Databricks and Informatica Accelerate Development and Complete Data Governance for Intelligent Data Pipelines
The value of analytics and machine learning to organizations is well understood. Our recent CIO survey showed that 90% of organizations are investing in analytics, machine learning and AI. But we’ve also noted that the biggest barrier is getting the right data in the right place and in the right format. So we’ve partnered with Informatica to enable organizations to achieve more success by enabling new ways to discover, ingest and prepare data for analytics.
Ingesting Data Directly Into Delta Lake
Getting high volumes of data from hybrid data sources into a data lake in a way that is reliable and high-performant is difficult. Datasets are often dumped in unmanaged data lakes with no thought of a purpose. Data is dumped into data lakes with no consistent format, making it impossible to mix reads and appends. Data can also be corrupted in the process of writing it to a data lake, as writes can fail and leave partial datasets.
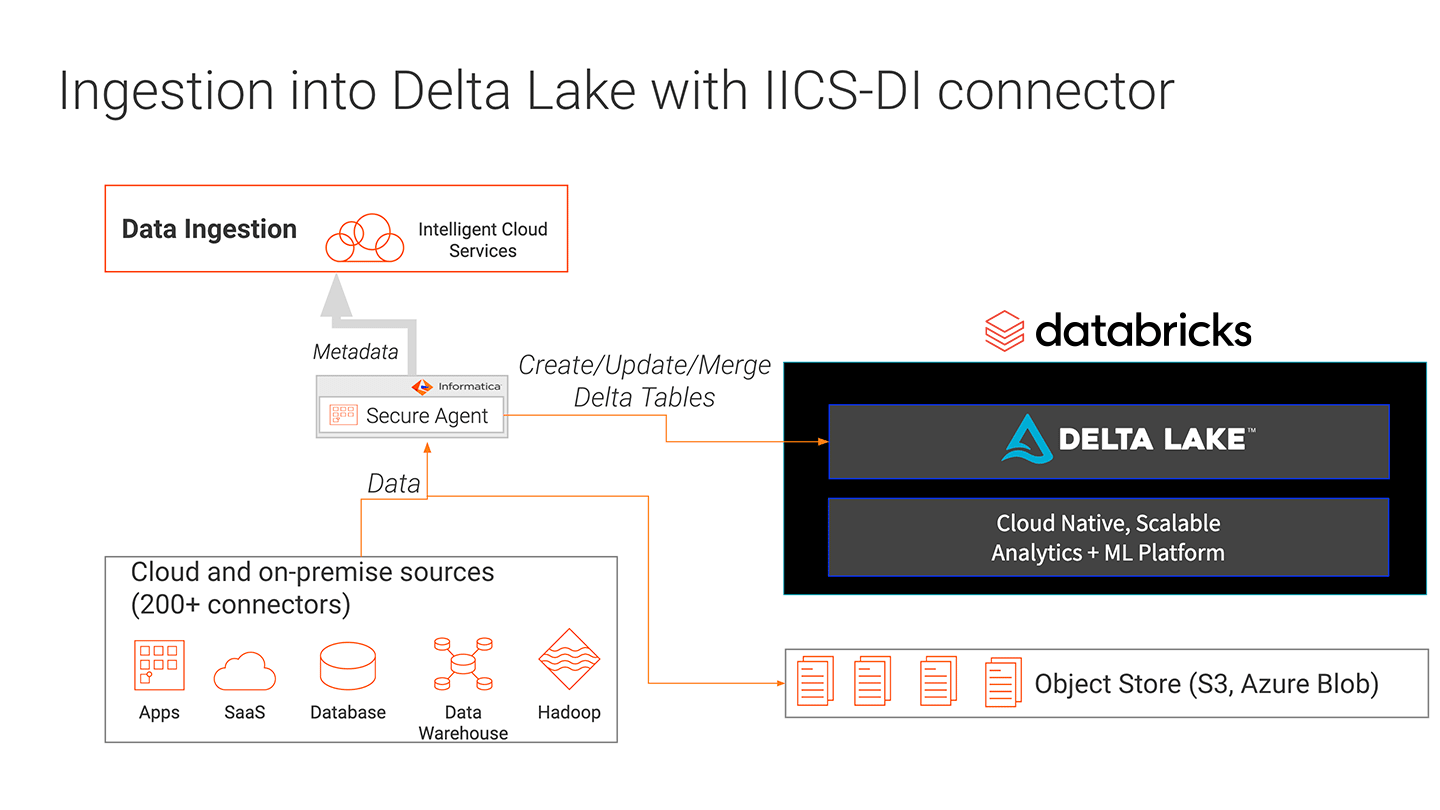
Informatica Data Engineering Integration (DEI) enables ingestion of data from multiple data sources. By integrating DEI with Delta Lake, ingestion can take place with the benefits of Delta Lake. ACID transactions ensure that writes are complete, or are backed out if they fail, leaving no artifacts. Delta Lake schema enforcement ensures that the data types are correct and required columns are present, preventing bad data from causing data corruption. The integration between Informatica DEI and Delta Lake enables data engineers to ingest data into a data lake with high reliability and performance.
