
Data + AI Strategy
Organizations rush to democratize data and AI
Every company wants to take advantage of the transformative effects of GenAI initiatives. And they want to put the power of data intelligence into the hands of every employee. But with information trapped in silos and data management split across many different tools, teams often struggle to accelerate these projects.
The urgent question among business leaders now is: What’s the best and fastest way to democratize AI?
The State of Data + AI report provides a snapshot of how organizations are prioritizing data and AI initiatives. By analyzing anonymized usage data from the 10,000 customers who rely on the Databricks Data Intelligence Platform today, now including over 300 of the Fortune 500, we’re able to provide an unrivaled view into where companies are at on their efforts to accelerate the adoption of GenAI across their businesses — and the tools that are helping them do it.
Discover how the most innovative businesses are succeeding with machine learning, adopting GenAI and responding to changing governance needs. And learn how your own company can develop a data strategy fit for the evolving era of enterprise AI.
Here’s a summary of what we discovered:
AI Is in Production
11x more AI models were put into production
For years, companies have been experimenting with machine learning (ML), a critical component of AI. Many have faced challenges (data silos, complex deployment workflows, governance) in translating controlled ML experimentation to real-world applications in production. Now, we see evidence of increasing success. Across all organizations, 1,018% more models were registered for production this year compared to last year. In fact, for the first time in our research, the growth of models registered outpaced the growth of experiments logged, which still grew by 134%.
But each industry has different requirements and goals when it comes to ML. We analyzed six key industries to better understand these trends by looking at the ratio of logged-to-registered models. What did we find? Our three most efficient industries put 25% of their models into production.
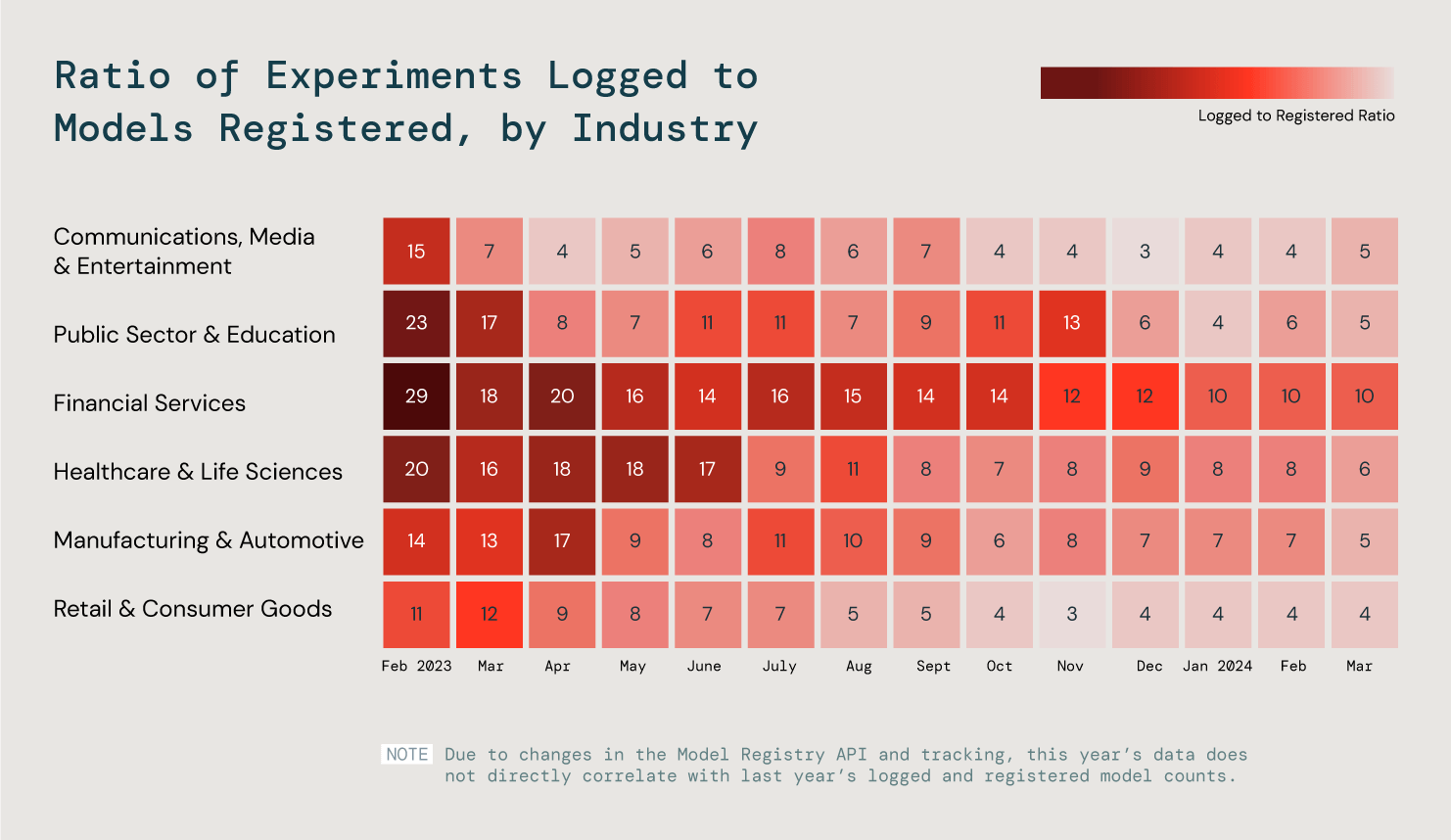
We analyzed the ratio of logged-to-registered models across all customers to assess ML production progress.
