data streams from arbitrary positions in the streams (e.g. Kafka), we can achieve even stronger fault-tolerance semantics because these sources let Spark Streaming have more control on the consumption of the data stream. Spark 1.3 introduces the concept of a Direct API, which can achieve exactly-once semantics even without using Write Ahead Logs. Let’s look at the details of Spark’s direct API for Apache Kafka.
How did we build it?
At a high-level, the earlier Kafka integration worked with Write Ahead Logs (WALs) as follows:
- The Kafka data is continuously received by Kafka Receivers running in the Spark workers/executors. This used the high-level consumer API of Kafka.
- The received data is stored in Spark’s worker/executor memory as well as to the WAL (replicated on HDFS). The Kafka Receiver updated Kafka’s offsets to Zookeeper only after the data has been persisted to the log.
- The information about the received data and its WAL locations is also stored reliably. On failure, this information is used to re-read the data and continue processing.
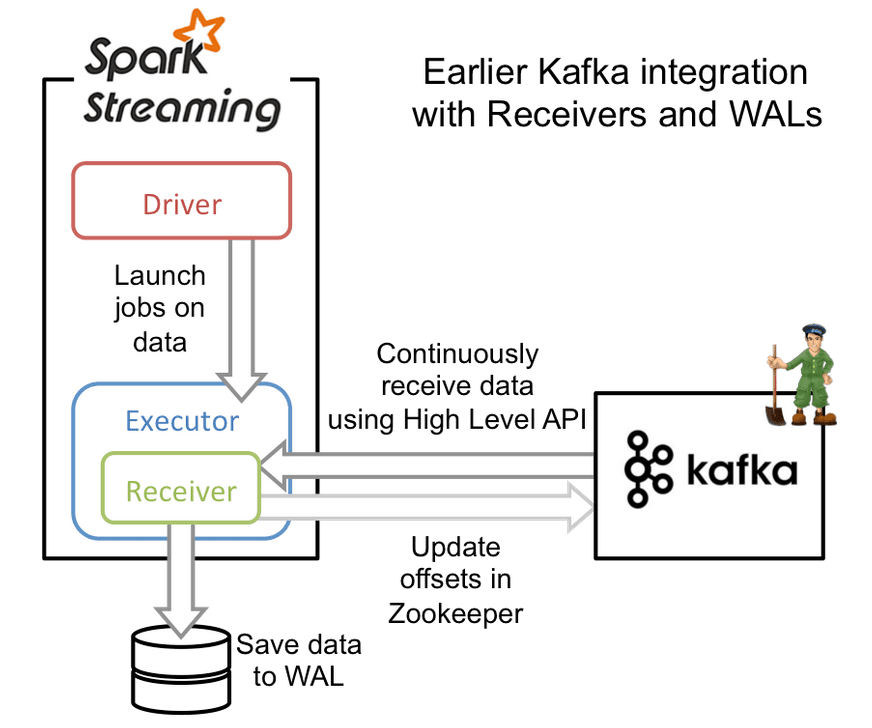
While this approach ensures that no data from Kafka is lost, there is still a small chance that some records may get processed more than once due to failures (that is, at-least-once semantics). This can occur when some received data is saved reliably to WAL but the system fails before updating the corresponding Kafka offsets in Zookeeper. This leads to an inconsistency - Spark Streaming considers that data to have been received, but Kafka considers that the data was not successfully sent as the offset in Zookeeper was not updated. Hence, Kafka will send the data again after the system recovers from the failure.
This inconsistency arises because the two systems cannot be atomically updated with the information that describes what has already been sent. To avoid this, only one system needs to maintain a consistent view of what has been sent or received. Additionally, that system needs to have complete control over the replay of the data stream during the recovery from failures. Therefore, we decided to keep all the consumed offset information only in Spark Streaming, which can use Kafka’s Simple Consumer API to replay data from arbitrary offsets as required due to failures.
To build this (primary contributor was Cody), the new Direct Kafka API takes a completely different approach from Receivers and WALs. Instead of receiving the data continuously using Receivers and storing it in a WAL, we simply decide at the beginning of every batch interval what is the range of offsets to consume. Later, when each batch’s jobs are executed, the data corresponding to the offset ranges is read from Kafka for processing (similar to how HDFS files are read). These offsets are also saved reliably (with checkpoints) and used to recompute the data to recover from failures.
