Databricks Engineering Interns & Impact in Summer 2018
Thanks to our awesome interns!
This summer, our Engineering interns at Databricks did amazing work. Our interns, working on teams from Developer Tools to Machine Learning, built features and improvements which are already impacting our customers and the Apache Spark and AI communities.

Spending a summer at Databricks
Databricks Engineering internships are a mix of impact, learning, and fun. Here’s a taste of what interns got to do this summer.
Priorities → Production: Before our interns arrived, Engineering leads worked with Product Management to select projects based on immediate customer needs and feedback. Over the summer, interns took advantage of our rapid cloud-based deployment to move their code to production. Before they finished many interns adopted our data-driven culture to watch the adoption of features, identify issues early, and iterate.
Mentorship: Interns were paired with tech mentors who facilitated their technical work and managers who made sure they were enabled for success. But we also provided other sources of mentorship and learning via chats with co-founders, one-on-one meetings with Engineering Directors, and interactions with company leadership in areas like Field Engineering, Sales, and Marketing.
Fun events: Interns were able to hang out with their team, meet others throughout the company, and explore the heart of San Francisco and the Bay Area in general. Company-wide events included the Data + AI Summit, weekly Happy Hours, and regular board game nights. We also went out for a Giants game, bowling, trampoline dodgeball, an Engineering hackathon, and team lunches. It was a full summer. :)
Impacting our product
Almost every Engineering team worked with an intern, and their projects speak for themselves. Here is a sample of intern projects.
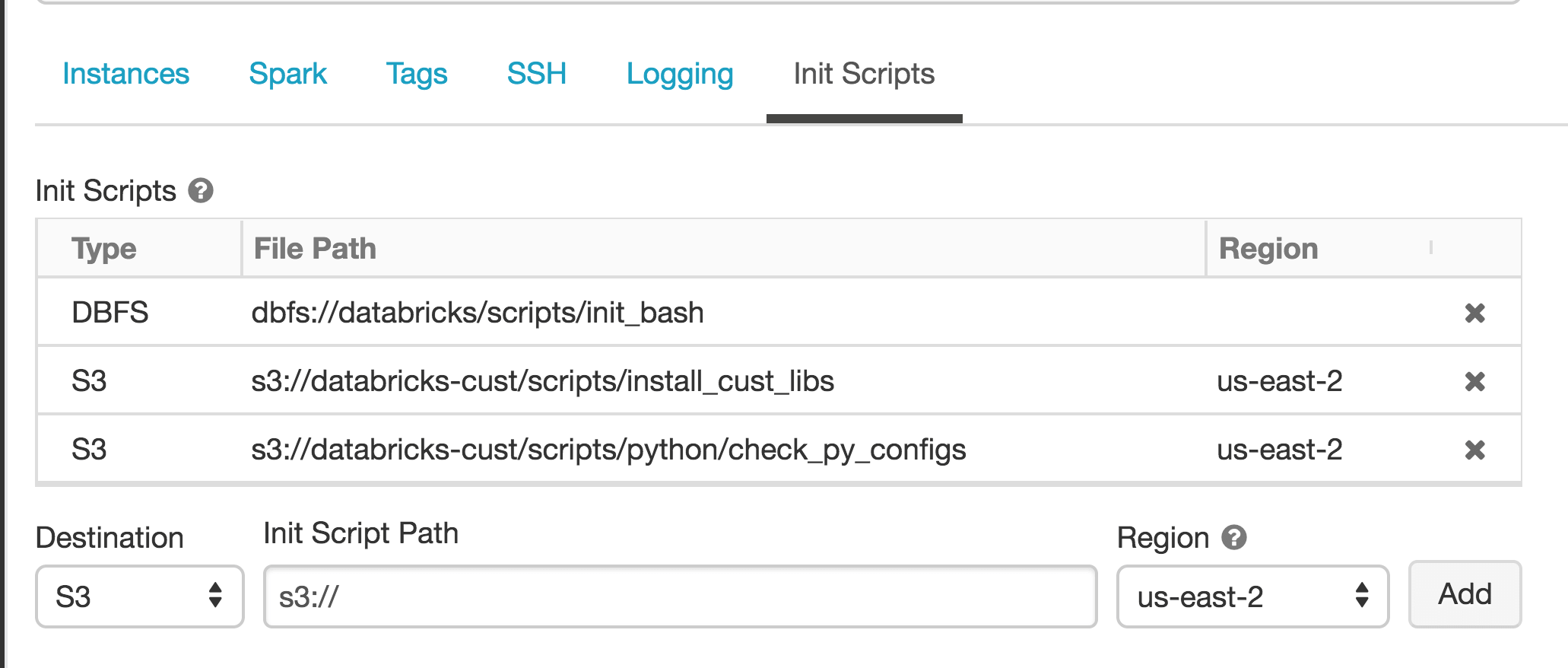
Aayush Bhasin -- Cluster-Scoped Init Scripts
Aayush worked with the Clusters team to design and implement Cluster-scoped Init Scripts, improving scalability and ease of use. Init Scripts are shell scripts that run during the startup of each cluster node before the Apache Spark driver or worker JVM starts. Databricks customers use Init Scripts for various customizations such as installing libraries, launching background processes, or applying enterprise security policies. This improved Init Script version offers many improvements over the previous version, which is now deprecated. Find out more in this blog post!