Production is where the true value of AI is realized, whether a product is for your internal teams or customers. We predict that the growing success in ML helps pave a path to greater success with building production-quality GenAI applications.
LLM Customization
Vector database usage grew 377%
As companies mature in their GenAI journeys, they’re increasingly looking to tailor existing LLMs — with their own private data — to their specific needs.
Retrieval augmented generation (RAG) is an important mechanism for businesses to get better performance from open source and closed LLMs. With RAG, a vector database is used to train the underlying models on private data to generate more accurate outputs that are hyper-relevant to a company’s unique operations.
And enterprises are aggressively pursuing this customization. The use of vector databases grew 377% in the last year.
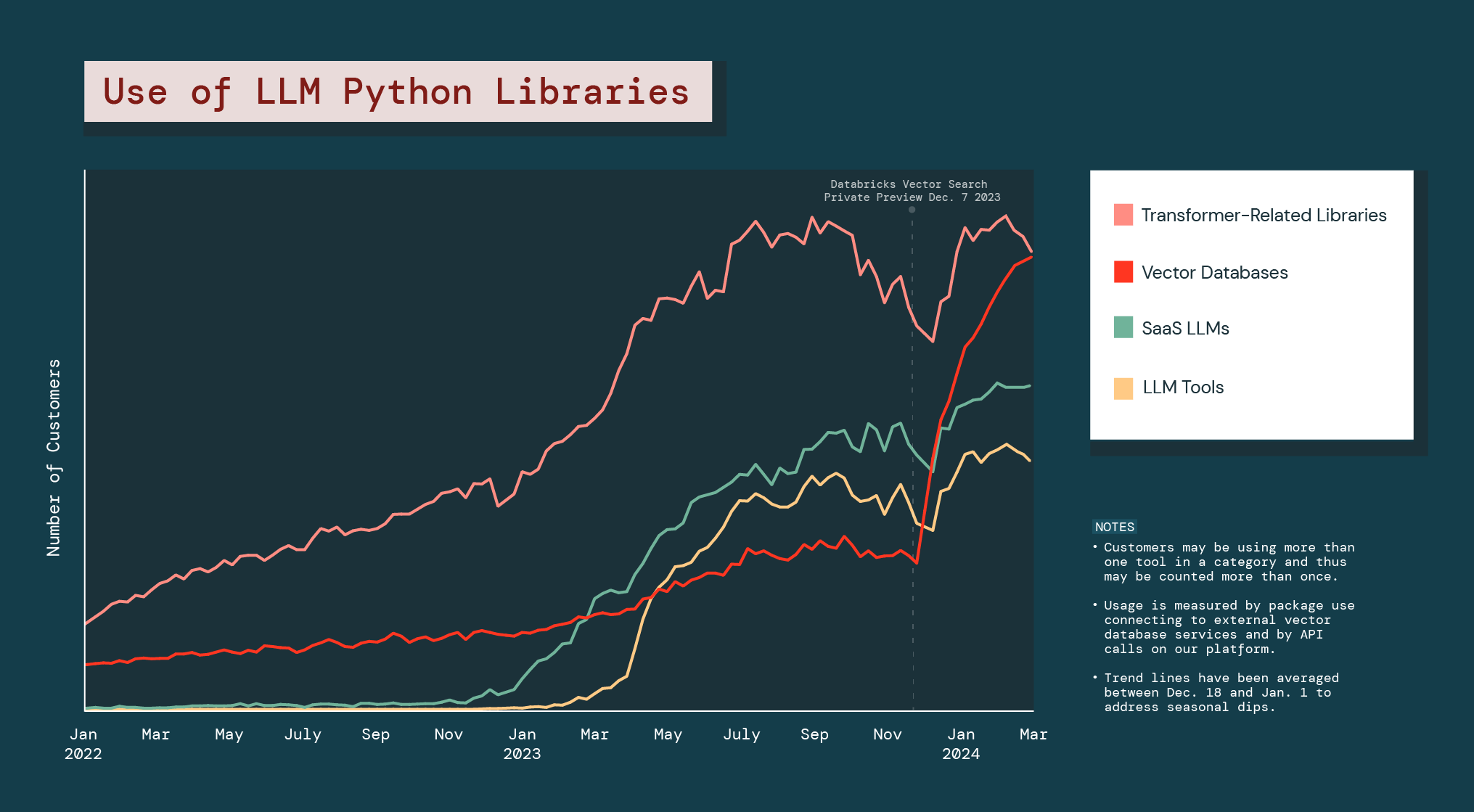
Since the Public Preview launch of Databricks Vector Search, the entire vector database category grew 186%, far more than any other LLM Python libraries.