Preparation
Every organization is limited in resources to format data for analytics. Ensuring the datasets can be used in ML models requires complex transformations that are time consuming to create. There are not enough highly skilled data engineers available to code advanced ETL transformations for data at scale. Furthermore, ETL code can be difficult to troubleshoot or modify.
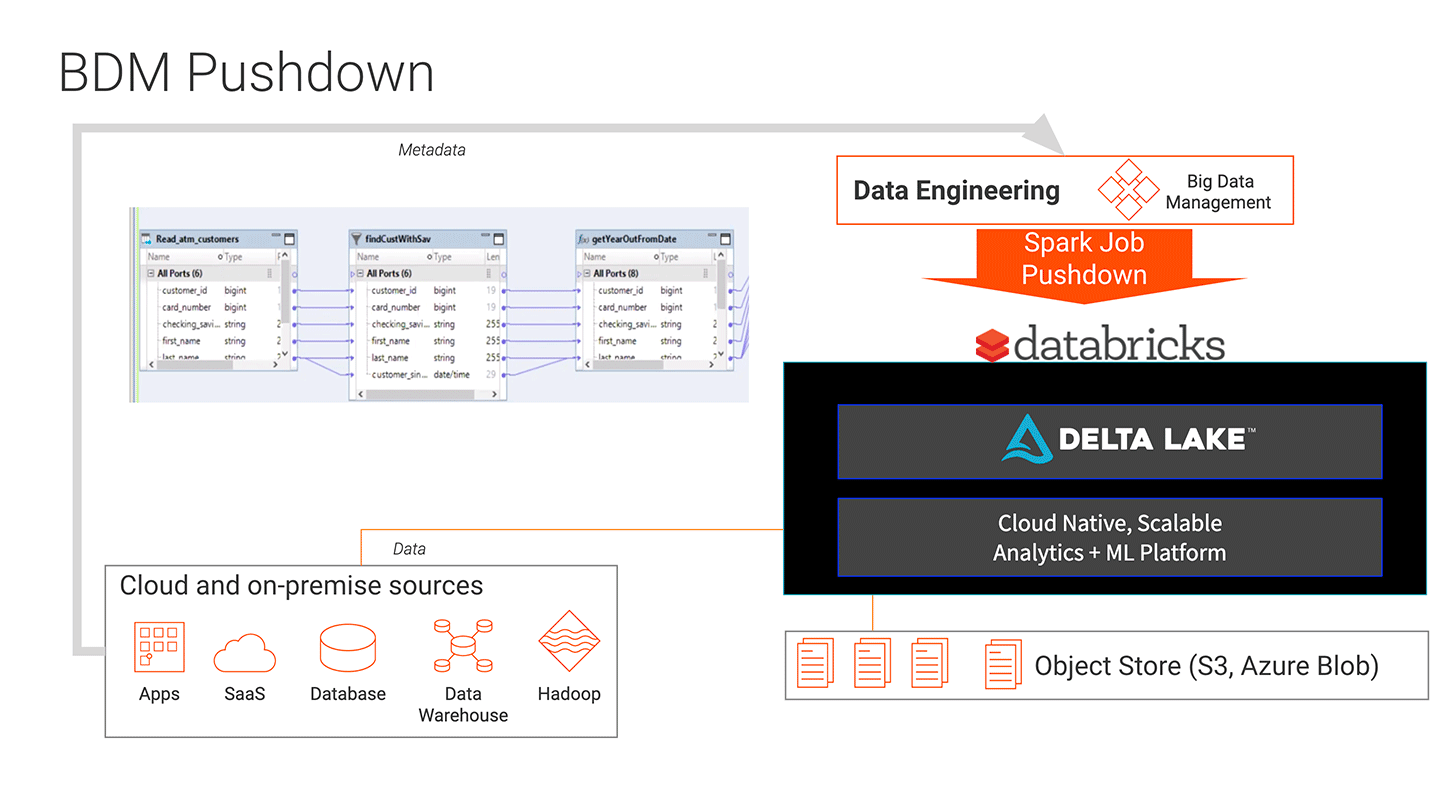
The integration of Informatica Big Data Management (BDM) and the Databricks Unified Analytics Platform makes it easier to create high-volume data pipelines for data at scale. The drag and drop interface of BDM lowers the bar for teams to create data transformations by removing the need to write code to create data pipelines. And the easy to maintain and modify pipelines of BDM can leverage the high volume scalability of Databricks by pushing that work down for processing. The result is faster and lower cost development of high-volume data pipelines for machine learning projects. Pipeline creation and deployment is increased 5x, and pipelines are easier to maintain and troubleshoot.
Discovery
Finding the right datasets for machine learning is difficult. Data scientists waste precious time looking for the right datasets for their models to help solve critical problems. They can’t identify which datasets are complete and properly formatted, and have been properly verified for usage as the correct datasets.