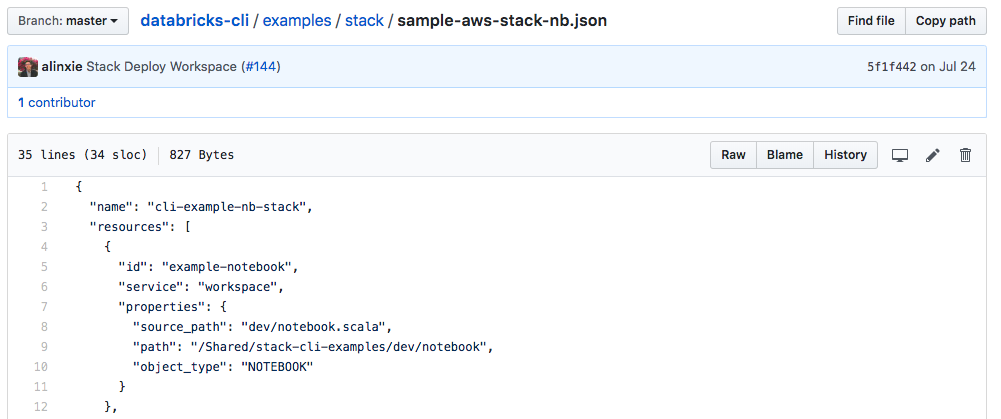
Andrew Linxie -- Databricks Stack CLI (Deployment Tool For ETL Pipelines)
Andrew worked with the Data team to build a new stack deployment component in the Databricks CLI. This Stack CLI provides a way to define and deploy a stack of resources (notebooks, jobs, files in DBFS, etc.) to Databricks workspaces. With this tool, users can efficiently set up complex ETL pipelines on Databricks. He also developed an internal tool based on Click and jsonnet which extends the Databricks CLI with additional integration for Bazel and HashiCorp Vault. His intern project greatly improved the way our engineers and customers manage data pipelines on Databricks!
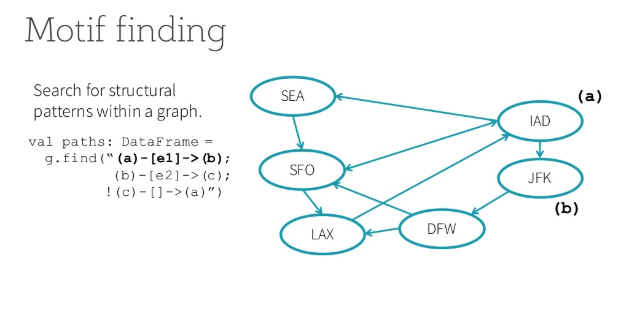
Bohan Zhang -- Optimizing GraphFrames
Bohan worked with the ML Algorithms team to improve GraphFrames, a Spark Package for graph analytics built on top of Apache Spark DataFrames. After a brief analysis of the Graph Analytics market, Bohan selected a few high-impact areas for improvement. He optimized the Connected Components by modifying the algorithm to achieve 3-4x speedups, and he improved Motif Finding’s use of the Spark SQL query optimizer to achieve 10-20x speedups for certain queries. These improvements will impact workloads for some of our biggest customers!
Caroline Moore -- Azure Databricks Trials
Caroline worked with the Growth team to build a trial experience on Azure Databricks which enables customers to try out the Azure Databricks platform without spending a lot of money. It both reduced friction for new customers to try out the product and enabled the marketing team at Databricks and Microsoft to build lead generation and nurture pipelines. Caroline was involved in all parts of the release of this feature, including design, implementation, and rollout. The project was a large success as there were more than 500 customers who launched a trial workspace within 1 month of launch!

