Announcing Availability of MLflow 2.0

MLflow, with over 13 million monthly downloads, has become the standard platform for end-to-end MLOps, enabling teams of all sizes to track, share, package and deploy any model for batch or real-time inference. On Databricks, Managed MLflow provides a managed version of MLflow with enterprise-grade reliability and security at scale, as well as seamless integrations with the Databricks Machine Learning Runtime, Feature Store, and Serverless Real-Time Inference. Thousands of organizations are using MLflow on Databricks every day to power a wide variety of production machine learning applications.
Today, we are thrilled to announce the availability of MLflow 2.0! Building upon MLflow's strong platform foundation, MLflow 2.0 incorporates extensive user feedback to simplify data science workflows and deliver innovative, first-class tools for MLOps. Features and improvements include extensions to MLflow Recipes (formerly MLflow Pipelines) such as AutoML, hyperparameter tuning, and classification support, as well modernized integrations with the ML ecosystem, a streamlined MLflow Tracking UI, a refresh of core APIs across MLflow's platform components, and much more.
Accelerate model development with MLflow Recipes
MLflow Recipes enables data scientists to rapidly develop high-quality models and deploy them to production. With MLflow Recipes, you can get started quickly using predefined solution recipes for a variety of ML modeling tasks, iterate faster with the Recipes execution engine, and easily ship robust models to production by delivering modular, reviewable model code and configurations without any refactoring. MLflow 2.0 incorporates MLflow Recipes as a core platform component. It also makes several significant extensions, including support for classification models, improved data profiling and hyperparameter tuning capabilities.
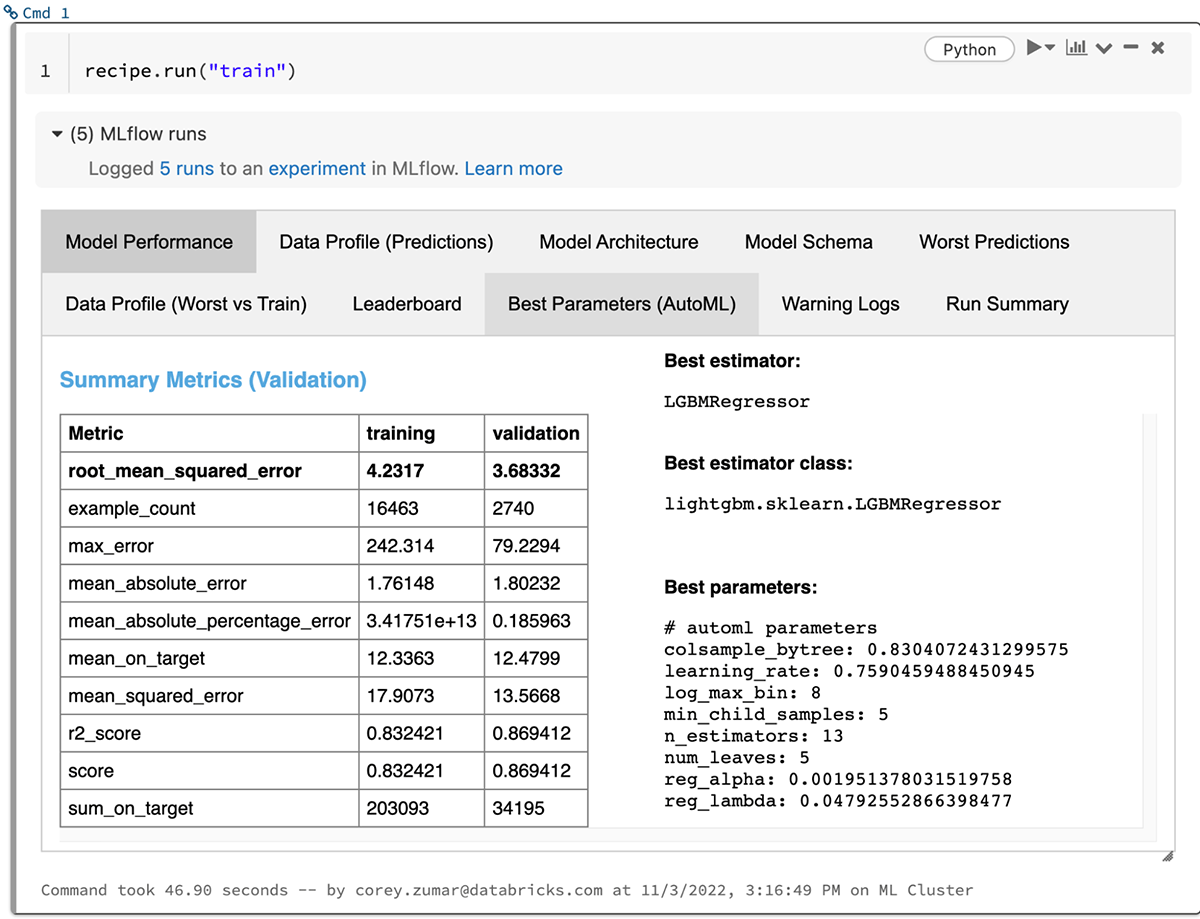
MLflow 2.0 also introduces AutoML to MLflow Recipes, dramatically reducing the amount of time required to produce a high-quality model. Simply specify a dataset and target column for your regression or classification task, and MLflow Recipes automatically explores a vast space of ML frameworks, architectures, and parameterizations to deliver an optimal model. Model parameters are made readily available for further tuning, and comprehensive results are logged to MLflow Tracking for reproducible reference and comparison.