The explosion of vector databases indicates that companies are looking for GenAI alternatives that can help with problems or drive opportunities specific to their business. And it suggests that enterprises will likely be relying on a mix of different types of GenAI models throughout their operations.
Open Source LLMs
Companies prefer small models
One of the biggest benefits of open source LLMs is the ability to customize them for specific use cases — especially in enterprise settings. In practice, customers often try many models and model families. We analyzed the open source model usage of Meta Llama and Mistral, the two biggest players.
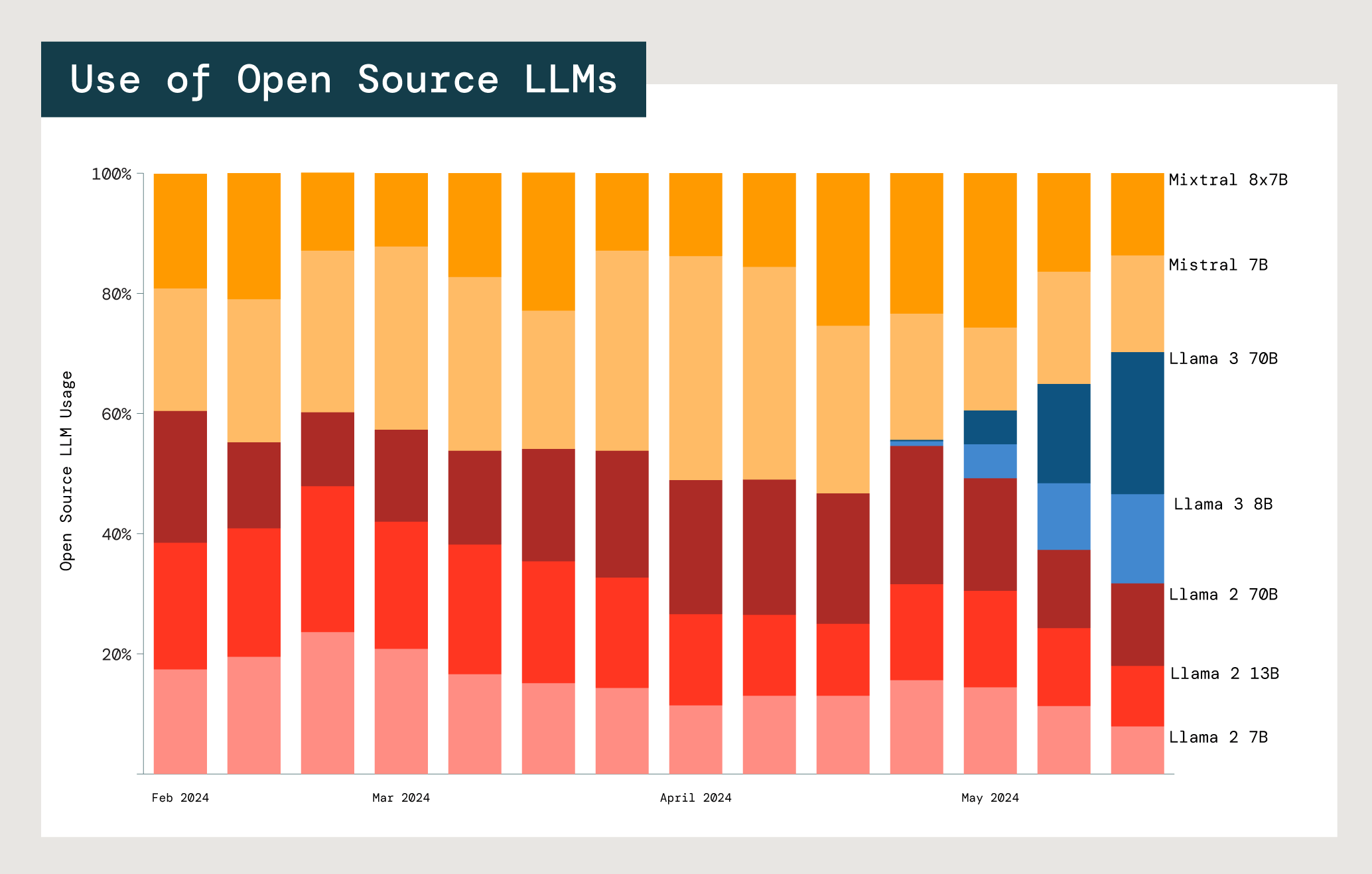
Relative adoption of Mistral and Meta Llama open source models in Databricks foundation model APIs.
With each model, there is a trade-off between cost, latency and performance. The usage of the two smallest Meta Llama 2 models (7B and 13B) is significantly higher than that of the largest, Meta Llama 2 70B. Across both Llama and Mistral users, 77% choose models that are 13B parameters or smaller. This suggests that companies are weighing the costs and benefits of model size when selecting the right model for a specific use case.