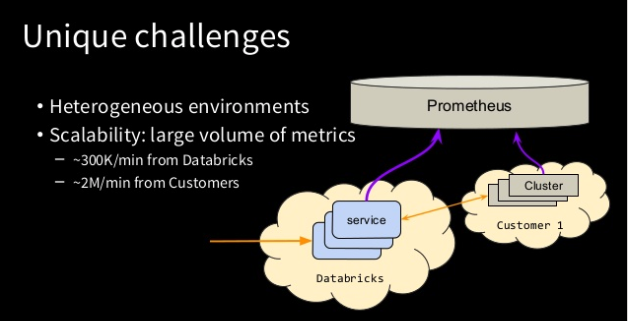
Haolan Ye -- Centralized Logging For Kubernetes Services (EFK)
Haolan worked with the Cloud team, building a centralized logging system for Kubernetes services using Elasticsearch, Fluentd, and Kibana (EFK). Databricks heavily uses Kubernetes as a Docker orchestrator, and the number of services we manage is growing quickly. In order to provide a unified log view over all the services, Haolan used the EFK stack. Haolan investigated and made several changes in each component of EFK to properly fit it into the Databricks Kubernetes environment and even had a chance to build dashboards for EFK uptime by integrating it with our Prometheus deployment. His intern project completely changes the way Databricks engineers interact with Kubernetes service logs!
Juntai Zheng -- MLFlow Apps
Juntai worked with the ML Platform team on MLFlow, an open source platform for the machine learning lifecycle. Juntai built a set of MLflow apps that demonstrate MLflow’s capabilities and offer the community examples to learn from. The project mlflow-apps helps users get a jump start on using MLflow by providing concrete examples of usage. Juntai also implemented two new MLflow features: running ML projects from Git subdirectories and TensorFlow integration. Find out more in this blog post!
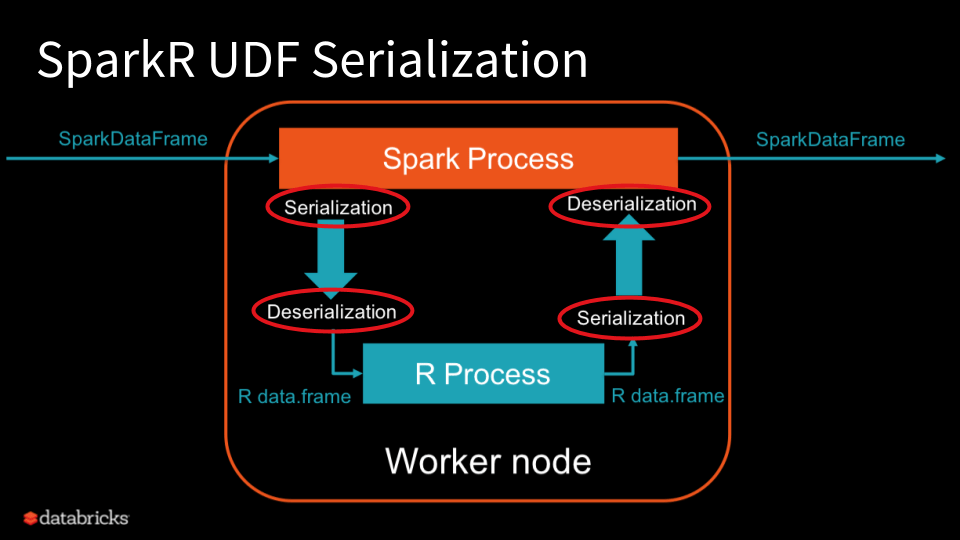
Liang Zhang -- SparkR UDF performance
Liang worked with the ML Runtime team to improve backend performance for SparkR User-Defined Functions (UDFs). SparkR UDFs open up opportunities for big data workloads running on Apache Spark to embrace R’s rich package ecosystem. Some of our biggest customers use the SparkR UDF API to blend R’s sophisticated packages into their ETL pipeline, applying transformations that go beyond Spark’s built-in functions on the distributed Spark DataFrame. Customers also use R UDFs for parallel simulations and hyper-parameter tuning. The SparkR UDF API transfers data between the Spark JVM and R process. This bridge between R and JVM has been very slow. In this project, Liang made the bridge between R and Spark on Databricks much more efficient. Find out more in this blog post!