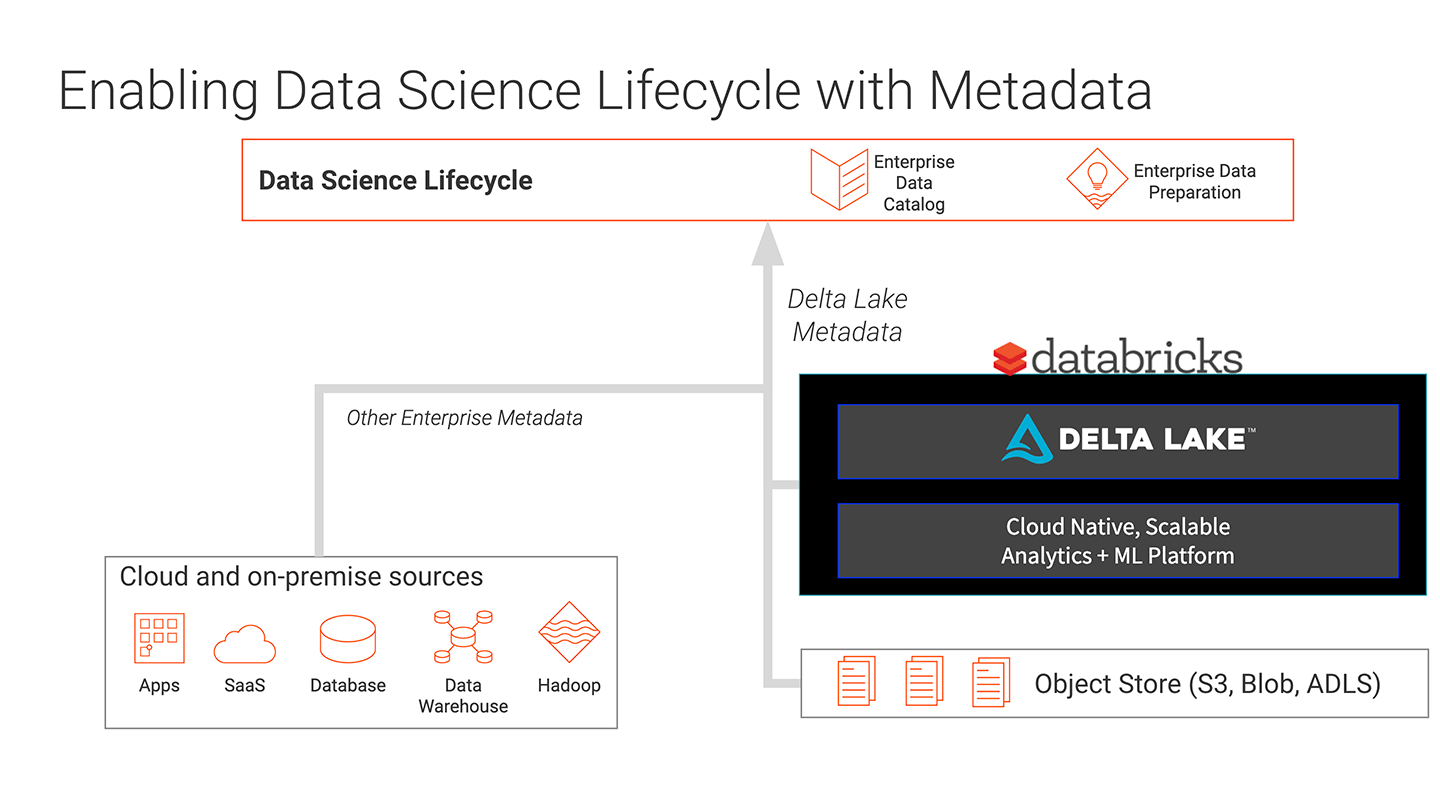
With the integration of Informatica Enterprise Data Catalog (EDC) with the Databricks Unified Analytics Platform, Data Scientists can now find the right data for creating models and performing analytics. Informatica’s CLAIRE engine uses AI and machine learning to automatically discover data and make intelligent recommendations for data scientists. Data scientists can find, validate, and provision their analytic models quickly, significantly reducing the time to value. Databricks can run ML models at unlimited scale to enable high-impact insights. And EDC can now track data in Delta Lake as well, making it part of the catalog of enterprise data.
Lineage
Tracing the lineage of data processing for analytics has been nearly impossible. Data Engineers and Data Scientists can’t provide any proof of lineage to show where the data came from. And when data is processed for creating models, identifying which version of a dataset, model, or even which analytics frameworks and libraries were used has become so complex it has moved beyond our capacity for manual tracking.
With the integration of Informatica EDC, along with Delta Lake and MLflow running inside of Databricks, Data Scientists can verify lineage of data from the source, track the exact version of data in the Delta Lake, and track and reproduce models, frameworks and libraries used to process the data for analytics. This ability to track Data Science decisions all the way back to the source provides a powerful way for organizations to be able to audit and reproduce results as needed to demonstrate compliance.
We are excited about these integrations and the impact they will have on making organizations successful, by enabling them to automate data pipelines and provide better insights into those pipelines. For more information, register for this webinar https://www.informatica.com/about-us/webinars/reg/keys-to-building-end-to-end-intelligent-data-pipelines-for-ai-and-ml-projects_358895.html.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.