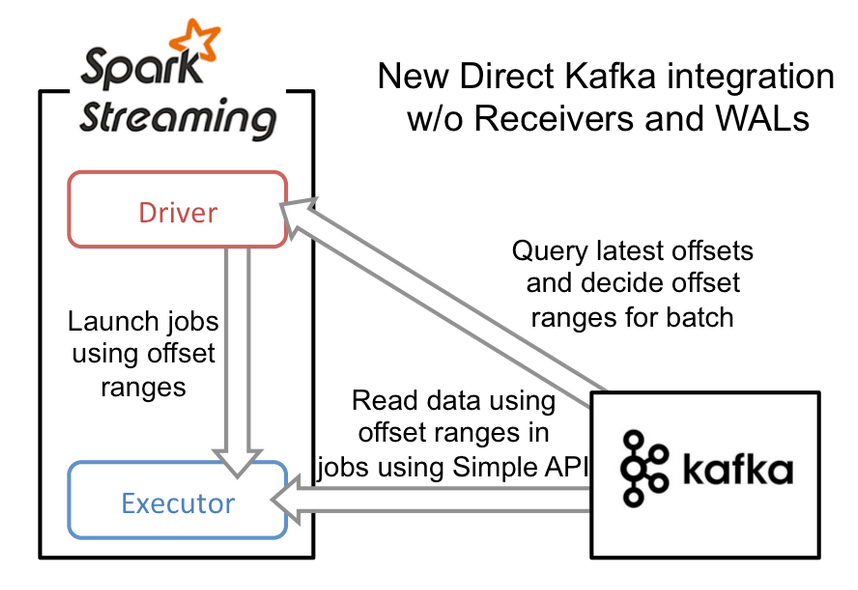
Note that Spark Streaming can reread and reprocess segments of the stream from Kafka to recover from failures. However, due to the exactly-once nature of RDD transformations, the final recomputed results are exactly same as that would have been without failures.
Thus this direct API eliminates the need for both WALs and Receivers for Kafka, while ensuring that each Kafka record is effectively received by Spark Streaming exactly once. This allows one to build a Spark Streaming + Kafka pipelines with end-to-end exactly-once semantics (if your updates to downstream systems are idempotent or transactional). Overall, it makes such streaming processing pipelines more fault-tolerant, efficient, and easier to use.
How to use it?
The new API is simpler to use than the previous one.
// Define the Kafka parameters, broker list must be specified
val kafkaParams = Map("metadata.broker.list" -> "localhost:9092,anotherhost:9092")
// Define which topics to read from
val topics = Set("sometopic", "anothertopic")
// Create the direct stream with the Kafka parameters and topics
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](streamingContext, kafkaParams, topics)
Since this direct approach does not have any receivers, you do not have to worry about creating multiple input DStreams to create more receivers. Nor do you have to configure the number of Kafka partitions to be consumed per receiver. Each Kafka partition will be automatically read in parallel. Furthermore, each Kafka partition will correspond to a RDD partition, thus simplifying the parallelism model.
In addition to the new streaming API, we have also introduced KafkaUtils.createRDD(), which can be used to run batch jobs on Kafka data.
// Define the offset ranges to read in the batch job
val offsetRanges = Array(
OffsetRange("some-topic", 0, 110, 220),
OffsetRange("some-topic", 1, 100, 313),
OffsetRange("another-topic", 0, 456, 789)
)
// Create the RDD based on the offset ranges
val rdd = KafkaUtils.createRDD[String, String, StringDecoder, StringDecoder](sparkContext, kafkaParams, offsetRanges)
If you want to learn more about the API and the details of how it was implemented, take a look at the following.
- Spark Streaming + Kafka Integration Guide
- Cody’s blog post with more details
- Full word count example of the Direct API in Scala and Java
- Scala and Java documentation of the Direct API
- Updated Fault-tolerance Semantics in Spark Streaming Programming Guide
Python API for Kafka
[Primary Contributor - Davies]
In Spark 1.2, the basic Python API of Spark Streaming was added so that developers could write distributed stream processing applications purely in Python. In Spark 1.3, we have extended the Python API to include Kafka (primarily contributed by Davies Liu). With this, writing stream processing applications in Python with Kafka becomes a breeze. Here is a sample code.
kafkaStream = KafkaUtils.createStream(streamingContext,
"zookeeper-server:2181", "consumer-group", {"some-topic": 1})
lines = kafkaStream.map(lambda x: x[1])
Instructions to run the example can be found in the Kafka integration guide. Note that for running the example or any python applications using the Kafka API, you will have to add the Kafka Maven dependencies to the path. This is can be easily done in Spark 1.3 as you can directly add Maven dependencies to spark-submit (recommended way to launch Spark applications). See the “Deploying” section in the Kafka integration guide for more details.
Also note that this is using the earlier Kafka API. Extending Python to the Direct API is in progress and expected to be available in Spark 1.4. Additionally, we want to add Python APIs for the rest of the built-in sources to the to achieve parity between the Scala, Java and Python streaming APIs.
Future Directions
We will continuously improve the stability and performance of Kafka integration. Some of the improvements we intend to make are as follows:
- Automatically updating Zookeeper as batches complete successfully, to make Zookeeper based Kafka monitoring tools work - SPARK-6051
- Python API for the Direct API - SPARK-5946
- Extending this direct API approach to Kinesis - SPARK-6599
- Connection pooling for Kafka Simple Consumer API across batches
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.