To get started with MLflow Recipes, watch the demo video and check out the quickstart guide on mlflow.org.
MLflow Recipes is helping us standardize and automate our ML development workflow. With built-in visualization and experiment tracking integration, we have increased our experimentation velocity, accelerating the model development process. Integration with other teams has become easier, simplifying the path to deploy models. — Daniel Garcia Zapata, Data Scientist, CEMEX
Streamline your workflows with a refreshed MLflow core experience
In MLflow 2.0, we are excited to introduce a refresh of core platform APIs and the MLflow Tracking UI based on extensive feedback from MLflow users and Databricks customers. The simplified platform experience streamlines your data science and MLOps workflows, helping you reach production faster.
As you train and compare models, every MLflow Run you create now has a unique, memorable name to help you identify the best results. Later on, you can easily retrieve a group of MLflow runs by name or ID using expanded MLflow search filters, as well as search for experiments by name and by tags. When it comes time to deploy your models, MLflow 2.0's revamped model scoring API offers a richer request and response format for incorporating additional information such as prediction confidence intervals.
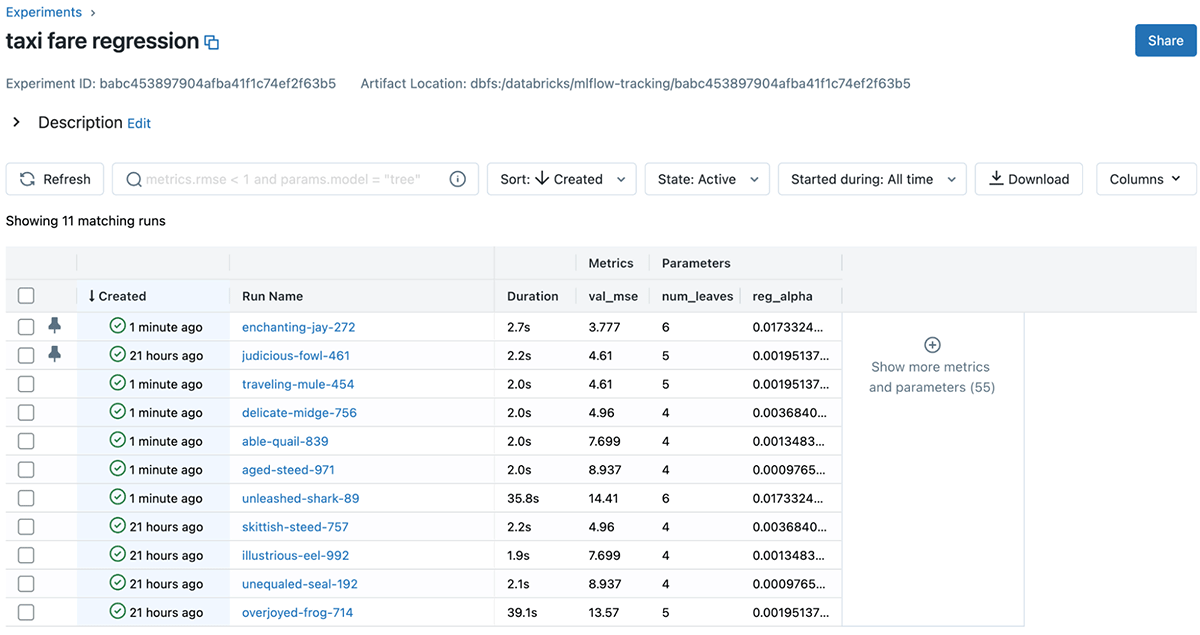
In addition to improving MLflow's core APIs, we have redesigned the experiment page for MLflow Tracking, distilling the most relevant model information and simplifying the search experience. The new experiment page also includes a Run pinning feature for easily keeping track of the best models as your experiments progress. The updated page is also available now on Databricks; simply click the Experiments icon in the sidebar and select one or more experiments to get started.
“With Databricks, we can now track different versions of experiments and simulations, package and share models across the organization; and deploy models quickly. As a result, we can iterate on predictive models at a much faster pace leading to more accurate forecasts.” — Johan Vallin, Global Head of Data Science at Electrolux
Your compact guide to modern analytics

Leverage the latest ML tools in any environment at scale
From day one, MLflow's open interface design philosophy has simplified end-to-end machine learning workflows while providing compatibility with the vast machine learning ecosystem, empowering all ML practitioners while using their preferred toolsets. With MLflow 2.0, we're doubling down on our commitment to delivering first-class support for the latest and greatest machine learning libraries and frameworks.
