Delta Live Tables Now Generally Available on Google Cloud

Today we are announcing the general availability of Delta Live Tables (DLT) on Google Cloud. DLT pipelines empower data engineers to build reliable, streaming and batch data pipelines effortlessly across their preferred cloud environments.
DLT provides a simplified framework for creating production-ready data pipelines to incrementally ingest, transform, and process data at scale.
Running data pipelines in production involves a lot of operational code to take care of activities like task orchestration, checkpointing, automatic restart on failure, performance optimization, data exception handling, and so on. This code is very complex to develop and time-consuming to maintain, leaving many data practitioners with limited bandwidth to focus on their core mission of transforming data to deliver new insights.
DLT addresses these challenges by providing a simple, declarative approach to data pipeline development while automating the complex operational components associated with running these pipelines reliably in production. DLT simplifies ETL development and operations, allowing analysts, data scientists, and data engineers to focus on delivering value from data.

BioIntelliSense has been one of our preview customers for Delta Live Tables on Google Cloud, with over 100 DLT pipelines in production. The BioIntelliSense Data-as-a-Service (DaaS) platform, and its continuous health monitoring and clinical intelligence solutions for in-hospital to home, rely on high-quality, tightly-governed data.
Dnyanesh Sonavane, Director of Data Engineering, summarizes the impact that DLT on Google Cloud has had for his organization:
Our Data Engineering team is focused on passive data collection through medical-grade wearable technology that results in high resolution data for our customers and our internal data science and analytics team. As we scale our business, data sources and data sets grow exponentially, making it more complicated to implement and maintain data transformation and lineage.
DLT has sped up our ELT / ETL pipeline development with declarative definitions reducing time for data delivery. The DAGs inferred by DLT, along with automated infrastructure management, empower data traceability making troubleshooting easy. — Dnyanesh Sonavane, Director of Data Engineering, BioIntelliSense
Simplified development for all data practitioners
DLT pipelines provide two powerful, but easy to use, primitives for data processing: streaming tables (STs) and materialized views (MVs).
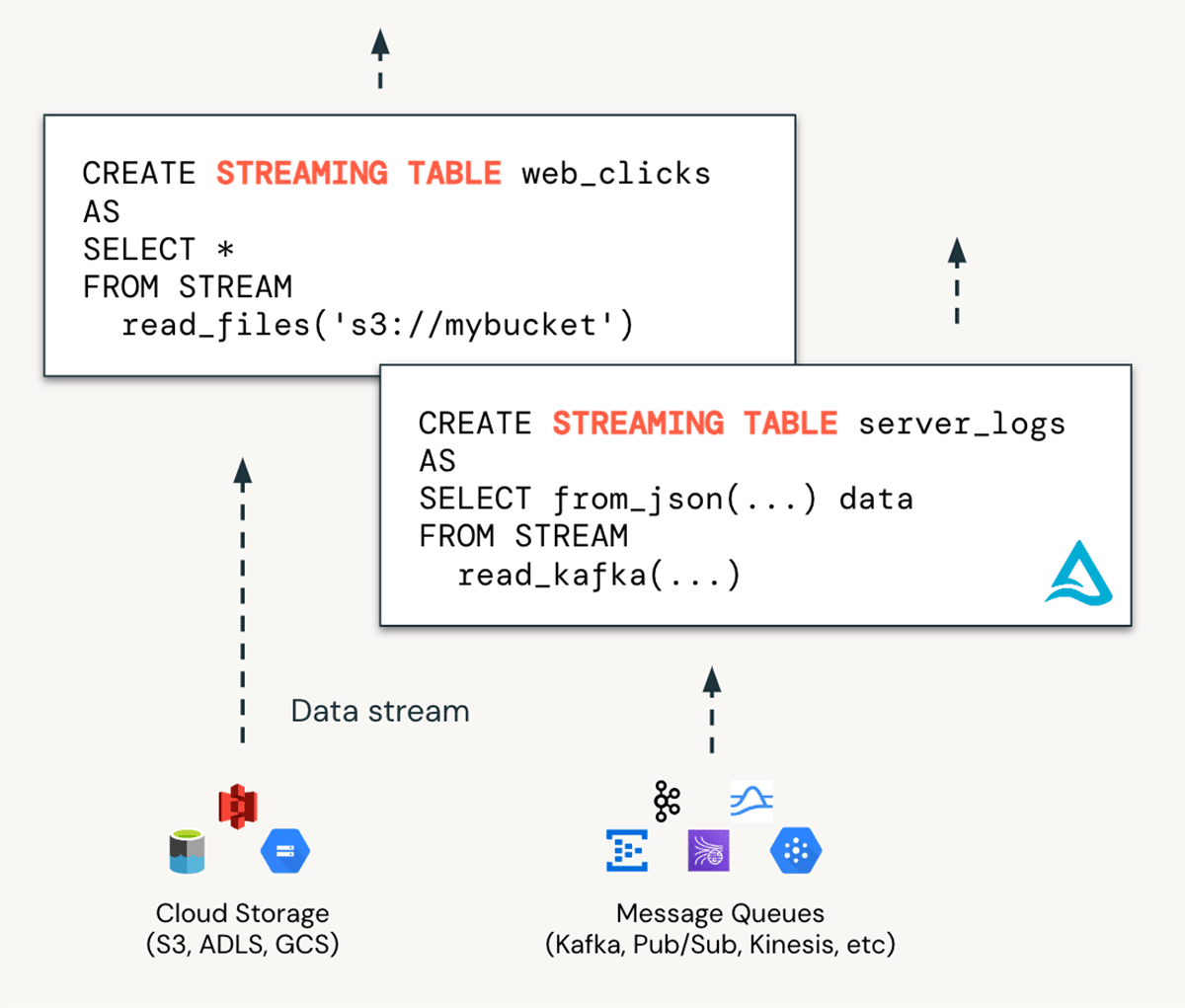
Streaming Tables are the ideal way to bring data into the "bronze" layer of your medallion architecture. With a single SQL statement or a few lines Python of code, users can scalably ingest data from various sources such as cloud storage (S3, ADLS, GCS), message buses (EventHub, Kafka, Kinesis), and more. This ingestion occurs incrementally, enabling low-latency and cost-effective pipelines, without the need for managing complex infrastructure.
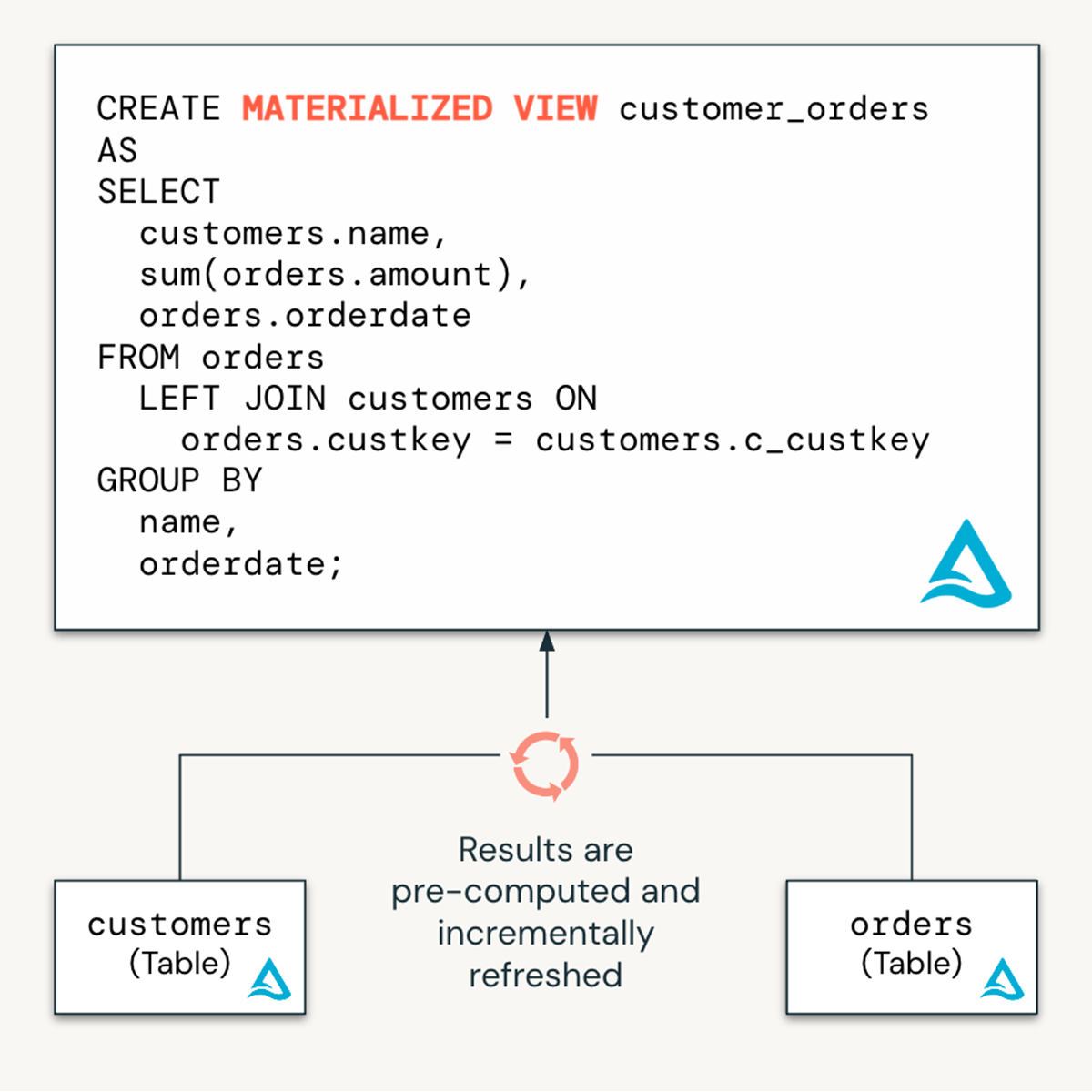
Materialized Views are ideal for transforming data in the "silver" and "gold" layers of your medallion architecture. With MVs, users can simply define a query and any aggregations or transformation, and MVs incrementally refresh to achieve low latencies.