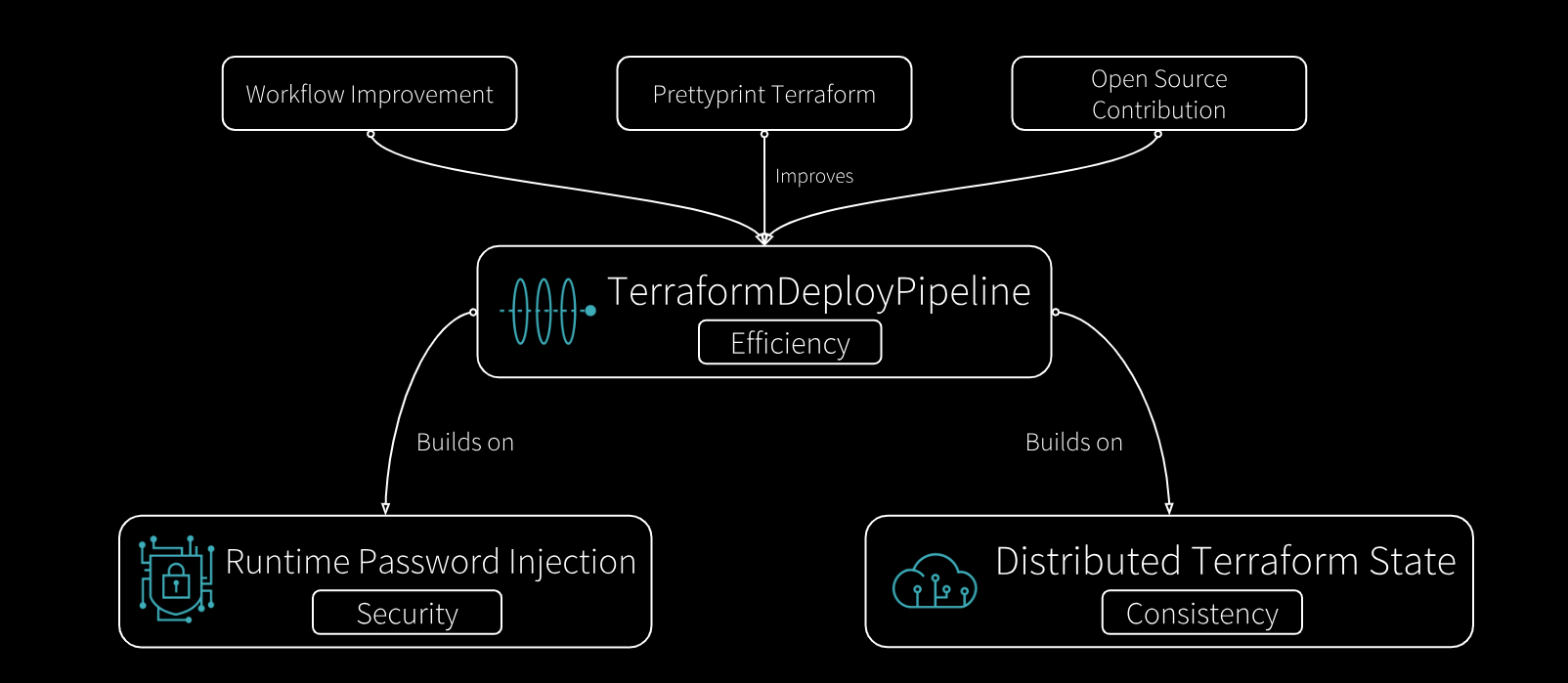
Ziheng Liao -- Terraform Deploy Pipeline (Democratizing Cloud Infrastructure)
Ziheng worked with the Cloud & Observability teams to build the Terraform Deploy Pipeline, a service for coordinating and deploying cloud provider infrastructure resources. Previous to his internship, deploying much of Databricks' cloud infrastructure required coordination between service teams and infrastructure teams. These processes used to take hours or even days. With his contributions, teams can now securely deploy version-controlled resources to any environment in minutes via a self-service UI portal. He also added support to deploy templatized resources with dynamically injected credentials, enabling use cases that bootstrap resources with passwords, such as managed MySQL databases. This pipeline service significantly improves the velocity of Databricks' operations on our self-managed cloud platform. Read about this blog here.
Looking to next year
We’re already looking forward to this coming year! If you’re interested in an internship at Databricks, contact Lucy Xu lucy@databricks.com>. We’re always looking for talented engineers who care about impact, personal growth, and building a fun & innovative company together!
Learning more
A few of our interns wrote up more about their projects in separate blog posts. Check them out:
- Introducing Cluster-scoped Init Scripts
- Introducing mlflow-apps: A Repository of Sample Applications for MLflow
- 100x Faster Bridge between Apache Spark and R with User-Defined Functions on Databricks
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.