To this end, MLflow 2.0 includes a revamped integration with TensorFlow and Keras, unifying logging and scoring functionalities for both model types behind a common interface. The modernized mlflow.tensorflow module also offers a delightful experience for power users with TensorFlow Core APIs while maintaining simplicity for data scientists using Keras.
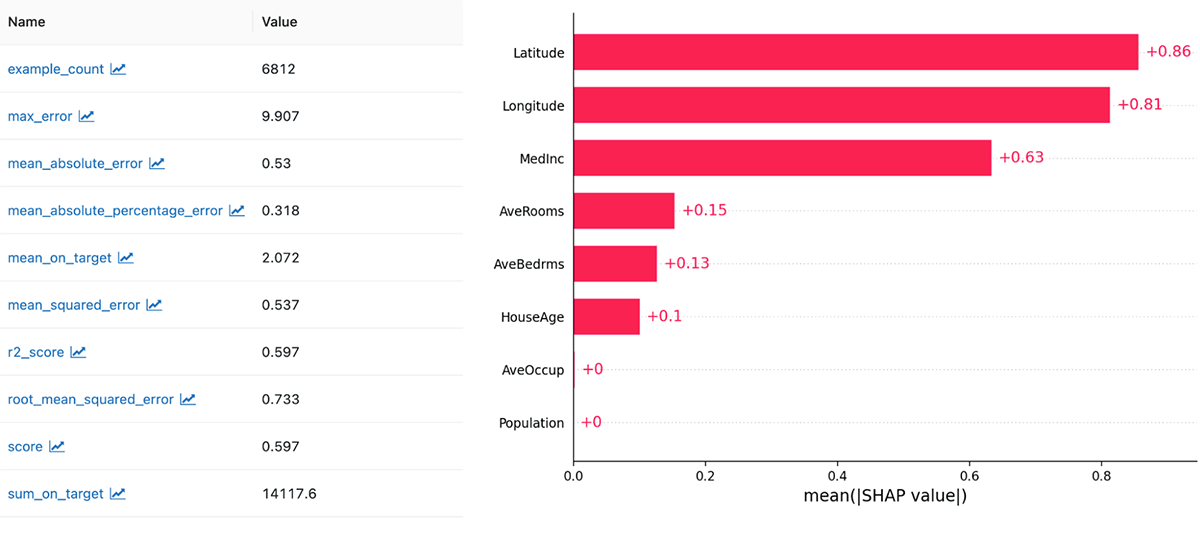
Additionally, in MLflow 2.0, the mlflow.evaluate() API for model evaluation is now stable and production-ready. With just a single line of code, mlflow.evaluate() creates a comprehensive performance report for any ML model. Simply specify a dataset and MLflow Model, and mlflow.evaluate() generates performance metrics, performance plots, and model explainability insights that are tailored to your modeling problem. You can also use mlflow.evaluate() to validate model performance against predefined thresholds and compare the performance of new models against a baseline, ensuring that your models meet production requirements. For more information about model evaluation, check out the "Model Evaluation in MLflow" blog post and the model evaluation documentation on mlflow.org.
“A lot of what we’re doing is around machine learning and AI. MLflow has been key to improving model lifecycle management and allows us to visualize the results and the outcomes from these models” — Anurag Sehgal, Managing Director, Head of Global Markets, Credit Suisse
Get started with Managed MLflow 2.0 on Databricks
We invite you to try out Managed MLflow 2.0 on Databricks! If you're an existing Databricks user, you can start using MLflow 2.0 today by installing the library in your notebook or cluster. MLflow 2.0 will also be preinstalled in version 12.0 of the Databricks Machine Learning Runtime. Visit the Databricks MLflow guide [AWS][Azure][GCP] to get started. If you're not yet a Databricks user, visit databricks.com/product/managed-mlflow to learn more and start a free trial of Databricks and Managed MLflow 2.0. For a complete list of new features and improvements in MLflow 2.0, see the release changelog.
Managed MLflow 2.0 is part of the Databricks platform for end-to-end production machine learning built on the open lakehouse architecture, which includes Feature Store and Serverless Real-time Inference. For more information about Databricks Machine Learning, visit databricks.com/product/machine-learning. To learn how to standardize and scale your MLOps workflows with Databricks Machine Learning, check out The Big Book of MLOps.
What's next
While we are excited about what you do with this new release of MLflow, we are continuing to work on additional improvements across the MLflow UI, including a brand new run comparison experience with improved visualizations. We will also deepen the integration between MLflow Tracking and the Databricks Lakehouse Platform. You can explore the roadmap here. We welcome your input and contributions.