Security & Trust Center
Your data security is our top priority

Databricks’ Approach to Responsible AI
Databricks believes that the advancement of AI relies on building trust in intelligent applications by following responsible practices in the development and use of AI. This requires that every organization has ownership and control over their data and AI models with comprehensive monitoring, privacy controls and governance throughout the AI development and deployment.
Databricks and the EU AI Act
Databricks is committed to responsible AI development and deployment consistent with applicable laws, including laws such as the European Union Artificial Intelligence Act (EU AI Act).
Databricks is an AI system provider and downstream model distributor for third-party general purpose AI models. We are responsible for our assessments of the AI systems we provide directly. We do not place general-purpose AI foundation models on the market as an upstream provider in the AI value chain. Where Databricks integrates third-party foundation models downstream into our services, or offer models downstream of model providers, those models remain subject to the obligations applicable to their respective model providers under the EU AI Act. The upstream model providers are responsible for compliance with applicable laws and regulations.
Databricks services are use-case agnostic and data agnostic. They are not placed on the market for specific high-risk use cases.
Customers are responsible for assessing whether their intended use of Databricks AI systems, or models through Databricks, constitute high-risk AI uses under the EU AI Act, and for complying with applicable obligations in connection with such uses.
Databricks supports customers’ compliance efforts through:
- Platform-level governance controls;
- Security and monitoring capabilities; and
- Documentation describing use and functionality.
Databricks continues to monitor EU AI Act implementation guidance and harmonised standards and will update its governance approach as appropriate.
Databricks’ Responsible AI Testing Framework — Red Teaming GenAI Models
AI red teaming, especially for large language models, is an important component of developing and deploying models safely. Databricks employs regular AI red teaming of models and systems developed internally. An overview of our Responsible AI Testing Framework is included below, featuring the techniques that we use internally in our Adversarial ML Lab to test our models, as well as additional red teaming techniques that we are evaluating for future use in our Lab.
NOTE: It is crucial to acknowledge that the field of AI red teaming is still in its early stages, and the rapid pace of innovation brings both opportunities and challenges. We are committed to ongoing evaluation of new approaches for attacks and counterattacks and bringing these into the testing process for our models where appropriate.
Here is the diagrammatic representation of our GenAI Testing Framework:
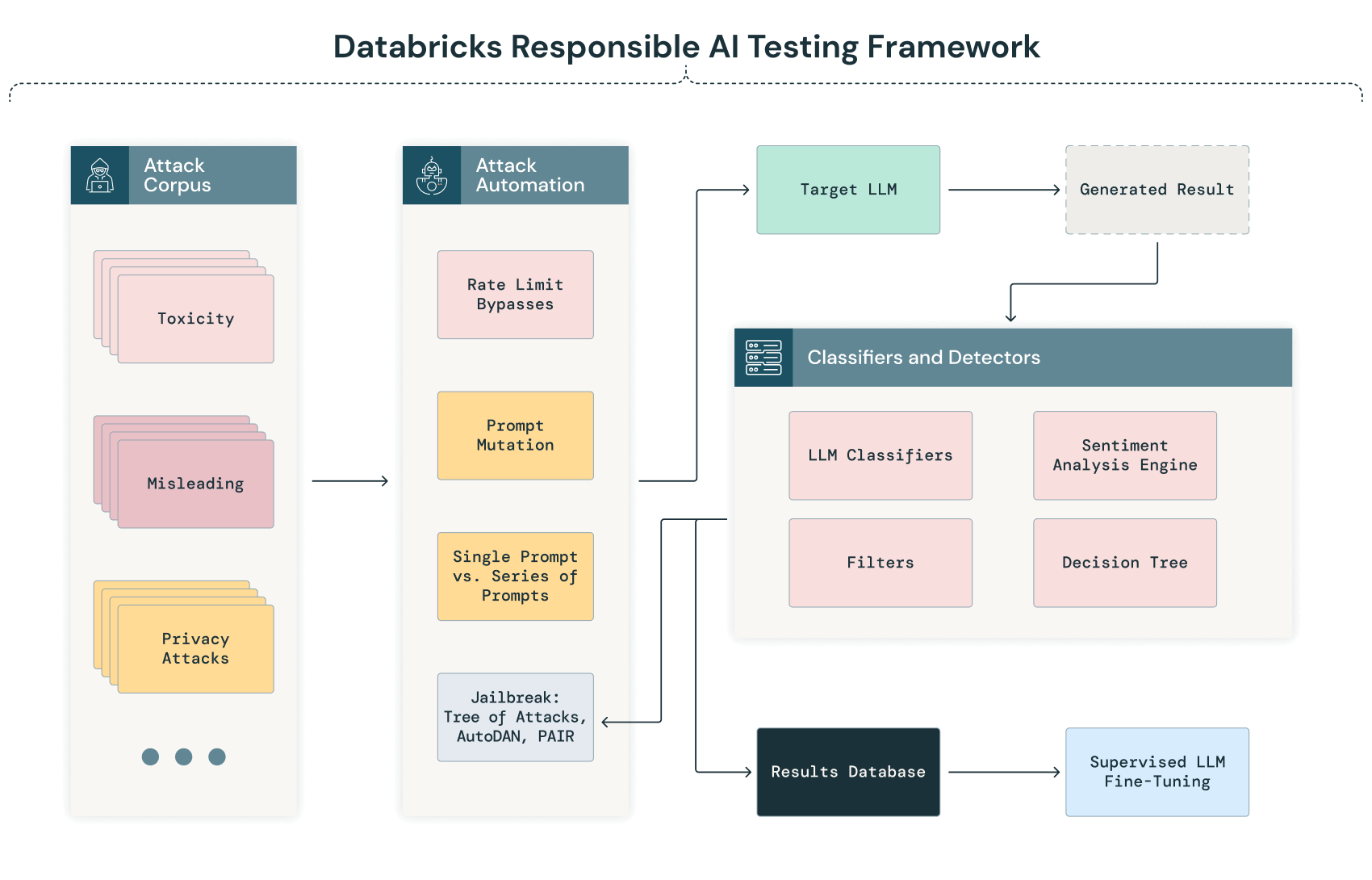
Automated probing and classification
The initial phase of our AI red teaming process involves an automated process where a series of diverse text corpora are systematically sent to the model. This process aims to probe the model’s responses across a wide range of scenarios, identifying potential vulnerabilities, biases or privacy concerns automatically before a deeper, manual analysis is conducted.
