TensorFlow™ on Databricks

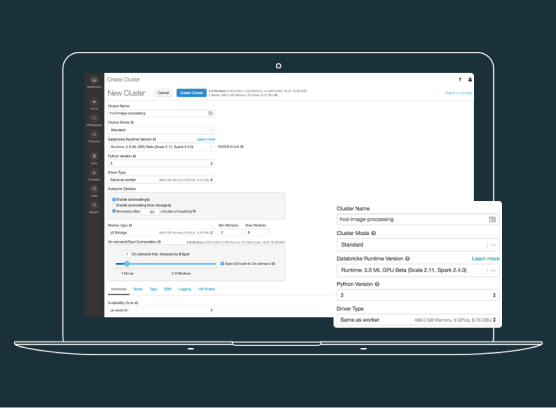
Ready-to-use TensorFlow
Get clusters up and running in seconds on both AWS and Azure CPU and GPU instances for maximum flexibility.
Get started quickly with out-of-the-box integration of TensorFlow, Keras, and their dependencies with the Databricks Runtime for Machine Learning.
Benefit from a range of low-level and high-level APIs to train cutting-edge neural networks using TensorFlow, Keras, and Apache Spark.
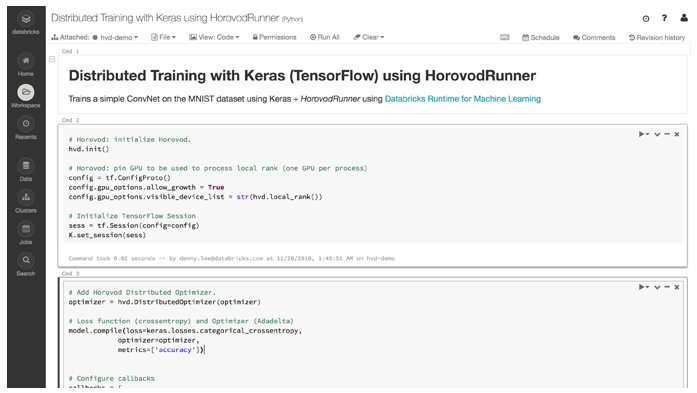
Scale-out computation
Easily scale-out computation in a distributed fashion with the new Databricks HorovodRunner.
Benefit from accelerated hardware support (CUDA and cuDNN) for greater performances on the most demanding jobs.
Automatically scale resources based on your needs, and keep costs under control by separating storage from compute resources.
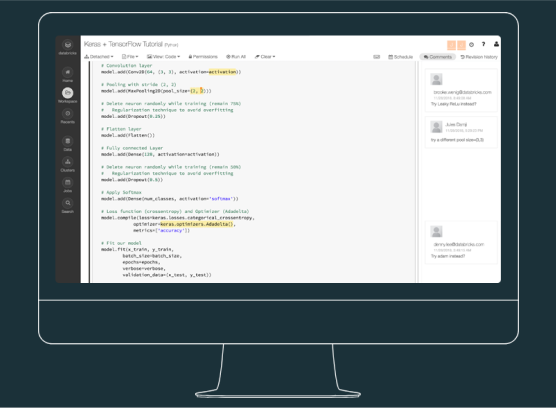
End-to-end collaborative experience
Easily access, explore, and prepare high-quality data sets, in batch or real-time, and at massive scale with Machine learning.
Share notebooks and keep track of changes with version history and Github integration, using Python, R, Scala or Java.
Share, run, and keep track of experiments locally or in the cloud, and deploy models on any platform with MLflow.