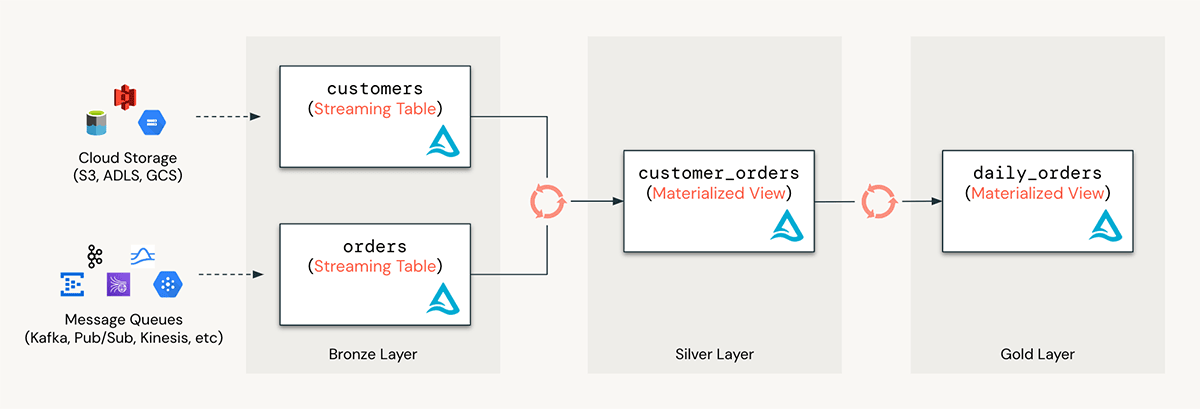
Automated framework for production data pipelines
DLT pipelines are a powerful automation framework that make it easy to define a series of STs and MVs and chain them together to form data processing pipelines. With DLT pipelines, a user can simply define the queries for STs and MVs, and DLT pipelines enable real-time understanding of dependencies and automate tasks such as orchestration, retries, recovery, auto-scaling, and performance optimization. This allows data engineers to treat their data as code and leverage modern software engineering best practices like testing, error-handling, monitoring, and documentation to deploy reliable pipelines at scale.
DLT pipelines also offer powerful features and APIs to manage data quality and advanced data modeling capabilities like change-data-capture and slowly-changing dimensions (SCD).
Why do customers pick DLT on Google Cloud?
Building and running DLT pipelines on Google Cloud has many advantages. Here are just a few:
- Familiar languages and APIs in Python and SQL for simple pipeline development
- Built-in support for both streaming and batch workloads
- Broad ecosystem of streaming connectors including Google Pub/Sub
- Automated error handling and restart, ensuring pipeline resilience and minimizing downtime
- Comprehensive testing and CI/CD capabilities to ensure high data quality and enable efficient deployment workflows
- Pipeline optimization, performance tuning, and autoscaling for enhanced efficiency and cost-effectiveness
- Data quality monitoring to proactively identify and address any issues affecting data integrity
By expanding the availability of DLT pipelines to Google Cloud, Databricks reinforces its commitment to providing a partner-friendly ecosystem while offering customers the flexibility to choose the cloud platform that best suits their needs. Whether you're on AWS, Azure, or Google Cloud, DLT empowers data engineers to accelerate ETL development, ensure high data quality, and unify batch and streaming workloads.
To learn more about Delta Live Tables, visit here or start your free trial today.
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read