Databricks Lakehouse and Data Mesh, Part 1

This is the first blog in a two-part series. In this post we will introduce the data mesh concept and the Databricks capabilities available to implement a data mesh. The second blog will examine different data mesh options and provide details on implementing a data mesh based on the Databricks Lakehouse.
Data mesh is a paradigm that describes a set of principles and logical architecture for scaling data analytics platforms. The purpose is to derive more value from data as an asset at scale. The phrase 'data mesh' was introduced by Zhamak Dehghani in 2019 and expanded on in her 2020 article Data Mesh Principles and Logical Architecture.
At the core of the data mesh logical architecture are four principles:
- Domain ownership: adopting a distributed architecture where domain teams - data producers - retain full responsibility for their data throughout its lifecycle, from capture through curation to analysis and reuse
- Data as a product: applying product management principles to the data analytics lifecycle, ensuring quality data is provided to data consumers who may be within and beyond the producer's domain
- Self-service infrastructure platform: taking a domain-agnostic approach to the data analytics lifecycle, using common tools and methods to build, run, and maintain interoperable data products
- Federated governance: ensuring a data ecosystem that adheres to organizational rules and industry regulations through standardization
Data products are an important concept for the data mesh. They are not meant to be datasets alone but data treated like a product: they need to be discoverable, trustworthy, self-describing, addressable and interoperable. Besides data and metadata, they can contain code, dashboards, features, models, and other resources needed to create and maintain the data product.
Many customers ask, 'Can we create a data mesh with Databricks Lakehouse?' The answer is yes! Several of Databricks' largest customers worldwide have adopted data mesh using the Lakehouse as the technological foundation.
Databricks Lakehouse is a cloud-native data, analytics and AI platform that combines the performance and features of a data warehouse with the low-cost, flexibility and scalability of a modern data lake. For an introduction, please read What is a Lakehouse?
The lakehouse addresses a fundamental concern with data lakes that led to the principles of a data mesh – that a monolithic data lake can become an unmanageable data swamp. The Databricks Lakehouse is an open architecture that offers flexibility in how data is organized and structured, whilst providing a unified management infrastructure across all data and analytics workloads.
The primary unit of organization within the Databricks Lakehouse platform that maps to the concept of domains in a data mesh is the 'workspace'. A Databricks Lakehouse can have one or more workspaces, with each workspace enabling local data ownership and access control.
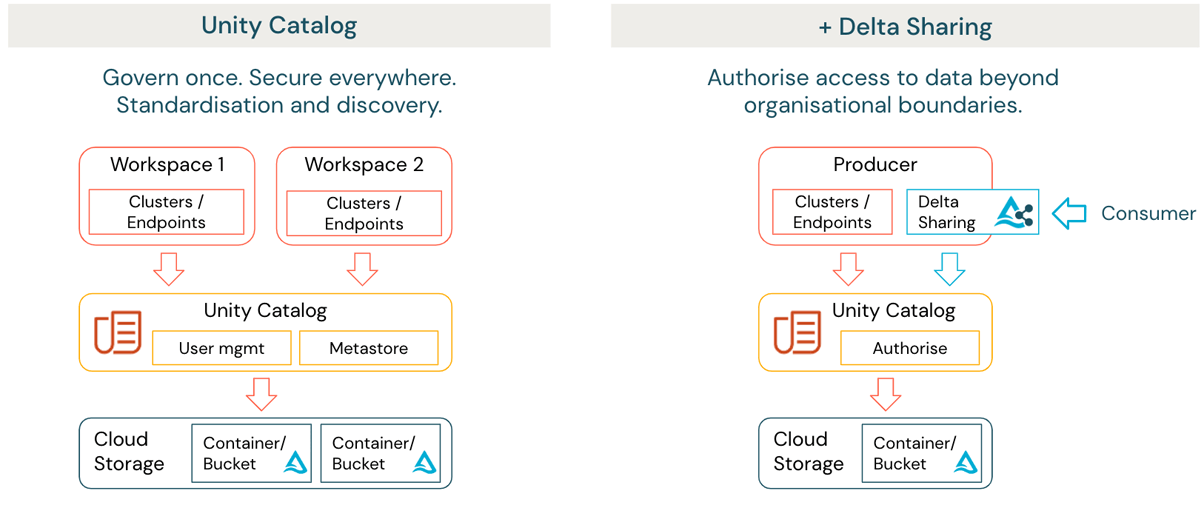
Each workspace encapsulates one or more domains, serves as the home for collaboration and enables the domain/s to manage its data products using a common self-serviced domain-agnostic infrastructure. This can include automation in provisioning of the environment and orchestration of data pipelines using built in services such as Databricks Workflows, and deployment automation using the Databricks Terraform provider. Unity Catalog provides federated governance, discovery and lineage as a centralized service at the organization's account level running Databricks. (figure 1 left side).
For many organizations, there is a need to consider how data can be securely shared with external parties beyond a governance boundary. This can also apply to internal domains hosted on different cloud providers and regions. Databricks Lakehouse provides a solution in the form of Delta Sharing (figure 1 right side). Delta Sharing enables organizations to securely share data with external parties regardless of computing platform. The data does not need to be duplicated and access is automatically audited and logged.
Delta Sharing also provides the foundation for a broader range of external data sharing activities. This includes publishing or acquiring data via a data marketplace such as the Databricks Marketplace, and securely collaborating on data across organizational and technical boundaries, enabled within the Databricks platform as Databricks Cleanrooms.
The combination of Unity Catalog and Delta Sharing means that the Databricks Lakehouse platform offers flexibility in how an organization chooses to organize and manage data and analytics at scale, including deployments that span multiple cloud providers, different geographic regions, and deployments that require the ability to share data assets with external entities. With Databricks Lakehouse, data can be organized in a data mesh, but can also be organized using any appropriate architecture, from fully centralized to fully distributed.
The second part of this blog post will examine different data mesh options and provide details on how to implement a data mesh based on the Databricks Lakehouse.
To find out more about the capabilities of the Databricks Lakehouse mentioned in this post:
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read