As the LLM processes these inputs, its outputs are automatically captured and classified using predefined criteria. This classification might involve natural language processing (NLP) techniques and other AI models trained to detect anomalies, biases or deviations from expected performance. For instance, an output might be flagged for manual review if it exhibits potential bias, nonsensical responses or signs of data leakage.
Jailbreaking LLMs
Databricks employs multiple techniques for jailbreaking LLMs, including:
- Direct Instructions (DI): Direct prompts by the attacker to ask for harmful content.
- Do-Anything-Now Prompts (DAN): A variety of attacks encouraging the model to become a “Do Anything Now” chat agent able to facilitate any task regardless of the ethical or security boundaries.
- Riley Goodside Style Attacks: A sequence of attacks asking the model directly to ignore its prompting. This was popularized by Riley Goodside.
- Agency Enterprise PromptInject Corpus: Replay of the Agency Enterprise Prompt Injection corpus, from the best paper awards at NeurIPS ML Safety Workshop 2022.
- Prompt Automatic Iterative Refinement (PAIR): An attack-focused large language model is used to refine the prompt iteratively guiding it toward a jailbreak.
- Tree of Attacks With Pruning (TAP): Similar to a PAIR attack, however, an additional LLM is used to identify when the generated prompts run off-topic and prune them from the attack tree.
Jailbreak testing provides an additional understanding of the model’s ability to generalize and respond to prompts that are significantly different from the training data or have an alternate way of reaching protected information. This also allows us to identify ways by which an attack can trick LLMs into outputting harmful or otherwise unwanted content.
Given that this is an ever-evolving field, we will continue to consider and evaluate additional techniques as the landscape changes for jailbreaking.
Manual validation and analysis
Following the automated phase, the AI red teaming process involves a manual review of the flagged outputs and — to increase the likelihood that all critical issues are identified — a random review of unflagged outputs. This manual analysis allows for nuanced interpretation and validation of the issues identified through the automated process.
The AI red teaming process involves a significant amount of manual work where the automated scans may generate results that don’t show concerns, but the manual assessment by the Red Team may attempt variants where these prompts can be tweaked or chained together to find weaknesses otherwise not identified by the automated scans.
Model supply chain security
As our AI red teaming efforts continue to evolve, we also include processes to assess the security of the AI model supply chain from training through deployment and distribution. Current areas under assessment include:
- Compromising training data (poisoning by label tampering or injecting malicious data)
- Compromising the training infrastructure (GPU, VM, etc.)
- Gaining access to the deployed LLMs to tamper with weights and hyperparameters
- Tampering with filters and other deployed defensive layers
- Compromising the model distribution — such as through a compromise of trusted third parties like Hugging Face.
Ongoing feedback loop
An additional area for our AI red teaming efforts will be a process for an ongoing improvement loop, which would capture insights gained from both automated scans and manual analyses. Our goal for the ongoing improvement loop is to further the evolution of our models to become more robust and aligned with the highest performance standards.
Categories of Test Probes Utilized by the Databricks Red Team
Databricks utilizes a series of curated corpora (probes) that are sent to the model during testing. Probes are specific tests or experiments designed to challenge the AI system in various ways. For any probe that generates a successful non-violating result, the Red Team would test for misbehavior in the model response by attempting other variants of the same probe. In the context of LLMs, the probes utilized by the Databricks Red Team can be categorized as follows:
Security Probes
- Input Manipulation: Testing the model’s response to altered, noisy or malicious inputs to identify vulnerabilities in data processing.
- Evasion Techniques: Trying to bypass the model’s safeguards or filters to induce harmful or unintended outputs.
- Model Inversion: Attempts to extract sensitive information from the model, compromising data privacy.
Ethical and Bias Probes
- Bias Detection: Evaluating the model for biases related to race, gender, age, etc., by analyzing its responses to specific prompts.
- Ethical Dilemmas: Presenting the model with scenarios that test its alignment with ethical norms and values.
Robustness and Reliability Probes
- Adversarial Attacks: Introducing slightly modified inputs that are designed to deceive the model and lead to incorrect outputs.
- Consistency Checks: Testing the model’s ability to provide consistent and reliable responses across similar or repeated queries.
Compliance and Safety Probes
- Regulatory Compliance: Testing the model’s outputs and processes against applicable regulations.
- Safety Scenarios: Assessing the model’s behavior in scenarios where safety is a critical concern — to avoid harm or dangerous advice.
- Privacy Probes: Examining the model against data privacy standards and regulations, such as GDPR or HIPAA. These probes assess whether the model improperly reveals personal or sensitive information in its outputs or if it could be manipulated to extract such data.
- Controllability: Testing the ease with which human operators can intervene or control the model’s outputs and behaviors.


